这篇文章主要讲解了“Hadoop的生态系统是什么”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Hadoop的生态系统是什么”吧!
hadoop生态系统,意思就是以hadoop为平台的各种应用框架,相互兼容,组成了一个独立的应用体系,也可以称之为生态圈。
通过以下的图:
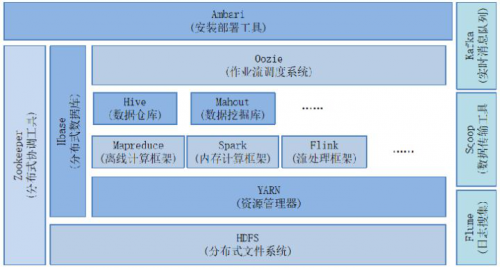
hadoop生态系统
我们可以可以总结如下常用的应用框架(图中没有的,我也列出了几个):
1,HDFS(hadoop分布式文件系统)
是hadoop体系中数据存储管理的基础。他是一个高度容错的系统,能检测和应对硬件故障。
client:切分文件,访问HDFS,与那么弄得交互,获取文件位置信息,与DataNode交互,读取和写入数据。
namenode:master节点,在hadoop1.x中只有一个,管理HDFS的名称空间和数据块映射信息,配置副本策略,处理客户 端请求。
DataNode:slave节点,存储实际的数据,汇报存储信息给namenode。
secondary namenode:辅助namenode,分担其工作量:定期合并fsimage和fsedits,推送给namenode;紧急情况下和辅助恢复namenode,但其并非namenode的热备。
2,mapreduce(分布式计算框架)
mapreduce是一种计算模型,用于处理大数据量的计算。其中map对应数据集上的独立元素进行指定的操作,生成键-值对形式中间,reduce则对中间结果中相同的键的所有值进行规约,以得到最终结果。
jobtracker:master节点,只有一个,管理所有作业,任务/作业的监控,错误处理等,将任务分解成一系列任务,并分派给tasktracker。
tacktracker:slave节点,运行 map task和reducetask;并与jobtracker交互,汇报任务状态。
map task:解析每条数据记录,传递给用户编写的map()并执行,将输出结果写入到本地磁盘(如果为map—only作业,则直接写入HDFS)。
reduce task:从map 它深刻地执行结果中,远程读取输入数据,对数据进行排序,将数据分组传递给用户编写的reduce函数执行。
3, hive(基于hadoop的数据仓库)
由Facebook开源,最初用于解决海量结构化的日志数据统计问题。
hive定于了一种类似sql的查询语言(hql)将sql转化为mapreduce任务在hadoop上执行。
4,hbase(分布式列存数据库)
hbase是一个针对结构化数据的可伸缩,高可靠,高性能,分布式和面向列的动态模式数据库。和传统关系型数据库不同,hbase采用了bigtable的数据模型:增强了稀疏排序映射表(key/value)。其中,键由行关键字,列关键字和时间戳构成,hbase提供了对大规模数据的随机,实时读写访问,同时,hbase中保存的数据可以使用mapreduce来处理,它将数据存储和并行计算完美结合在一起。
5,zookeeper(分布式协作服务)
解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
6,sqoop(数据同步工具)
sqoop是sql-to-hadoop的缩写,主要用于传统数据库和hadoop之间传输数据。数据的导入和导出本质上是mapreduce程序,充分利用了MR的并行化和容错性。
7,pig(基于hadoop的数据流系统)
定义了一种数据流语言-pig latin,将脚本转换为mapreduce任务在hadoop上执行。通常用于离线分析。
8,mahout(数据挖掘算法库)
mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建只能应用程序。mahout现在已经包含了聚类,分类,推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。除了算法是,mahout还包含了数据的输入/输出工具,与其他存储系统(如数据库,mongoDB或Cassandra)集成等数据挖掘支持架构。
9,flume(日志收集工具)
cloudera开源的日志收集系统,具有分布式,高可靠,高容错,易于定制和扩展的特点。他将数据从产生,传输,处理并写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在flume中定制数据发送方,从而支持收集各种不同协议数据。
10,资源管理器的简单介绍(YARN和mesos)
随着互联网的高速发展,基于数据 密集型应用 的计算框架不断出现,从支持离线处理的mapreduce,到支持在线处理的storm,从迭代式计算框架到 流式处理框架s4,...,在大部分互联网公司中,这几种框架可能都会采用,比如对于搜索引擎公司,可能的技术方法如下:网页建索引采用mapreduce框架,自然语言处理/数据挖掘采用spark,对性能要求到的数据挖掘算法用mpi等。公司一般将所有的这些框架部署到一个公共的集群中,让它们共享集群的资源,并对资源进行统一使用,这样便诞生了资源统一管理与调度平台,典型的代表是mesos和yarn。
11,其他的一些开源组件:
1)cloudrea impala:
一个开源的查询引擎。与hive相同的元数据,SQL语法,ODBC驱动程序和用户接口,可以直接在HDFS上提供快速,交互式SQL查询。impala不再使用缓慢的hive+mapreduce批处理,而是通过与商用并行关系数据库中类似的分布式查询引擎。可以直接从HDFS或者Hbase中用select,join和统计函数查询数据,从而大大降低延迟。
2)spark:
spark是个开源的数据 分析集群计算框架,最初由加州大学伯克利分校AMPLab,建立于HDFS之上。spark与hadoop一样,用于构建大规模,延迟低的数据分析应用。spark采用Scala语言实现,使用Scala作为应用框架。
spark采用基于内存的分布式数据集,优化了迭代式的工作负载以及交互式查询。
与hadoop不同的是,spark与Scala紧密集成,Scala象管理本地collective对象那样管理分布式数据集。spark支持分布式数据集上的迭代式任务,实际上可以在hadoop文件系统上与hadoop一起运行(通过YARN,MESOS等实现)。
3)storm
storm是一个分布式的,容错的计算系统,storm属于流处理平台,多用于实时计算并更新数据库。storm也可被用于“连续计算”,对数据流做连续查询,在计算时将结果一流的形式输出给用户。他还可被用于“分布式RPC”,以并行的方式运行昂贵的运算。
4)kafka
kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息
感谢各位的阅读,以上就是“Hadoop的生态系统是什么”的内容了,经过本文的学习后,相信大家对Hadoop的生态系统是什么这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:http://blog.itpub.net/69913864/viewspace-2694843/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



