小编给大家分享一下Java中HashSet原理及常用方法的示例分析,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
一. HashSet概述
HashSet是Java集合Set的一个实现类,Set是一个接口,其实现类除HashSet之外,还有TreeSet,并继承了Collection,HashSet集合很常用,同时也是程序员面试时经常会被问到的知识点,下面是结构图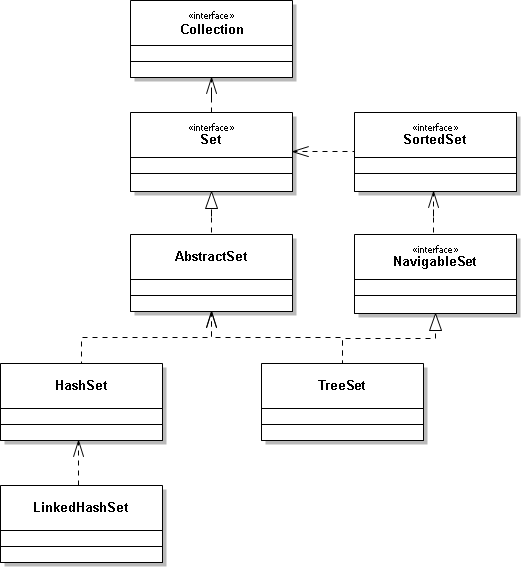
public class HashSetextends AbstractSetimplements Set, Cloneable, java.io.Serializable
{}二. HashSet构造
HashSet有几个重载的构造方法,我们来看一下
private transient HashMapmap;
//默认构造器
public HashSet() {
map = new HashMap<>();
}
//将传入的集合添加到HashSet的构造器
public HashSet(Collection< ? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
//明确初始容量和装载因子的构造器
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
//仅明确初始容量的构造器(装载因子默认0.75)
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}通过上面的源码,我们发现了HashSet就TM是一个皮包公司,它就对外接活儿,活儿接到了就直接扔给HashMap处理了。因为底层是通过HashMap实现的,这里简单提一下:
HashMap的数据存储是通过数组+链表/红黑树实现的,存储大概流程是通过hash函数计算在数组中存储的位置,如果该位置已经有值了,判断key是否相同,相同则覆盖,不相同则放到元素对应的链表中,如果链表长度大于8,就转化为红黑树,如果容量不够,则需扩容(注:这只是大致流程)。
如果对HashMap原理不太清楚的话,可以先去了解一下
HashMap原理(一) 概念和底层架构
HashMap原理(二) 扩容机制及存取原理
三. add方法
HashSet的add方法时通过HashMap的put方法实现的,不过HashMap是key-value键值对,而HashSet是集合,那么是怎么存储的呢,我们看一下源码
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}看源码我们知道,HashSet添加的元素是存放在HashMap的key位置上,而value取了默认常量PRESENT,是一个空对象,至于map的put方法,大家可以看HashMap原理(二) 扩容机制及存取原理。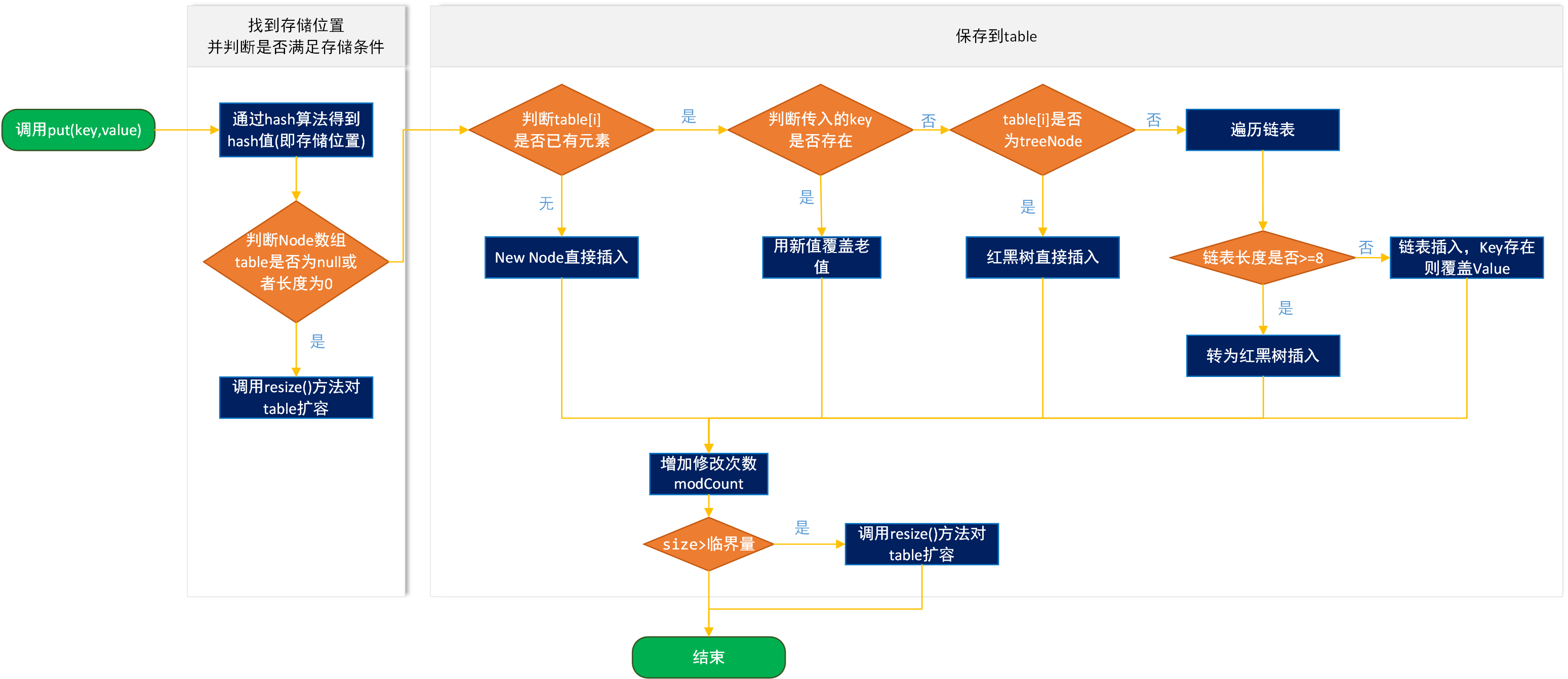
四. remove方法
HashSet的remove方法通过HashMap的remove方法来实现
//HashSet的remove方法
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
//map的remove方法
public V remove(Object key) {
Nodee;
//通过hash(key)找到元素在数组中的位置,再调用removeNode方法删除
return (e = removeNode(hash(key), key, null, false, true)) == null ? null : e.value;
}
/**
*
*/
final NoderemoveNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node[] tab; Nodep; int n, index;
//步骤1.需要先找到key所对应Node的准确位置,首先通过(n - 1) & hash找到数组对应位置上的第一个node
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Nodenode = null, e; K k; V v;
//1.1 如果这个node刚好key值相同,运气好,找到了
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
/**
* 1.2 运气不好,在数组中找到的Node虽然hash相同了,但key值不同,很明显不对, 我们需要遍历继续
* 往下找;
*/
else if ((e = p.next) != null) {
//1.2.1 如果是TreeNode类型,说明HashMap当前是通过数组+红黑树来实现存储的,遍历红黑树找到对应node
if (p instanceof TreeNode)
node = ((TreeNode)p).getTreeNode(hash, key);
else {
//1.2.2 如果是链表,遍历链表找到对应node
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
//通过前面的步骤1找到了对应的Node,现在我们就需要删除它了
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
/**
* 如果是TreeNode类型,删除方法是通过红黑树节点删除实现的,具体可以参考【TreeMap原理实现
* 及常用方法】
*/
if (node instanceof TreeNode)
((TreeNode)node).removeTreeNode(this, tab, movable);
/**
* 如果是链表的情况,当找到的节点就是数组hash位置的第一个元素,那么该元素删除后,直接将数组
* 第一个位置的引用指向链表的下一个即可
*/
else if (node == p)
tab[index] = node.next;
/**
* 如果找到的本来就是链表上的节点,也简单,将待删除节点的上一个节点的next指向待删除节点的
* next,隔离开待删除节点即可
*/
else
p.next = node.next;
++modCount;
--size;
//删除后可能存在存储结构的调整,可参考【LinkedHashMap如何保证顺序性】中remove方法
afterNodeRemoval(node);
return node;
}
}
return null;
}removeTreeNode方法具体实现可参考 TreeMap原理实现及常用方法
afterNodeRemoval方法具体实现可参考LinkedHashMap如何保证顺序性
五. 遍历
HashSet作为集合,有多种遍历方法,如普通for循环,增强for循环,迭代器,我们通过迭代器遍历来看一下
public static void main(String[] args) {
HashSetsetString = new HashSet<> ();
setString.add("星期一");
setString.add("星期二");
setString.add("星期三");
setString.add("星期四");
setString.add("星期五");
Iterator it = setString.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}打印出来的结果如何呢?
星期二
星期三
星期四
星期五
星期一
意料之中吧,HashSet是通过HashMap来实现的,HashMap通过hash(key)来确定存储的位置,是不具备存储顺序性的,因此HashSet遍历出的元素也并非按照插入的顺序。
六. 合计合计
按照我前面的规划,应该每一块主要的内容都单独写一下,如集合ArrayList,LinkedList,HashMap,TreeMap等。不过我在写这篇关于HashSet的文章时,发现有前面对HashMap的讲解后,确实简单,HashSet就是一个皮包公司,在HashMap外面加了一个壳,那么LinkedHashSet是否就是在LinkedHashMap外面加了一个壳呢,而TreeSet是否是在TreeMap外面加了一个壳?我们来验证一下
先看一下LinkedHashSet
最开始的结构图已经提到了LinkedHashSet是HashSet的子类,我们来看源码
public class LinkedHashSetextends HashSetimplements Set, Cloneable, java.io.Serializable
{
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
public LinkedHashSet(int initialCapacity) {
super(initialCapacity, .75f, true);
}
public LinkedHashSet() {
super(16, .75f, true);
}
public LinkedHashSet(Collection< ? extends E> c) {
super(Math.max(2*c.size(), 11), .75f, true);
addAll(c);
}
public Spliteratorspliterator() {
return Spliterators.spliterator(this, Spliterator.DISTINCT | Spliterator.ORDERED);
}
}上面就是LinkedHashSet的所有代码了,是不是感觉智商被否定了,这基本上没啥东西嘛,构造器还全部调用父类的,下面就是其父类HashSet的对此的构造方法
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}大家也看出来,和我们的猜测一样,没有深究下去的必要了。如果有兴趣可以看看LinkedHashMap如何保证顺序性
在看一下TreeSet
public class TreeSetextends AbstractSetimplements NavigableSet, Cloneable, java.io.Serializable
{
public TreeSet() {
this(new TreeMap());
}
public TreeSet(Comparator< ? super E> comparator) {
this(new TreeMap<>(comparator));
}
public TreeSet(Collection< ? extends E> c) {
this();
addAll(c);
}
public TreeSet(SortedSets) {
this(s.comparator());
addAll(s);
}
}确实如我们所猜测,TreeSet也完全依赖于TreeMap来实现
以上是“Java中HashSet原理及常用方法的示例分析”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:http://blog.itpub.net/31559985/viewspace-2657644/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



