这篇文章主要讲解了“怎么用Numpy分析某单车骑行时间”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“怎么用Numpy分析某单车骑行时间”吧!
看标题就知道了,分析各季度共享单车的骑行时间。
因为这次的数据源自网络,所以先简单看下数据的结构:
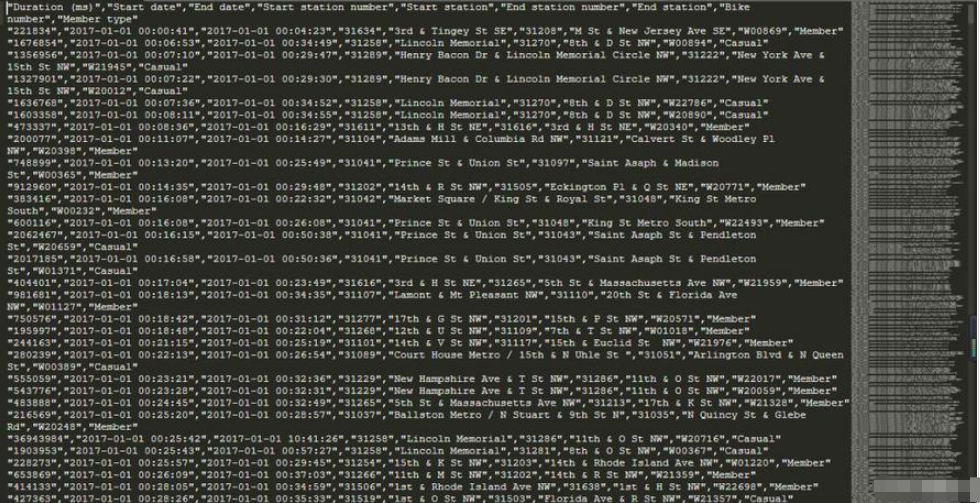
可以看到数据有9个字段:
"Duration (ms)","Start date","End date","Start station number","Start station","End station number","End station","Bike number","Member type"按照我们的目标,我们只需要第一个字段Duration(ms)。
所以第一步先读取已经下载好的数据之后在第二步数据清洗中取出需要的字段:
# 数据收集def data_collection(): data_arr_list = [] for data_filename in data_filenames: file = os.path.join(data_path, data_filename) data_arr = np.loadtxt(file,dtype=bytes,delimiter=',', skiprows=1).astype(str) data_arr_list.append(data_arr) return data_arr_list因为数据是整理后导出的数据所以不需要清洗缺失值等操作,我们直接取出需要的字段,做一些处理即可。
这里骑行时间单位为ms,所以需要转化为min需要/1000/60。
# 数据清洗def data_clean(data_arr_list): duration_min_list = [] for data_arr in data_arr_list: data_arr = data_arr[:,0] duration_ms = np.core.defchararray.replace(data_arr,'"','') duration_min = duration_ms.astype('float') / 1000 / 60 duration_min_list.append(duration_min) return duration_min_list计算平均值在numpy中提供了计算函数,直接调用即可。
# 数据分析def mean_data(duration_min_list): duration_mean_list = [] for duration_min in duration_min_list: duration_mean = np.mean(duration_min) duration_mean_list.append(duration_mean) return duration_mean_list这里可视化展示使用的是matplotlib.pyplot库,咸鱼目前还没有写相关的入门文章,可以上网看下文档学习下简单使用即可,之后会有系列文章写可视化的内容。
# 数据展示def show_data(duration_mean_list): plt.figure() name_list = ['第一季度', '第二季度', '第三季度', '第四季度'] plt.bar(range(len(duration_mean_list)),duration_mean_list,tick_label = name_list) plt.show()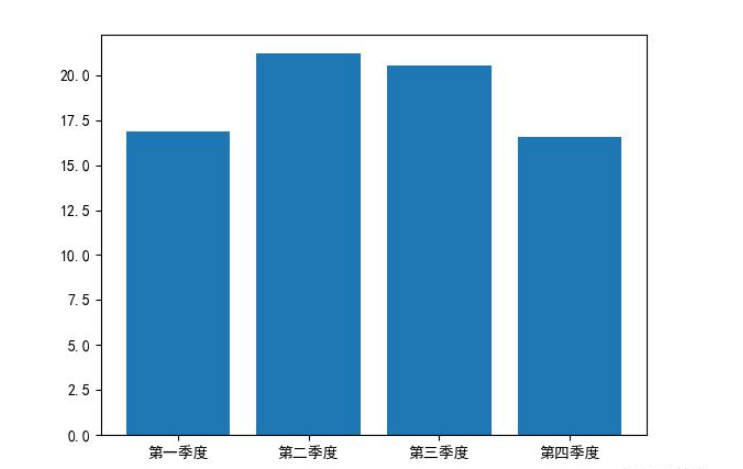
单单从上面的图可以看到以炎热的夏季和凉爽的秋季为主调的二三季度的骑行时间要高于春冬为主调的一四季度,以此判断气温变化对人们使用的共享单车的影响。
在python中字符串是有字节字符串和文本字符串之分的,我们通常说的字符串是指文本字符串。而使用numpy的loadtxt函数读取的字符串默认是字节字符串,输出的话字符串前面会有个b,形如b’……’。通常是需要转换的,如果不转换将会出现问题。
在数据收集部分如果不注意这一点,在数据清洗部分,字段的格式就会因为Duration的值多了一个b转化上就会报错。
处理方式:
numpy.loadtxt读入的字符串总是bytes格式,总是在前面加了一个b
原因:np.loadtxt and np.genfromtxt operate in byte mode, which is the default string type in Python 2. But Python 3 uses unicode, and marks bytestrings with this b. numpy.loadtxt中也声明了:Note that generators should return byte strings for Python 3k.解决:使用numpy.loadtxt从文件读取字符串,最好使用这种方式np.loadtxt(filename, dtype=bytes).astype(str)
可以看到咸鱼在读取数据的时候使用的是numpy.loadtxt,这样的操作固然方便,但是代价就是内存直接爆掉,还好这次的数据才500M,所以不推荐大家使用我这个方法,之后会加以改进(如果我会的话)
这里分享一段代码,来自慕课网bobby老师的实战课,如何使用生成器读取大文本文件:
#500G, 特殊 一行def myreadlines(f, newline): buf = "" while True: while newline in buf: pos = buf.index(newline) yield buf[:pos] buf = buf[pos + len(newline):] chunk = f.read(4096) if not chunk: #说明已经读到了文件结尾 yield buf break buf += chunkwith open("input.txt") as f: for line in myreadlines(f, "{|}"): print (line)在可视化的时候,柱状图的标识是中文,在显示的时候直接显示的是方块,无法显示中文。如下:
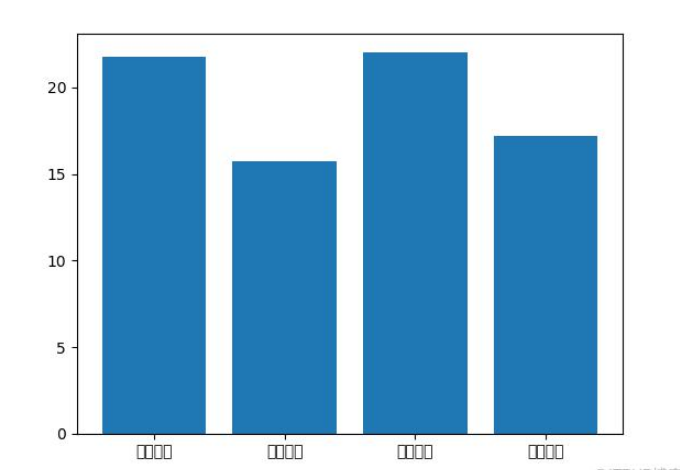
处理方法:
解决方式一:修改配置文件(1)找到matplotlibrc文件(搜索一下就可以找到了)(2)修改:font.serif和font.sans-serif,我的在205,206行font.serif: SimHei, Bitstream Vera Serif, New Century Schoolbook, Century Schoolbook L, Utopia, ITC Bookman, Bookman, Nimbus Roman No9 L, Times New Roman, Times, Palatino, Charter, serif Bookman, Nimbus Roman No9 L, Times New Roman, Times, Palatino, Charter, seriffont.sans-serif: SimHei, Bitstream Vera Sans, Lucida Grande, Verdana, Geneva, Lucid, Arial, Helvetica, Avant Garde, sans-serif解决方式二:在代码中修改import matplotlib指定默认字体matplotlib.rcParams[‘font.sans-serif’] = [‘SimHei’]matplotlib.rcParams[‘font.family’]=’sans-serif’解决负号’-‘显示为方块的问题matplotlib.rcParams[‘axes.unicode_minus’] = False感谢各位的阅读,以上就是“怎么用Numpy分析某单车骑行时间”的内容了,经过本文的学习后,相信大家对怎么用Numpy分析某单车骑行时间这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:http://blog.itpub.net/31556785/viewspace-2286242/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



