这篇文章主要介绍“Hadoop2.7.5+Spark2.2.1分布式集群怎么搭建”,在日常操作中,相信很多人在Hadoop2.7.5+Spark2.2.1分布式集群怎么搭建问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Hadoop2.7.5+Spark2.2.1分布式集群怎么搭建”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
一、运行环境
CentOS 6.5
Spark 2.2.1
Hadoop 2.7.5
Java JDK 1.8
Scala 2.12.5
二、节点IP及角色对应关系
| 节点名 | IP | Spark角色 | hadoop角色 |
| hyw-spark-1 | 10.39.60.221 | master、worker | master |
|
hyw-spark-2 | 10.39.60.222 | worker | slave |
| hyw-spark-3 | 10.39.60.223 | worker | slave |
三、基础环境配置
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
四、jdk安装(在hadoop用户下执行)
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
五、scala安装(在hadoop用户下执行)
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
六、hadoop集群安装(在hadoop用户下执行)
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
undefined
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hyw-spark-1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
</configuration>
6.4.4、$vim hdfs-site.xml
将文件末尾修改为
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
6.4.5、$vim mapred-site.xml
将文件末尾 修改为
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
6.4.6、$vim yarn-site.xml
将文件末尾修改为
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hyw-spark-1</value>
</property>
</configuration>
6.4.7、$vim slaves
添加如下内容
hyw-spark-1
hyw-spark-2
hyw-spark-3
6.4.8、拷贝文件到slave节点(总共7个文件)
$scp hadoop-env.sh yarn-env.sh core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml slave hadoop@hyw-spark-2:/usr/local/spark/etc/spark/
$scp hadoop-env.sh yarn-env.sh core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml slave hadoop@hyw-spark-3:/usr/local/spark/etc/spark/
6.5、启动hadoop集群
6.5.1、格式化NameNode
在Master节点上,执行如下命令
$hdfs namenode -format
成功的话,会看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若为 “Exitting with status 1” 则是出错。
6.5.2、启动HDFS(NameNode、DataNode)
在Master节点上,执行如下命令
$start-dfs.sh
使用jps命令在Master上可以看到如下进程:
8757 SecondaryNameNode
7862 DataNode
7723 NameNode
8939 Jps
使用jps命令在两个Slave上可以看到如下进程:
7556 Jps
7486 DataNode
6.5.3启动Yarn(ResourceManager 、NodeManager)
在Master节点上,执行如下命令
$start-yarn.sh
使用jps命令在Master上可以看到如下进程:
9410 Jps
8757 SecondaryNameNode
8997 ResourceManager
7862 DataNode
9112 NodeManager
7723 NameNode
使用jps命令在两个Slave上可以看到如下进程:
7718 Jps
7607 NodeManager
7486 DataNode
6.5.4通过浏览器查看HDFS信息
浏览器访问http://10.39.60.221:50070,出现如下界面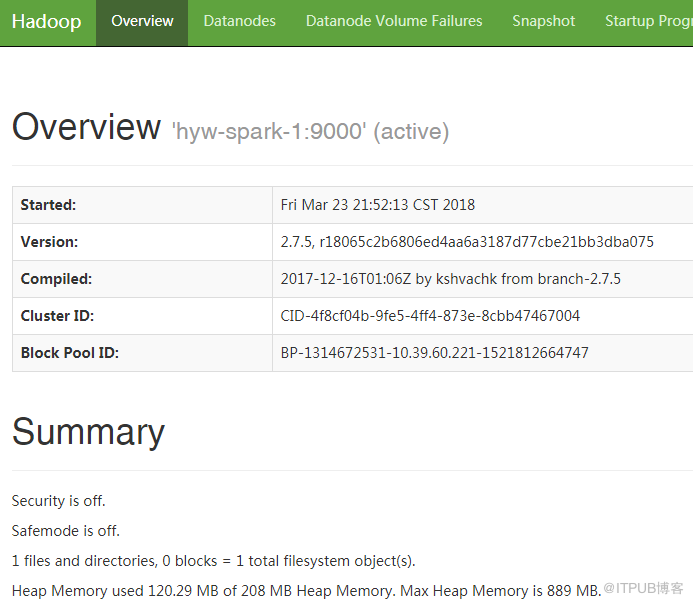
七、spark安装(在hadoop用户下执行)
7.1、下载文件到/opt目录下,解压文件到/usr/local
$cd /opt
$sudo tar -xzvf spark-2.2.1-bin-hadoop2.7.tgz -C /usr/local
$cd /usr/local
$sudo mv spark-2.2.1-bin-hadoop2.7/ spark
$sudo chown -R hadoop:hadoop spark
7.2、设置环境变量
$sudo vi /etc/profile
添加如下内容
export SPARK_HOME=/usr/local/spark
PATH=$JAVA_HOME/bin:$PATH:$HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin
更新环境变量
source /etc/profile
7.3、配置文件修改
以下操作均在master节点配置,配置完成后scp到slave节点
$cd /usr/local/spark/conf
7.3.1、$cp spark-env.sh.template spark-env.sh
$vim spark-env.sh
添加如下内容
export JAVA_HOME=/opt/jdk1.8
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SCALA_HOME=/usr/local/scala
export SPARK_MASTER_IP=10.39.60.221
export SPARK_WORKER_MEMORY=1g
7.3.2、$cp slaves.template slaves
$vim slaves
添加如下内容
hyw-spark-1
hyw-spark-2
hyw-spark-3
7.3.3拷贝文件到slave节点
$scp -r spark-env.sh slaves hadoop@hyw-spark-2:/usr/local/spark/conf/
$scp -r spark-env.sh slaves hadoop@hyw-spark-3:/usr/local/spark/conf/
7.4、启动spark
7.4.1、启动Master节点
Master节点上,执行如下命令:
$start-master.sh
使用jps命令在master节点上可以看到如下进程:
10016 Jps
8757 SecondaryNameNode
8997 ResourceManager
7862 DataNode
9112 NodeManager
9832 Master
7723 NameNode
7.4.2、启动worker节点
Master节点上,执行如下命令:
$start-slaves.sh
使用jps命令在三个worker节点上可以看到如下进程:
7971 Worker
7486 DataNode
8030 Jps
7.5、通过浏览器查看spark信息
浏览器访问http://10.39.60.221:8080,出现如下界面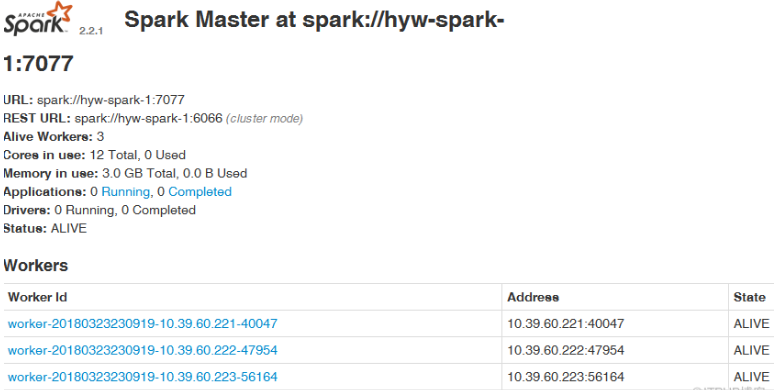
到此,关于“Hadoop2.7.5+Spark2.2.1分布式集群怎么搭建”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





