
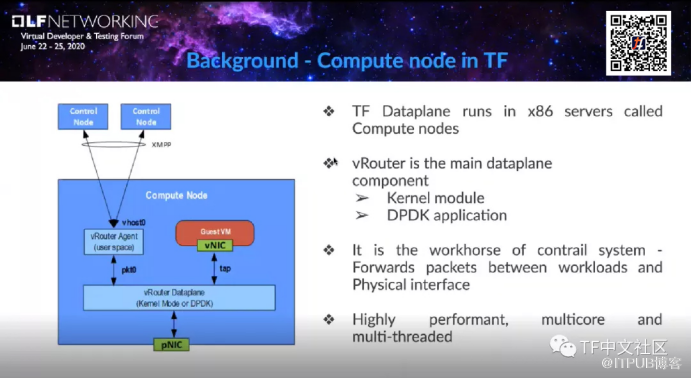
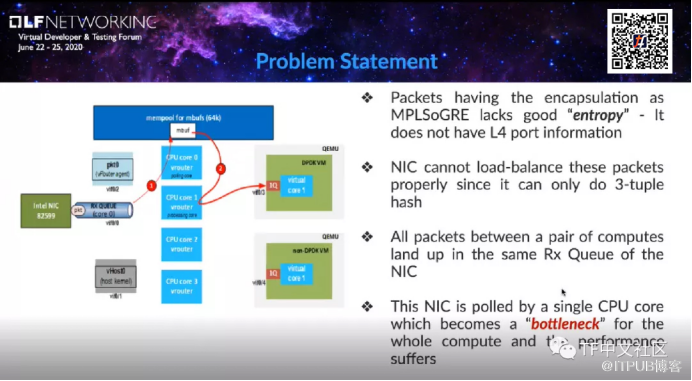
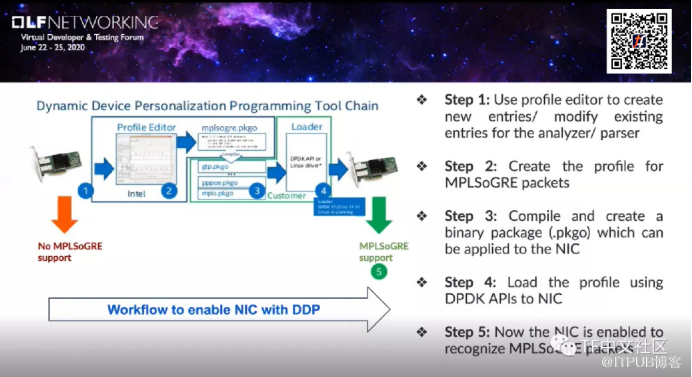
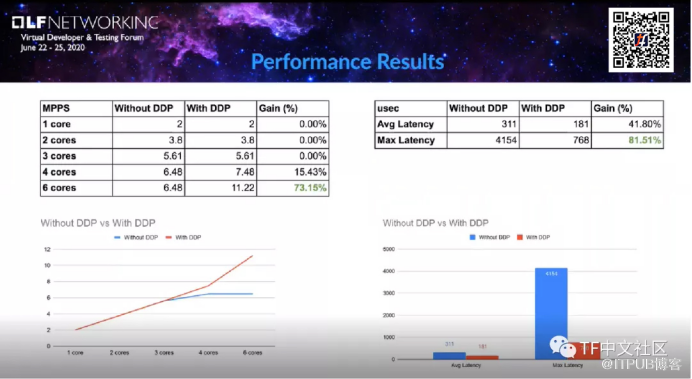
实际上,vRouter可以部署在常规X86服务器上,也可以在OpenStack或K8s的计算节点当中。vRouter是主要的数据平面组件,有两种部署的模式,分别是vRouter:kernel module,以及vRouter:DPDK模式。
https://tungstenfabric.org.cn/assets/uploads/files/tf-vrouter-performance-improvements.pdf
【 视频链接 】
https://v.qq.com/x/page/j3108a4m1va.html


亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:http://blog.itpub.net/69957171/viewspace-2702178/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



