Tungsten Fabric从云基础架构(计算、网络和存储)及其上运行的工作负载收集信息,以便于运营监控、故障排除和容量规划。
数据以多种格式收集,例如系统日志,结构化消息(称为Sandesh)、Ipfix、Sflow和SNMP。诸如vRouters、物理主机、虚拟机、接口、虚拟网络和策略之类的对象被建模为用户可见实体(UVE),并且UVE的属性可以来自不同格式的各种源。
分析收集的体系结构如下图所示:
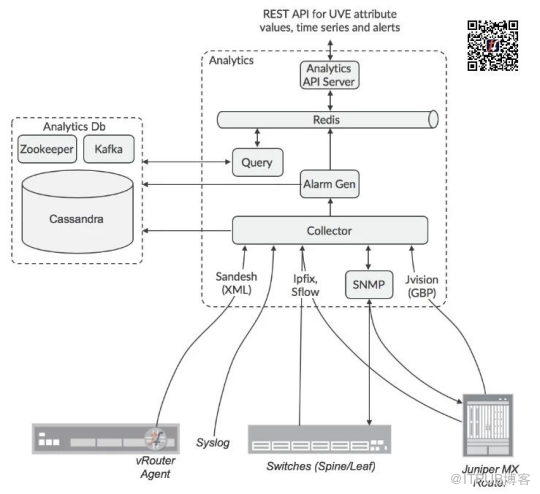
为数据源可以配置目标收集器的IP地址,或者为收集器配置的负载均衡器。SNMP轮询的责任由Zookeeper分布在不同的节点上。
分析节点将传入的数据格式化为通用数据格式,然后通过Kafka服务将其发送到Cassandra数据库。
API URL可以使用ha-proxy或其他一些负载均衡器进行负载平衡。
收集UVE数据的责任使用Zookeeper在Analytics节点之间分配,因此UVE数据的API查询由接收节点复制到其他Analytics节点,并且保存与请求相关的数据的那些查询,将响应返回到原始节点,该节点将核对响应,并整理到请求者将要接收的回复中。
警报生成的责任也分布在节点之间,因此警报生成功能订阅Analyticsdb节点中的Kafka总线,以便观察计算是否满足警报条件所需的数据,因为此数据可能由其他节点收集。
UVE在多个Kafka主题中进行了散列,这些主题分布在Alarm Gen功能中,以便有效地分散负载。
最新版本的Tungsten Fabric(5.0及更高版本)使用基于Docker容器的微服务架构。微服务被分组到pod中,这些pod根据角色在部署期间分配给服务器。
微服务与pod的关系如下图所示:
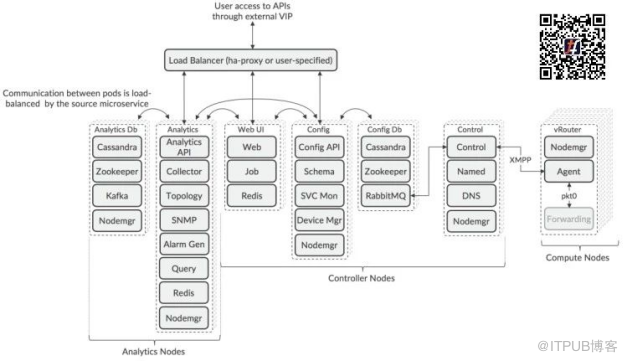
该体系结构是可组合的,这意味着可以使用在不同服务器上运行的多个pod单独扩展每个Tungsten Fabric角色,以支持特定部署的弹性和性能要求。
由于Zookeeper中用于选择活动节点的算法的性质,在Controller和Analytic节点中部署的pod的数量必须是奇数,但是在pod类型之间可能会有所不同。
节点是逻辑分组,其pod可以部署在不同的服务器上,服务器可以运行来自不同节点类型的pod。
可以通过在Contrail安装期间部署的负载均衡器或第三方负载均衡器来访问API和Web GUI服务。使用第三方负载均衡器可以允许pod位于不同的子网中,这是一种常见情况,需要将pod放置在数据中心的不同机架中以实现弹性。
Control pod可以根据群集中的计算节点数量进行增减,每个控制节点最多有1000个节点。可以在特定使用情况下部署增加控制节点,其中控制器节点可以远程地部署管理计算节点。
计算节点的数量根据预期,由编排器部署的工作负载的需求进行调整。在计算节点内,转发器功能未在容器里实现
(请参阅本系列文章第五篇“
vRouter的部署选项”)。
跨服务器的Tungsten Fabric服务的布局,由部署工具读取的配置文件控制,可以是Ansible(使用playbooks)或Helm(使用图表)。示例手册和图表可用于涵盖所有服务在同一VM中运行的简单一体化部署,以及涉及多个VM或裸机服务器的高可用性示例。同时提供了示例,orchestrator和Tungsten Fabric在公有云(例如Amazon Web Services,Google Cloud Engine,Microsoft Azure)中运行,并且工作负载也在那里运行。
有关部署工具及其使用方法的更多详细信息
请访问Tungsten Fabric网站 ( www.tungsten.io)
中文网站( www.tungstenfabric.org.cn)
更多Tungsten Fabric解析文章
第一篇: TF主要特点和用例
第二篇: TF怎么运作
第三篇:详解vRouter体系结构
第四篇: TF的服务链
第五篇:
vRouter的部署选项
关注微信:TF中文社区
邮箱:tfzw001@163.com

亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:http://blog.itpub.net/69957171/viewspace-2670973/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



