本文将介绍如何打造百万级的容器技术。众所周知,阿里巴巴在 “双11” 活动之前上线了数以百万计的容器,面对如此大的规模,阿里巴巴的容器技术到底有哪些功能特性来帮助它快速落地?我将从场景痛点与解决方案的角度同大家分享。
如今,容器和 Kubernetes 的概念炒得很火,但是我相信,还有部分企业在内部并没有把自己的业务进行容器化,那根据咱们大会现场的反馈结果也是如此。这就说明在容器化的过程中,不管技术如何落地,我们对环境有一些什么样的要求,总有一些需要解决的问题。接下来,让我们一起来看一下,阿里是如何做到在线业务百分之百容器化的。
首先我们了解一下在线业务是什么?比如说大家在淘宝、闲鱼上买东西,或利用支付宝支付一些费用,而这些业务都需要提供实时服务。诸如此类的业务在阿里中十分广泛。其中还包括像视频(优酷)、搜索、阿里专有云也都具备容器能力。

PouchContainer 简介
首先为大家介绍一些 PouchContainer 的历史。阿里从 2011 年开始打造容器技术,但是这个容器技术并没有像后来的 Docker 那么流行。主要是什么原因呢?主要是我们服务于内部,只是打造一个容器环境,提高集团资源利用率,但是并没有抽象出来现在社区的镜像技术。
大家可以认为镜像技术是容器技术爆发的关键点之一,因为它给我们的业务带来了持续交付能力,可以让我们的业务、应用做到增量增发。2011 年,阿里是基于 LXC 的 CGroup 以及 Namespace 技术来实现。那时我们已经具备做容器的技术,当时采用 LXC 技术,并很快将当时的容器技术推到线上运行。
2015 年,我们发现外部的 Docker 发展越来越火,于是我们将 Docker 的镜像技术推到集团内部。将 LXC 与 Docker 两者集成,再加上必要的技术演进,就形成了现在的 PouchContainer。2017 年的“双十一”,PouchContainer 宣布开源。现在包括阿里内部 PouchContainer 任何一个特性与任何一行代码的增删改查,大家都可以在 GitHub 上看到。
说一下阿里容器技术在演进过程中考虑了哪些内容,这可能和社区当中的容器技术又不一样。比如说 Docker,它倡导的理念是 one process one container(在容器中永远只运行一个应用),但在企业里面的应用架构是这样吗?可能很多都不是。有很多业务在开发过程中就是为了依赖于一些其他的系统应用。
比如说我们有很多应用很难做到和底层基础设施的解绑,这些应用会使用底层的一些 systemd 和 crond 等去交付,它的日志当中可能天生就要去和 syslog 去做交付。甚至为了运维人员的便利,我们需要在这个运行环境当中自行支持一个 SSHD。而 Docker 的理念并不是特别合适这样的需求,这就需要容器技术来满足。
我们必须先满足开发者的要求,再满足运维人员要求,只有这样我们提供的新技术才会对现有的技术架构没有侵入性。一旦新技术没有侵入性,那它的推广往往会比较透明且速度较快,企业内推行阻力也会比较小。
但如果说一个基础设施技术,在提供业务方服务时,对业务方有诸多要求,那这样推广往往会面对很多阻力。那我们为什么要做这样?我们为什么要做 PouchContainer (富容器),就是因为我们不能对开发和运维造成任何的侵入性,不能去侵入他们的流程,我们必须提供一个对他们完全透明的技术,这样就能在很短的时间内迅速容器化所有的业务。这也是我们存在一个比较大的价值。
PouchContainer 架构
这是一张 PouchContainer 的知识架构图:
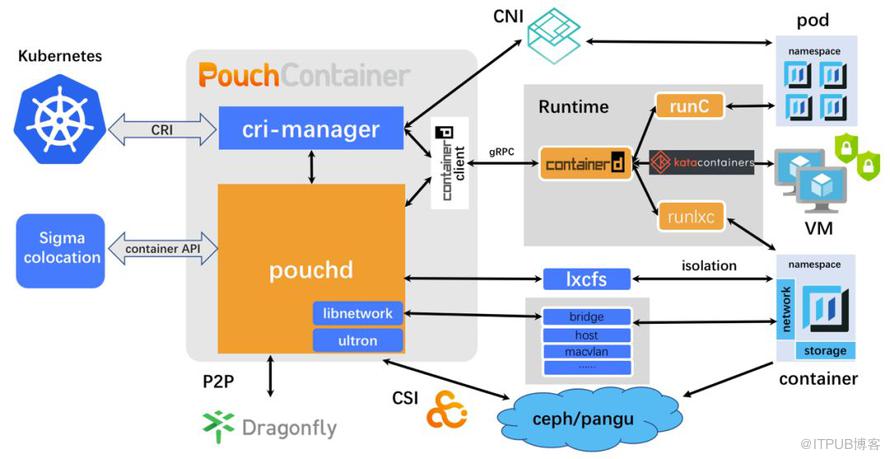
现在我就此图为大家进行解读:如果我们横向在中间“切一刀”,就会发现部署编排里的一些概念,比如说 Kubernetes,比如说我们的 CRI、Pod 都是编排的一些概念,我们的 PouchContainer 可以非常方便地支持 Kubernetes,而且我们增强了 Kubernetes 体验,在本末我将会跟大家展开来说。下一层是 container API。对于 container API,大家可以看到一个 container manager 的管控域,包括网络、存储。上下是两层 ,分别是编排和容器域。
如果此图纵向“切四刀”,大家会比较好理解,左边是我们的调度域和 Kubernetes;第二层是我们的引擎;第三层是我们的 Runtime 层,包括我们的 runc、runlxc 还有 katacontainer。最右边是容器的运行载体:Pod ,container 或者说 katacontainer。
PouchContainer 技术特性
富容器
从功能角度来讲,PouchContainer 帮大家解决了现实场景中的什么问题?第一点,富容器将业务运维域所看到的所有内容都放到一个容器中。为什么要这样做?当我们提供一个容器技术时,我们不希望对应用开发和运维有任何影响,否则在企业中就会很难推广。在运维团队方面,运维团队都会维稳,他们往往不希望你入太多的变量。比如说,运维同学可能会非常依赖于自己使用的那套工具,一旦这套工具在我们新技术面前变得不可用了,在面对新技术时他们会说“不”。
富容器技术,就是将运维需要的所有内容打包到这个镜像中去。在应用运行过程中,这些运维组件继续发挥作用。只有这样之后,富容器技术才能更好地适配应用。可以说,富容器技术是阿里巴巴集团内部真正快速做到百分之一百容器化的一个重要前提。如果说,各位同学觉得在企业中推动容器技术比较慢或者阻碍较大,不妨试用一下富容器技术将流程化简。
从技术架构角度来看,我们的富容器到底有哪些优势?第一,我们容器内部会有一个 systemd,很像虚拟机。这个 systemd 起到什么作用呢?systemd 主要是来做好容器内部的更细致化管理。比如说僵尸进程,利用它就很好管理,而 Docker 可能并不能做到这方面的一些工作。同时他也有能力去管控容器内部更多的一些系统服务,包括像 syslogd、SSHD 等。这样就可以保证运维,而不需要对这个系统做任何修改。
第二,富容器对容器的管控层做了更多细致化要求,比如说我们的 prestart hook、post stop hook。为了满足运维人员的一些需求,我们在做一些初始化管控时,会在它启动前要做一些前置工作,或者说在停止后做一些后置工作。
富容器的价值分为两点:
富容器完全兼容容器镜像。兼容容器镜像后,对大家的业务交付效率没有任何影响;
富容器兼容了我们的运维体系,充分保障运维体系原有和现有的运维能力,对现有的运维体系没有任何侵入性。
增强的隔离性
接下来与大家分享关于 PouchContainer 的隔离性。隔离性方面的问题我会从切身体验的方向出发:
第一个,资源可见性隔离。如果你是一个深度容器使用者,应该会在生产环境中使用容器。如果你用的是 JAVA 应用感触应该更深一些。如果在一台拥有 10G 内存的宿主机上创建容器,给它设置 1 个 G 的内存,你在容器中的 /proc/meminfo 会显示宿主机的 10G 内存,而并不是你设定的 1 个 G。这样的显示会导致什么影响呢?
在很多情况下,应用启动往往并不是只要把二进制文件启动起来就行。比如,JAVA 应用,它往往会去判断宿主机的 /proc/meminfo 中的一些资源,再去动态分配 JVM 堆栈大小。如果容器中的 JAVA 应用通过这种方式去启动,那么你设置的任何资源限制都无济于事。这样也有可能导致 JAVA 应用的 OOM 异常。这种情况下,我们通过 LXCFS 技术来通用化解决这个问题,对于我们的应用,开发和运维都不需要做任何改动。
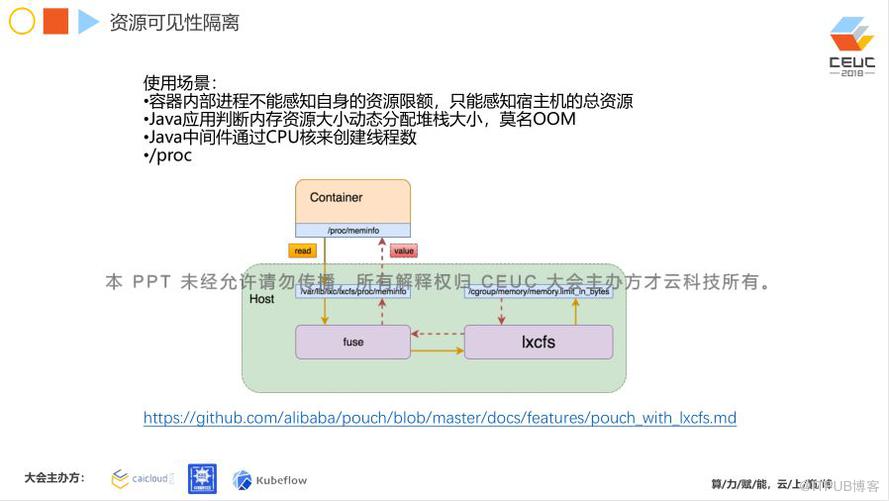
其实它做的事情也比较简单,只要我们对一个容器做一个资源限制,在 CGroup filesystem 当中,就会有这样一个数值,这是 memory.limit_in_bytes 下面的一个文件。这样的一个虚拟文件,其实 LXCFS 可以把它动态读出,然后再去生成一个虚拟文件,再将这个文件挂载到真实的容器中的相应位置。在容器启动过程中,他得到的值就是它真正限制的值。
现在资源可见性的隔离就解决了,而 JAVA 的应用也不会有 OOM 异常。那么问题来了,我们为什么要做这样一个东西?电商应用很多都是 JAVA 应用,DiskQuota 主要用来做容器的磁盘限额。
在容器公有服务中,我想简单给大家介绍几个问题:
第一,如果我们不是通过 block 来做管理容器存储,而是通过一些纯粹的文件系统,文件系统视角可以隔离但是无法做到磁盘 quota。也就是说两个容器如果共用一个文件系统,虽然我看不见你,但是我可以用我的文件系统磁盘导致你无法使用。这也是一种互相干扰的情况。
第二,inode(索引节点)。也就是我在我这个容器里面拼命创建小文件,我没有占磁盘空间,在我拼命创建小文件时,另外一个容器就完全无法运行(一些基本命令无法执行),这都是隔离方面的一些问题。在 PouchContainer 中不少应用在运行时也会遇到这种情况。一个应用程序写不好,它就有可能通过一个循环来写文件,导致磁盘写爆。那我们怎么来解决这个问题呢?我们通过 DiskQuota 来做这件事情。
容器公有服务就说到这里。我们接着说增强隔离性的第二个问题。
第二个,隔离特性是 hypervisor-based container。部分同学有这样的疑问, PouchContainer 是否可以支持一些老内核?在这方面我们也做了一些工作,我们可以在 PouchContainer 创建的 runV 虚拟机中运行一个老内核。这么做会有什么效果呢?
如此我们存量的业务全部可以拥抱 Kubernetes 。企业当中一定会有很多基于 2.6.32 内核的应用。这些应用至今都跟 Docker 和 Kubernetes 一点关系都没有,为什么会出现这种现象?
因为那些技术都对内核有要求,即新技术对内核有要求,而依赖于低版本内核的应用完全无法使用新技术。对于企业而言,到底想不想上 Kubernetes 呢?肯定是想上的。又该如何上呢?有没有一种能力能够把我们 Host OS 全都升级,升级到 3.10 或者 3.19、4.4、4.9 这样的一些内核。但为什么现在还没有人去尝试呢?
因为运维团队无法承担升级后对上层业务造成的一些影响。但是有一种方式,如果说我们这种 runV 虚拟机中运行的是老内核,而我们在 host 上可以运行升级后的内核,那我们完全有能力把数据中心物理机的内核完全升级。
因为宿主机内核跟我们的业务已经不耦合了,这样就可以完全升级。但是我们的 runV 虚拟机中运行的还是老内核,应用还在 runV 虚拟机中。这样就完全可以让整个数据中心的基础技术架构升级。在传统行业中我相信这样的操作很有杀伤力。因为大家都在考虑怎么解决这个存量异构操作系统的问题。
如果你的内核无法升级,那你就无法去迎接一些新的技术,数字化转型进程也会比较慢。
P2P 镜像分发
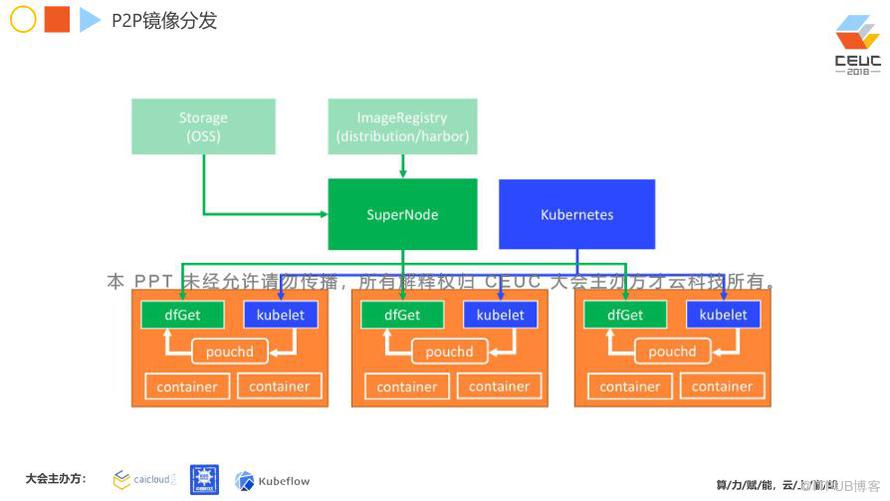
这个是阿里巴巴的镜像分发技术,我们认为镜像分发是一个非常大的专题。你知道容器镜像的平均大小是多少吗?有没有哪个企业的平均镜像大小都小于 500M?实际这种情况很少,这就说明镜像很大。那镜像很大时会出现什么样的问题?比如说在阿里的一些大促,例如双十一,我们需要把镜像大量的分发到各个机器上,其中分发效率是我们需要考虑的一个关键。
如果不考虑这个问题,你会发现 1000 台机器上都在向一个 registry 发送下载镜像请求,那这个 registry 可能就会出现问题。我们从问题入手,需要做的是 Dragonfly(P2P的智能文件分发系统),它有这方面的一些特性,主要是来解决一些分发瓶颈。现在开源的 Dragonfly 也有我们的一些用户,包括像 Lazada 的公司。
它主要的一些功能特性主要是盯住了云原生应用的分发方面,在分发方面有三个维度:
分发的效率;
分发的流控;
分发的安全。
容器的原地升级功能
这是针对有状态应用做的一个功能,PouchContainer 在容器引擎层面提供了一个 Upgrade 接口,用于实现容器的原地升级功能。在 CNCF 倡导的理念中很多 container 都是 stateless 也就是无状态的。但是企业中真的有那么多无状态的应用吗?可能未必,现实情况是有相当一部分还是有状态的。
那这些有状态的业务我们应该怎么去升级,怎么去更新呢?在更新的过程当中,能不能把之前的那些状态给继A承下来呢?这个是我们需要考虑的。在升级过程中 ,我们做了容器的 Upgrade 这样一个操作。其实据我所知,国内的互联网公司中应用的架构走的比较靠前,但是大部分公司仍然利用一些有状态容器,其实他们各自都实现了这样一个功能。
究竟应该如何实现容器的原地升级呢?其实很简单,所有有状态的东西保留不变,升级要升级的东西即可。
那究竟什么东西是要升级的呢?从技术的角度来讲,我们一般认为镜像是需要升级的。在运行的过程中我们把一个容器真正停掉,然后在组建这个文件系统过程中把原来老的镜像给撤掉,把新的镜像填进来;然后再去启动原有的 command,这样能保证完全做到原地升级。目前,我们正把这一功能集成进我们自身的调度系统中,包括我们内部的 Sigma 也是依赖于这样的一个功能来做业务升级的。
原生支持 Kubernetes
这里介绍下 PouchContainer 原生支持 Kubernetes。说到原生支持 Kubernetes,我们主要是实现了 CRI 容器运行时接口。大家今天听到了很多遍 CRI(Container Runtime Interface)它主要是用来解耦 Kubernetes 对于底层 container Runtime 的依赖。那我们为什么要去实践 CRI 呢?
原因很简单:因为我们要把 PouchContainer 这么多生产级别的功能,全都透传到 Kubernetes 体系当中去。大家知道 Kubernetes 支持 LXCFS,那它支持我们这个升级吗?肯定是不支持的。既然不被 Kubernetes 支持,那 Kubernetes 可以直接在阿里巴巴内部落地吗?往往很难,我们必须要把 Runtime 的这些增强透传到我们 Kubernetes 当中去,之后才能让容器技术更好的落地。
结语
以上就是阿里巴巴在容器领域的实践,欢迎后续大家一起交流
原文链接:https://mp.weixin.qq.com/s/cBJT1C3YzXCsXwORQs1ovw
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





