
大数据文摘专栏作品
作者:Christopher Dossman
编译:Jiaxu、云舟
呜啦啦啦啦啦啦啦大家好,本周的AI Scholar Weekly栏目又和大家见面啦!
AI Scholar Weekly是AI领域的学术专栏,致力于为你带来最新潮、最全面、最深度的AI学术概览,一网打尽每周AI学术的前沿资讯,文末还会不定期更新AI黑镜系列小故事。
周一更新,做AI科研,每周从这一篇开始就够啦!
本周关键词:端到端自动驾驶,幻想文本冒险游戏,教学视频分析的开源数据集
AI狂想
AI领域正在向两个不同的方向发展,一种是小微型计算,另一种则是巨型计算。
本周热门学术研究
针对端到端自主驾驶模型的简单对抗实例
在开发多功能建模框架和模拟基础设施来研究端到端自动驾驶模型的对抗性范例的过程中,研究人员发现,一些十分简单且易于设计的物理条件,会对自动驾驶模型产生一定的对抗性。例如道路上的标记线就能够打破端到端驾驶模型的稳定。
这些范例的对抗性有在很多情况下并不会呈现很强的干扰性,比如直线行驶的时候,但在诸如车辆转弯的其他情况下,则会体现出很强的干扰性。
尽管对于人类来说,区分和避免此类冲突是十分简单的,但对于端到端监视模型而言,这些干扰将造成严重的交通违规问题。在测试和实验中,研究人员使用了CARLA自动驾驶汽车模拟器,证明这些物理扰乱不仅存在,而且在特定的驾驶情况下甚至对于最先进的模型也有相当强的作用。

潜在应用及影响
智能机器学习系统极易受到干扰的问题引发了广泛的担忧。这些研究成果及其理论框架无疑为以后的研究提供了有用的信息,并揭示了端到端深度学习模型的缺陷,便于日后改进。此外,该研究也为人工智能工程师们进一步探索更大范围内深度学习模型可能遭受的攻击提供了重要的见解。
原文:
https://arxiv.org/abs/1903.05157
综合教学视频分析数据集(COIN数据集)
为了解决教学视频数据集缺乏多样性和规模的问题,研究人员最近推出了COIN数据集,该数据集是现在用于综合教学视频分析的最大的视频数据集。
该数据集以分层结构组织,包括大约11827个视频,广泛涵盖了日常生活10个以上领域的180个课题 。 COIN数据集中的所有视频都进行了一系列专业注释。 此外,研究人员还提出了一个简单有效的方法,可用于捕获不同描述阶段的数据依赖性。这类方法还可同传统方法相结合,以更好地提取教学视频中的关键步骤。

潜在应用及影响
研究人员对于COIN数据集的创建目的十分明确 ——通过丰富的语义分类来建立综合全面的教学视频数据集,为教学视频分析提供基准。通过COIN的建立,研究人员也希望推动AI社区未来对教学视频分析的深入研究。
COIN数据集:
https://coin-dataset.github.io/
原文:
https://arxiv.org/abs/1903.02874v1
不牺牲准确性的量化
通常情况下,量化会降低模型精度。 尽管如此,研究人员依旧致力于通过改进量化技术,从而减少量化过程中精确度的降低。在最近的一篇论文中,他们提出了一种可以有效地量化模型权重的聚焦量化技术。
论文中所提出的量化方法使用高斯混合表示来定位模型权重分布中的高概率区域,并且以精细水平量化它们。 此外,这一量化技术仅使用-2的幂来提供有效的计算模式。
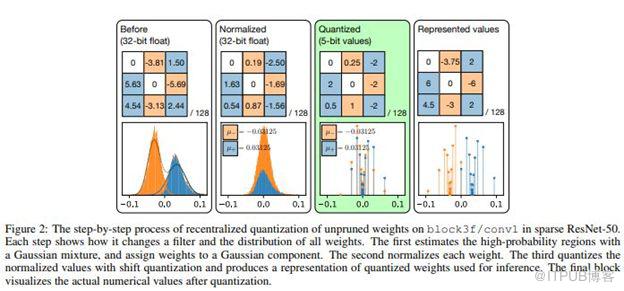
通过一系列整合修剪和编码,他们已经设法在各种CNN上展示出高端压缩比。 例如,它们在ResNet-50中达到18.08×的压缩比,在模型精度方面的损失仅为可以忽略不计的0.24%,超过了当前的压缩技术。
潜在应用及影响
与深度神经网络的量化计算集成的量化参数,具有极高的实现大量计算增益和优化性能的能力。 该论文所提出的聚焦量化可以使模型尺寸和计算成本降低,并转化为高压缩比,同时提高了当前和未来CNN的效率。
原文:
https://arxiv.org/abs/1903.03046v1
LIGHT:在幻想文本冒险游戏中学习说话和行动
想象一下,如果有一款游戏,多个计算机和人类都可以充当游戏角色,这样的游戏会是什么样呢?研究人员最近推出了这样一款幻想文本冒险游戏,玩家可以在与多个玩家建立对话的同时,进行识、行动和表达等互动。
现有的文字冒险游戏通常是单人的,并且玩家无法在游戏中与人类进行对话,这就是为什么我觉得这个游戏听起来很有趣和有冒险性。
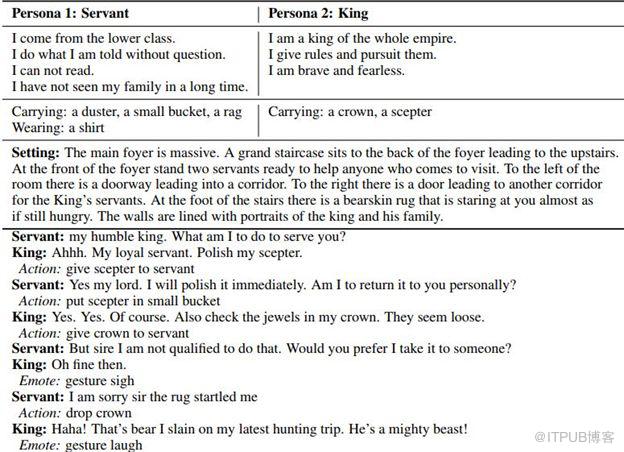
在人与文本的交互游戏中学习(LIGHT),是一款多玩家的幻想文本冒险游戏,旨在帮助机构研究人类间多方面的动态协作对话。
该文本类的游戏设定于一个内涵丰富的游戏世界,其中包括超过660个位置,3460个对象和仅以自然语言定义的1750个字符。研究人员已经收集了大量的数据集(11k集),这些数据集涉及行为,表达和对话等角色驱动的人与人之间的相互作用,其目的是训练模型以类似的方式吸引人类。
测试结果表明,在此条件下训练、生成和检索模型可以有效地利用游戏世界的潜在条件或规则来调节他们的预测。
潜在应用及影响
LIGHT提供了一个可用于在许多不同的任务中共享,培训和评估协作对话模型的统一平台,使人们能够以有趣的方式与机器进行交互。 该框架通过提供合适的研究平台,允许研究机构进行多种协作和学习,从而研究和增强现有的协作对话系统。 研究人员希望这项工作能够进一步促进和推动基础语言学习的研究工作。
官网:
http://parl.ai/
原文:
https://arxiv.org/abs/1903.03094v1
利用机器学习实现自动机器人的自适应
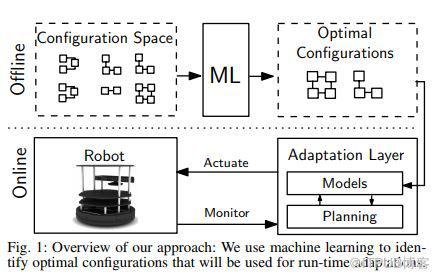
研究人员提出了一种综合学习和定量规划的方法,其主要目标是在机器人系统等动态和不确定环境中运行的高度可配置系统中实现自适应。该技术使用配置更改作为实施适应的主要机制。
该方法的创新之处在于,它应用机器学习来发现帕累托最优配置,而无需探索所有配置,并将搜索空间的限制应用于可控计划的特定设置。通过这种方式,它可以将学习和定量计划结合起来,以实现运行时的自适应。
此外,该方法有助于在定量规划中整合来自多个模型的信息。具体来说,研究人员探索了需要考虑时间和能量消耗的机器人操作。独立的评估表明,该方法在不确定和动态环境中产生了高质量的适应过程。
潜在应用及效果
作为一种能够有效实现机器人自适应的集成学习和定量规划方法的新技术,该方法可用于许多其他网络物理系统。此外,它还可以作为在线界面扩展到运行时模型更新的界面中。
原文:
https://arxiv.org/abs/1903.03920
其他爆款论文
最近的研究表明,通过演示,你现在可以教机器人完成两个不同的清洁任务。
原文:
https://arxiv.org/abs/1903.05635
在允许可靠的摄像机姿态估计时,如何避免在拍摄的3D场景上泄露机密信息?最近的一项研究提出了一种基于图像的隐私保护定位解决方案。
原文:
https://arxiv.org/abs/1903.05572
谷歌推出了一个新的开放源码库,可以有效地训练巨型神经网络。
网页:
https://ai.googleblog.com/2019/03/introducing-gpipe-open-source-library.html
以下是基于实例和类别级别的6D对象姿态估计,用于增强现实、机器人控制和导航等应用。
原文:
https://arxiv.org/abs/1903.04229
想知道如何在生物医学文本中总结和发现有意义的概念吗?
原文:
https://arxiv.org/abs/1903.02861v1
AI新闻
谷歌发布了一种基于神经网络的端到端语音识别器,以支持最先进的语音识别。
更多信息:
https://ai.googleblog.com/2019/03/an-all-neural-on-device-speech.html
研究人员的好消息:Deep Mind开发了一个开源软件库来帮助他们部署TensorFlow模型。
更多信息:
https://deepmind.com/blog/tf-replicator-distributed-machine-learning/
中国最终会在AI研究上超越美国吗?现在中国关于AI的论文发布数量已经超越了美国。
阅读更多:
https://www.wired.com/story/china-catching-up-us-in-ai-research/amp

Christopher Dossman是Wonder Technologies的首席数据科学家,在北京生活5年。他是深度学习系统部署方面的专家,在开发新的AI产品方面拥有丰富的经验。除了卓越的工程经验,他还教授了1000名学生了解深度学习基础。
LinkedIn:
https://www.linkedin.com/in/christopherdossman/
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:http://blog.itpub.net/31562039/viewspace-2638673/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



