概述
在进行网站爬取数据的时候,会发现很多网站都进行了反爬虫的处理,如JS加密,Ajax加密,反Debug等方法,通过请求获取数据和页面展示的内容完全不同,这时候就用到Selenium技术,来模拟浏览器的操作,然后获取数据。本文以一个简单的小例子,简述Python搭配Tkinter和Selenium进行浏览器的模拟操作,仅供学习分享使用,如有不足之处,还请指正。
什么是Selenium?
Selenium是一个用于Web应用程序测试的工具,Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。Selenium支持多种操作系统,如Windows、Linux、IOS等,如果需要支持Android,则需要特殊的selenium,本文主要以IE11浏览器为例。
安装Selenium
通过pip install selenium 进行安装即可,如果速度慢,则可以使用国内的镜像进行安装。
涉及知识点
程序虽小,除了需要掌握的Html ,JavaScript,CSS等基础知识外,本例涉及的Python相关知识点还是蛮多的,具体如下:
Selenium进行元素定位,主要有ID,Name,ClassName,Css Selector,Partial LinkText,LinkText,XPath,TagName等8种方式。
Selenium获取单一元素(如:find_element_by_xpath)和获取元素数组(如:find_elements_by_xpath)两种方式。
Selenium元素定位后,可以给元素进行赋值和取值,或者进行相应的事件操作(如:click)。
为了防止前台页面卡主,本文用到了线程进行后台操作,如果要定义一个新的线程,只需要定义一个类并继承threading.Thread,然后重写run方法即可。
在使用线程的过程中,为了保证线程的同步,本例用到了线程锁,如:threading.Lock()。
本例将Selenium执行的过程信息,保存到对列中,并通过线程输出到页面显示。queue默认先进先出方式。
对列通过put进行压栈,通过get进行出栈。通过qsize()用于获取当前对列元素个数。
为了保存Selenium执行过程中的日志,本例用到了日志模块,为Pyhton自带的模块,不需要额外安装。
Python的日志共六种级别,分别是:NOTSET,DEBUG,INFO,WARN,ERROR,FATAL,CRITICAL。
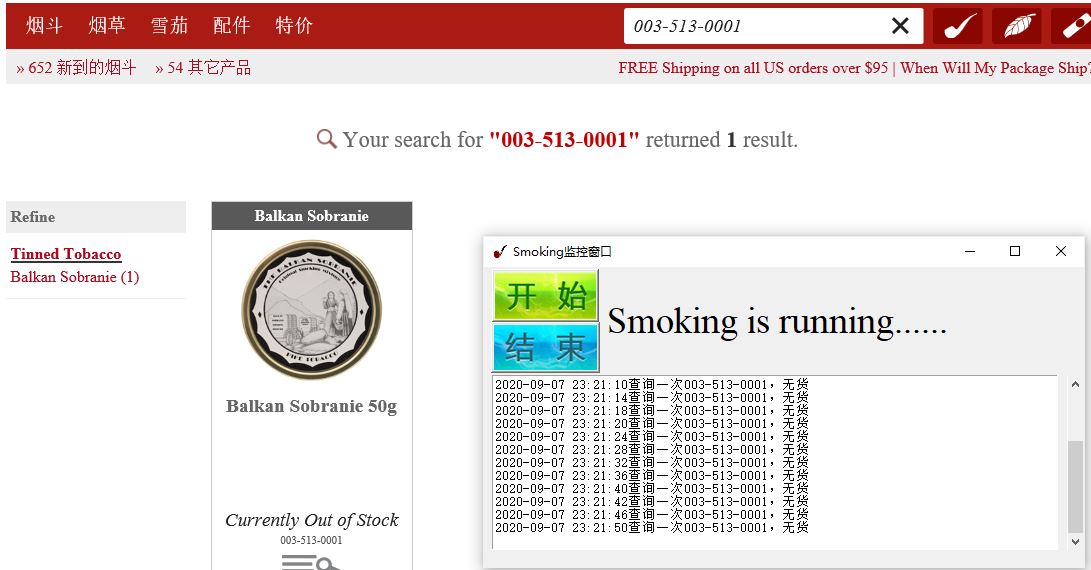
示例效果图
本例主要针对某一配置好的商品ID进行轮询,监控是否有货,有货则加入购物车,无货则继续轮询,如下图所示:
核心代码
本例最核心的代码,就是利用Selenium进行网站的模拟操作,如下所示:
class Smoking:
"""定义Smoking类"""
# 浏览器驱动
__driver: webdriver = None
# 配置帮助类
__cfg_info: dict = {}
# 日志帮助类
__log_helper: LogHelper = None
# 主程序目录
__work_path: str = ''
# 是否正在运行
__running: bool = False
# 无货
__no_stock = 'Currently Out of Stock'
# 线程等待秒数
__wait_sec = 2
def __init__(self, work_path, cfg_info, log_helper: LogHelper):
"""初始化"""
self.__cfg_info = cfg_info
self.__log_helper = log_helper
self.__work_path = work_path
self.__wait_sec = int(cfg_info['wait_sec'])
# 如果小于2,则等于2
self.__wait_sec = (2 if self.__wait_sec < 2 else self.__wait_sec)
def checkIsExistsById(self, id):
"""通过ID判断是否存在"""
try:
i = 0
while self.__running and i < 3:
if len(self.__driver.find_elements_by_id(id)) > 0:
break
else:
time.sleep(self.__wait_sec)
i = i + 1
return len(self.__driver.find_elements_by_id(id)) > 0
except BaseException as e:
return False
def checkIsExistsByName(self, name):
"""通过名称判断是否存在"""
try:
i = 0
while self.__running and i < 3:
if len(self.__driver.find_elements_by_name(name)) > 0:
break
else:
time.sleep(self.__wait_sec)
i = i + 1
return len(self.__driver.find_elements_by_name(name)) > 0
except BaseException as e:
return False
def checkIsExistsByPath(self, path):
"""通过xpath判断是否存在"""
try:
i = 0
while self.__running and i < 3:
if len(self.__driver.find_elements_by_xpath(path)) > 0:
break
else:
time.sleep(self.__wait_sec)
i = i + 1
return len(self.__driver.find_elements_by_xpath(path)) > 0
except BaseException as e:
return False
def checkIsExistsByClass(self, cls):
"""通过class名称判断是否存在"""
try:
i = 0
while self.__running and i < 3:
if len(self.__driver.find_elements_by_class_name(cls)) > 0:
break
else:
time.sleep(self.__wait_sec)
i = i + 1
return len(self.__driver.find_elements_by_class_name(cls)) > 0
except BaseException as e:
return False
def checkIsExistsByLinkText(self, link_text):
"""判断LinkText是否存在"""
try:
i = 0
while self.__running and i < 3:
if len(self.__driver.find_elements_by_link_text(link_text)) > 0:
break
else:
time.sleep(self.__wait_sec)
i = i + 1
return len(self.__driver.find_elements_by_link_text(link_text)) > 0
except BaseException as e:
return False
def checkIsExistsByPartialLinkText(self, link_text):
"""判断包含LinkText是否存在"""
try:
i = 0
while self.__running and i < 3:
if len(self.__driver.find_elements_by_partial_link_text(link_text)) > 0:
break
else:
time.sleep(self.__wait_sec)
i = i + 1
return len(self.__driver.find_elements_by_partial_link_text(link_text)) > 0
except BaseException as e:
return False
# def waiting(self, *locator):
# """等待完成"""
# # self.__driver.switch_to.window(self.__driver.window_handles[1])
# Wait(self.__driver, 60).until(EC.visibility_of_element_located(locator))
def login(self, username, password):
"""登录"""
# 5. 点击链接跳转到登录页面
self.__driver.find_element_by_link_text('账户登录').click()
# 6. 输入账号密码
# 判断是否加载完成
# self.waiting((By.ID, "email"))
if self.checkIsExistsById('email'):
self.__driver.find_element_by_id('email').send_keys(username)
self.__driver.find_element_by_id('password').send_keys(password)
# 7. 点击登录按钮
self.__driver.find_element_by_id('sign-in').click()
def working(self, item_id):
"""工作状态"""
while self.__running:
try:
# 正常获取信息
if self.checkIsExistsById('string'):
self.__driver.find_element_by_id('string').clear()
self.__driver.find_element_by_id('string').send_keys(item_id)
self.__driver.find_element_by_id('string').send_keys(Keys.ENTER)
# 判断是否查询到商品
xpath = "//div[@class='specialty-header search']/div[@class='specialty-description']/div[" \
"@class='gt-450']/span[2] "
if self.checkIsExistsByPath(xpath):
count = int(self.__driver.find_element_by_xpath(xpath).text)
if count < 1:
time.sleep(self.__wait_sec)
self.__log_helper.put('没有查询到item id =' + item_id + '对应的信息')
continue
else:
time.sleep(self.__wait_sec)
self.__log_helper.put('没有查询到item id2 =' + item_id + '对应的信息')
continue
# 判断当前库存是否有货
xpath2 = "//div[@class='product-list']/div[@class='product']/div[@class='price-and-detail']/div[" \
"@class='price']/span[@class='noStock'] "
if self.checkIsExistsByPath(xpath2):
txt = self.__driver.find_element_by_xpath(xpath2).text
if txt == self.__no_stock:
# 当前无货
time.sleep(self.__wait_sec)
self.__log_helper.put('查询一次' + item_id + ',无货')
continue
# 链接path2
xpath3 = "//div[@class='product-list']/div[@class='product']/div[@class='imgDiv']/a"
# 判断是否加载完毕
# self.waiting((By.CLASS_NAME, "imgDiv"))
if self.checkIsExistsByPath(xpath3):
self.__driver.find_element_by_xpath(xpath3).click()
time.sleep(self.__wait_sec)
# 加入购物车
if self.checkIsExistsByClass('add-to-cart'):
self.__driver.find_element_by_class_name('add-to-cart').click()
self.__log_helper.put('加入购物车成功,商品item-id:' + item_id)
break
else:
self.__log_helper.put('未找到加入购物车按钮')
else:
self.__log_helper.put('没有查询到,可能是商品编码不对,或者已下架')
except BaseException as e:
self.__log_helper.put(e)
def startRun(self):
"""运行起来"""
try:
self.__running = True
url: str = self.__cfg_info['url']
username = self.__cfg_info['username']
password = self.__cfg_info['password']
item_id = self.__cfg_info['item_id']
if url is None or len(url) == 0 or username is None or len(username) == 0 or password is None or len(
password) == 0 or item_id is None or len(item_id) == 0:
self.__log_helper.put('配置信息不全,请检查config.cfg文件是否为空,然后再重启')
return
if self.__driver is None:
options = webdriver.IeOptions()
options.add_argument('encoding=UTF-8')
options.add_argument('Accept= text / css, * / *')
options.add_argument('Accept - Language= zh - Hans - CN, zh - Hans;q = 0.5')
options.add_argument('Accept - Encoding= gzip, deflate')
options.add_argument('user-agent=Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko')
# 2. 定义浏览器驱动对象
self.__driver = webdriver.Ie(executable_path=self.__work_path + r'\IEDriverServer.exe', options=options)
self.run(url, username, password, item_id)
except BaseException as e:
self.__log_helper.put('运行过程中出错,请重新打开再试')
def run(self, url, username, password, item_id):
"""运行起来"""
# 3. 访问网站
self.__driver.get(url)
# 4. 最大化窗口
self.__driver.maximize_window()
if self.checkIsExistsByLinkText('账户登录'):
# 判断是否登录:未登录
self.login(username, password)
if self.checkIsExistsByPartialLinkText('欢迎回来'):
# 判断是否登录:已登录
self.__log_helper.put('登录成功,下一步开始工作了')
self.working(item_id)
else:
self.__log_helper.put('登录失败,请设置账号密码')
def stop(self):
"""停止"""
try:
self.__running = False
# 如果驱动不为空,则关闭
self.close_browser_nicely(self.__driver)
if self.__driver is not None:
self.__driver.quit()
# 关闭后切要为None,否则启动报错
self.__driver = None
except BaseException as e:
print('Stop Failure')
finally:
self.__driver = None
def close_browser_nicely(self, browser):
try:
browser.execute_script("window.onunload=null; window.onbeforeunload=null")
except Exception as err:
print("Fail to execute_script:'window.onunload=null; window.onbeforeunload=null'")
socket.setdefaulttimeout(10)
try:
browser.quit()
print("Close browser and firefox by calling quit()")
except Exception as err:
print("Fail to quit from browser, error-type:%s, reason:%s" % (type(err), str(err)))
socket.setdefaulttimeout(30)
其他辅助类
日志类(LogHelper),代码如下:
class LogHelper:
"""日志帮助类"""
__queue: queue.Queue = None # 队列
__logging: logging.Logger = None # 日志
__running: bool = False # 是否记录日志
def __init__(self, log_path):
"""初始化类"""
self.__queue = queue.Queue(1000)
self.init_log(log_path)
def put(self, value):
"""添加数据"""
# 记录日志
self.__logging.info(value)
# 添加到队列
if self.__queue.qsize() < self.__queue.maxsize:
self.__queue.put(value)
def get(self):
"""获取数据"""
if self.__queue.qsize() > 0:
try:
return self.__queue.get(block=False)
except BaseException as e:
return None
else:
return None
def init_log(self, log_path):
"""初始化日志"""
self.__logging = logging.getLogger()
self.__logging.setLevel(logging.INFO)
# 日志
rq = time.strftime('%Y%m%d%H%M', time.localtime(time.time()))
log_name = log_path + rq + '.log'
logfile = log_name
# if not os.path.exists(logfile):
# # 创建空文件
# open(logfile, mode='r')
fh = logging.FileHandler(logfile, mode='a', encoding='UTF-8')
fh.setLevel(logging.DEBUG) # 输出到file的log等级的开关
# 第三步,定义handler的输出格式
formatter = logging.Formatter("%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s")
fh.setFormatter(formatter)
# 第四步,将logger添加到handler里面
self.__logging.addHandler(fh)
def get_running(self):
# 获取当前记录日志的状态
return self.__running
def set_running(self, v: bool):
# 设置当前记录日志的状态
self.__running = v
配置类(ConfigHelper)
class ConfigHelper:
"""初始化数据类"""
__config_dir = None
__dic_cfg = {}
def __init__(self, config_dir):
"""初始化"""
self.__config_dir = config_dir
def ReadConfigInfo(self):
"""得到配置项"""
parser = ConfigParser()
parser.read(self.__config_dir + r"\config.cfg")
section = parser.sections()[0]
items = parser.items(section)
self.__dic_cfg.clear()
for item in items:
self.__dic_cfg.__setitem__(item[0], item[1])
def getConfigInfo(self):
"""获取配置信息"""
if len(self.__dic_cfg) == 0:
self.ReadConfigInfo()
return self.__dic_cfg
线程类(MyThread)
class MyThread(threading.Thread):
"""后台监控线程"""
def __init__(self, tid, name, smoking: Smoking, log_helper: LogHelper):
"""线程初始化"""
threading.Thread.__init__(self)
self.threadID = tid
self.name = name
self.smoking = smoking
self.log_helper = log_helper
def run(self):
print("开启线程: " + self.name)
self.log_helper.put("开启线程: " + self.name)
# 获取锁,用于线程同步
# lock = threading.Lock()
# lock.acquire()
self.smoking.startRun()
# 释放锁,开启下一个线程
# lock.release()
print("结束线程: " + self.name)
self.log_helper.put("结束线程: " + self.name)
备注
侠客行 [唐:李白]赵客缦胡缨,吴钩霜雪明。银鞍照白马,飒沓如流星。
十步杀一人,千里不留行。事了拂衣去,深藏身与名。
闲过信陵饮,脱剑膝前横。将炙啖朱亥,持觞劝侯嬴。
三杯吐然诺,五岳倒为轻。眼花耳热后,意气素霓生。
救赵挥金槌,邯郸先震惊。千秋二壮士,烜赫大梁城。
纵死侠骨香,不惭世上英。谁能书阁下,白首太玄经。
到此这篇关于Python使用Selenium模拟浏览器自动操作的文章就介绍到这了,更多相关Python模拟浏览器自动操作内容请搜索亿速云以前的文章或继续浏览下面的相关文章希望大家以后多多支持亿速云!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





