如何使用pycharm实现连接Databricks?针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
在本地使用pycharm连接databricks,大致步骤如下:
首先,为了让本地环境能够识别远端的databricks集群环境,需要收集databricks的基本信息和自己databricks的token,这些信息能够让本地环境识别databricks;接着,需要使用到工具 anaconda创建一个虚拟环境,连接databricks;最后,将虚拟环境导入pycharm。
(下面的图渣渣,因为直接拖进来的)
第0步:检查
检查java版本,需要时1.8开头的版本,如果不是,请到这里下载:https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html

第1步:收集databricks的信息
查看python版本 (还不知道怎么看,这里cluster的python版本为3.7)
查看Runtime Version
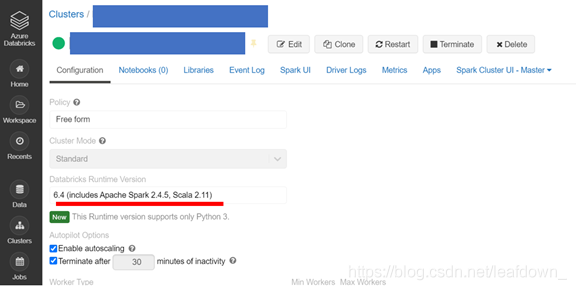
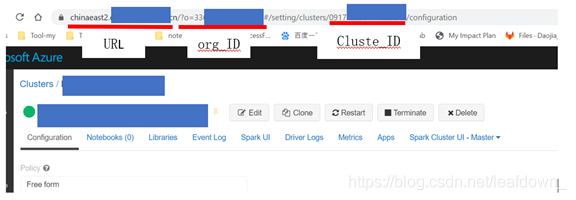
查看cluster ulr,解析出下面信息
生成token,点击这个小人-user setting
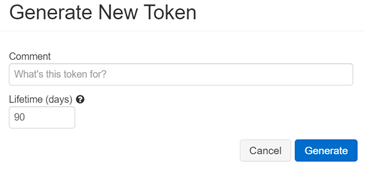
最后,这是我们收集到的所有信息
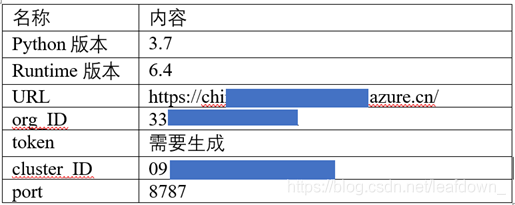
第2步:安装anaconda
如果已经安装anaconda,请略过这一步
没有安装,可以看这个教程
https://www.jb51.net/article/196286.htm
第3步:使用anaconda创建虚拟环境
下面的参数信息,使用第一步收集的信息
打开anaconda的命令行
创建一个3.7版本的虚拟隔离环境
conda create -n dbconnect python=3.7

使用环境
conda activate dbconnect

卸载pyspark,如果是新创建的环境,可以不用执行这步(这是为了确保,创建的环境不能有pyspark的包,因为会产生包的问题)
pip uninstall pyspark
下面开始安装包,但是为了让安装速度快一些,使用清华镜像
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro/ conda config --set show_channel_urls yes
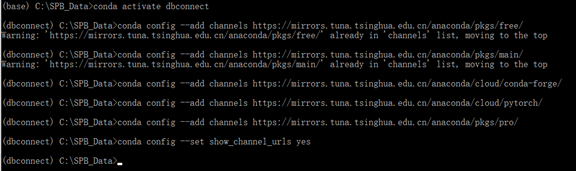
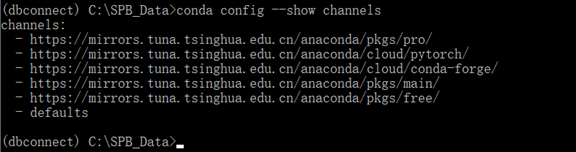
查看是否切换到镜像
conda config --show channels
可以看到已经切换
安装connect包,第一步中确定的run的版本为6.4,故选择6.4.* (用公司的网络,下载很慢,我用自己的热点)
pip install -U databricks-connect==6.4.*

连接远端databricks,并输入第一步收集的相关信息
databricks-connect configure
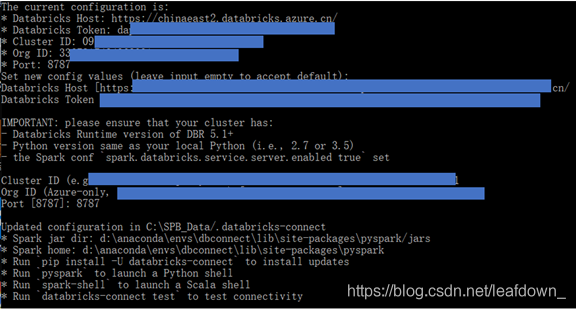
测试是否已经连接上:
databricks-connect test
已经在启动节点了

查看databricks,可以看到

第4步:pycharm导入虚拟环境
打开pycahrm,点击setting
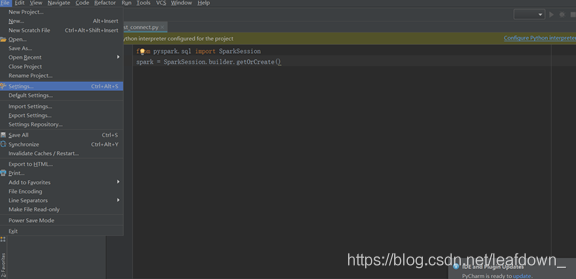
选择解释器,点击小齿轮的add'
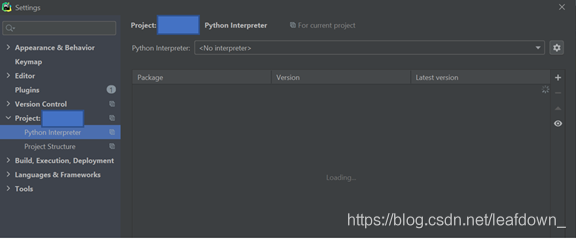
选择刚才我们创建好的dbconnect

点击ok,可以看到已经选好了环境
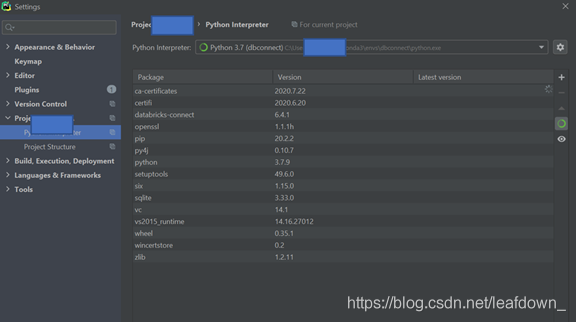
不知道为啥连接不到远端的包,我的项目还需要在本地安装一些用的包
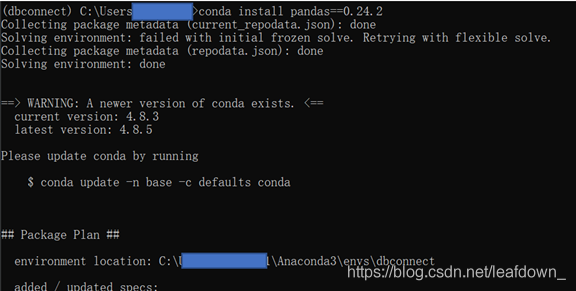
conda install scikit-learn==0.22.1 conda install pandas==0.24.2 conda install pyarrow==0.15.1
在pycharm测试运行一下:
import pandas as pd import numpy as np # Generate a pandas DataFrame pdf = pd.DataFrame(np.random.rand(100, 3)) from pyspark.sql import * spark = SparkSession.builder.getOrCreate() df = spark.createDataFrame(pdf) print(df.head(5))
去databrick的cluster log看一下,已经启动了节点,正在运行

关于如何使用pycharm实现连接Databricks问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





