这篇文章主要介绍用python爬虫scrapy框架中获取内容对的示例,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
Items介绍
爬取的主要目标就是从非结构性的数据源提取结构性数据,例如网页。 Scrapy spider可以以python的dict来返回提取的数据.虽然dict很方便,并且用起来也熟悉,但是其缺少结构性,容易打错字段的名字或者返回不一致的数据,尤其在具有多个spider的大项目中。
为了定义常用的输出数据,Scrapy提供了 Item 类。 Item 对象是种简单的容器,保存了爬取到得数据。 其提供了 类似于词典(dictionary-like) 的API以及用于声明可用字段的简单语法。
许多Scrapy组件使用了Item提供的额外信息: exporter根据Item声明的字段来导出数据、 序列化可以通过Item字段的元数据(metadata)来定义、 trackref 追踪Item实例来帮助寻找内存泄露 (see 使用 trackref 调试内存泄露) 等等。
Item 对象是种简单的容器,保存了爬取到得数据。 其提供了 类似于词典(dictionary-like) 的API以及用于声明可用字段的简单语法。
在Scrapy中,items是用来加载抓取内容的容器,提供了一些额外的保护减少错误。
一般来说,item可以用scrapy.item.Item类来创建,并且用scrapy.item.Field对象来定义属性。
接下来,我们开始来构建item模型(model)。
首先,我们想要的内容有:
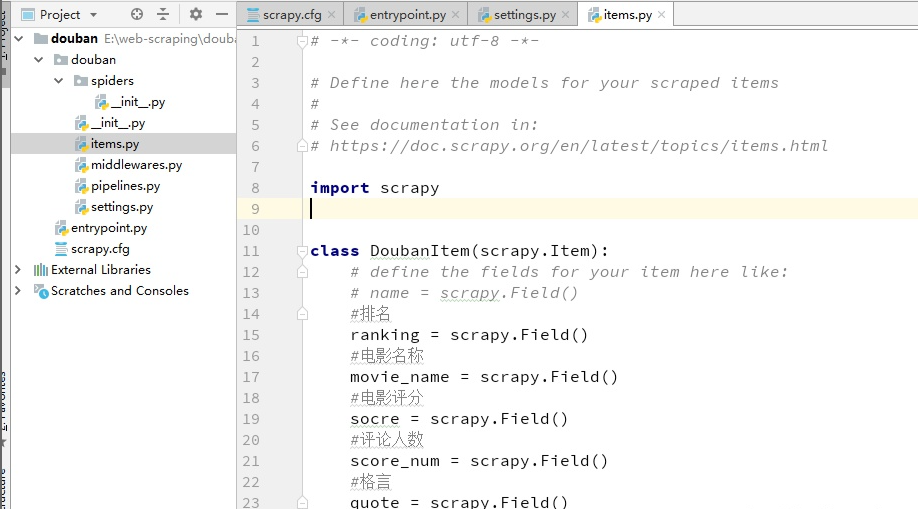
排名(ranking)
电影名称(movie_name)
电影评分(score)
评论人数(score_num)
格言(quote)
Item使用简单的class定义语法以及Field对象来声明。我们打开scrapyspider目录下的items.py文件写入下列代码声明Item:
以上是用python爬虫scrapy框架中获取内容对的示例的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://www.py.cn/jishu/jichu/21101.html



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



