数据是互联网公司的核心资产,所以好多公司在架构设计上不仅要保证业务系统的高可用,同时还要考虑数据存储的高可用以及安全性。在职公司是一家创业型公司,之前的应用系统是由.Net 和SQLserver组合的架构,由于存在业务量的增长,技术部门采用Java重构整个应用系统。数据库选择开源数据库MYSQL,从刚开始都现在踩了相当多的坑,在此给大家分享一下。
环境介绍:
磁盘类型:SSD
操作系统:CentOS6.5 64位
软件版本:5.5.50-MariaDB-wsrep
1、数据库高可用方案选型
目前针对mysql的高可用方案还是比较多,例如主从、MMM或者MHA等 ,我们初期考虑使用Keepalived+Mysql(双主热备)方案,但是由于阿里云不能很好的支持虚拟IP,所以想着使用其他方案,最好有集群解决方案,最后选用MariaDBGalera Cluster。3个节点组成一个集群,前端使用阿里云SLB实现负载均衡,减轻数据库压力。
MariaDB Galera Cluster主要功能
同步复制
真正的multi-master,即所有节点可以同时读写数据库
自动的节点成员控制,失效节点自动被清除
新节点加入数据自动复制
真正的并行复制,行级
用户可以直接连接集群,使用感受上与MySQL完全一致
优势:
因为是多主,所以不存在Slavelag(延迟)
不存在丢失事务的情况
同时具有读和写的扩展能力
更小的客户端延迟
节点间数据是同步的,而Master/Slave模式是异步的,不同slave上的binlog可能是不同的
线上环境数据库架构图
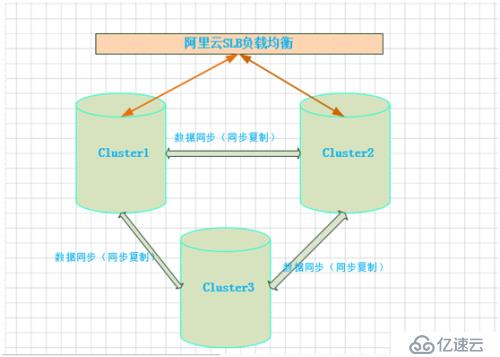
1、cluster1与cluster2由SLB调度,实现数据库负载均衡,应用程序可以连接cluster1和cluster2写入和读取。Slave3主要实现数据校验和备份。
踩过的坑:
1、数据容量规划严重不合理
由于是创业公司,研发人员和运维人员经验不足,在整个系统设计服务器采购时磁盘容量规划不合理,数据增长迅速,容量不足,最后采取添加硬盘,由于服务器是使用的阿里云主机,所以想着磁盘扩容比较简单,从阿里云控制台购买磁盘容量后,重启主机(远程连接reboot重启),用fdisk等命令检查磁盘,发现扩容的部分没有生效,折腾好久,最后给阿里云售后打电话解决,更改硬件配置需要在阿里云控制台重启。
2、mysql独立表空间和共享表空间
这个坑也是在上面容量使用上发现的,因为部分mysql默认使用独立表空间,而5.5.50-MariaDB-wsrep是默认使用共享表空间,由于前期经验不足,没有更改这些,每天业务量比较大,所以数据量增长比较快,有一天发现mysql目录下. Ibdata文件已经是80多G,查找相关资料是独立表空间以及共享表空间问题,里面包含redo log以及每个表的数据和索引等。由于我们的数据存在时效性,所以超过一个月的就转移到历史库,然后将主库相关表删除,而共享表空间对这种大量删除的支持不是很好,所以我们将整个数据库的表空间进行转换。下面简单介绍一下独立表空间和共享表空间,
共享表空间: 某一个数据库的所有的表数据,索引文件全部放在一个文件中,默认这个共享表空间的文件路径在data目录下。默认的文件名为:ibdata1 初始化为10M。
独立表空间: 每一个表都将会生成以独立的文件方式来进行存储,每一个表都有一个.frm表描述文件,还有一个.ibd文件。其中这个文件包括了单独一个表的数据内容以及索引内容,默认情况下它的存储位置也是在表的位置之中。
两者之间的优缺点
共享表空间:
优点:
可以放表空间分成多个文件存放到各个磁盘上(表空间文件大小不受表大小的限制,如一个表可以分布在不同步的文件上)。数据和文件放在一起方便管理。
缺点:
所有的数据和索引存放到一个文件中以为着将有一个很常大的文件,虽然可以把一个大文件分成多个小文件,但是多个表及索引在表空间中混合存储,这样对于一个表做了大量删除操作后表空间中将会有大量的空隙,特别是对于统计分析,日值系统这类应用最不适合用共享表空间。
innodb_file_per_table=1 为使用独占表空间
innodb_file_per_table=0 为使用共享表空间
独立表空间优点:
1.每个表都有自已独立的表空间。
2.每个表的数据和索引都会存在自已的表空间中。
3.可以实现单表在不同的数据库中移动。
4.空间可以回收(除drop table操作处,表空不能自已回收)
a) Drop table操作自动回收表空间,如果对于统计分析或是日值表,删除大量数据后可以通过:alter table TableNameengine=innodb;回缩不用的空间。
b) 对于使innodb-plugin的Innodb使用turncate table也会使空间收缩。
c) 对于使用独立表空间的表,不管怎么删除,表空间的碎片不会太严重的影响性能,而且还有机会处理。
缺点:
单表增加过大,如超过100个G。
3、 共享表空间向独立表空间的转换
由于我们的数据有时效性,所以需要数据转移和对原来库的表删除,需要将
默认的共享表空间转换成独立表空间。
转换方案:
1、将数据mysqldump逻辑备份,更改配置文件,重启数据库,将之前的数据库drop掉,导入新的数据。
2、 直接更改配置文件重启数据库。
两者的区别
方案1是比较彻底的做法,但是数据量比较大是整个过程就会很慢,因为mysqldump的逻辑备份是备份成SQL整个过程比较费时间。而方案2 是比较折中的解决方案,这样做对已经创建的数据表结构不会有影响,后期创建的表结构才会使用独立表空间。
对我们来说方案1更彻底,数据量有200多G,由于我们的多数记录表是按月分表,部分数据可以成为冷数据(一般情况下不会更改)。所以我们将这些冷数据先备份出来,导入到其他库检验完整性,然后将部分业务停掉处理那些业务逻辑等数据。
4、 mysqldump数据分库备份
有经验的运维或者DBA肯定不会用mysqldump备份大量的数据因为很慢,但是我们由于经验不足在此又踩了一个坑。用脚本和定时任务的方式实现数据备份,每周6晚上2点备份,前期数据量比较小整个业务系统正常,后面当数据突破100多G后,就出现一个比较奇怪的事情,每周六早上应用系统总是异常,研发人员都很郁闷,感觉跟见鬼一样,经过多次出现该问题后就考虑数据备份,研究任务执行情况,发现确实是数据备份问题,后面就采取xtrabackup备份。
脚本:
#/bin/bash
MYUSER=mysqlback
MYPASS=databack***
#SOCKET=/data/3306/mysql.sock
MYLOGIN="mysql -u$MYUSER -p$MYPASS "
MYDUMP="mysqldump -u$MYUSER -p$MYPASS -B"
DATABASE="$($MYLOGIN -e "show databases;"|egrep -vi"Data|_schema|mysql")"
for dbname in $DATABASE
do
MYDIR=/data/backup/$dbname
[ ! -d $MYDIR ] &&mkdir -p $MYDIR
$MYDUMP $dbname|gzip>$MYDIR/${dbname}_$(date +%F).sql.gz
done5、共享表空间转换独立表空间更改数据库配置报错
配置文件: [server] # this is only for the mysqld standalone daemon [mysqld] skip-name-resolve character-set-server=utf8 datadir=/data/mysql wait_timeout=1800 interactive_timeout = 288000 max_allowed_packet = 1000M #max_connections=3000 max_connections=3000 character-set-server=utf8 #innodb_buffer_pool_size = 1000M innodb_additional_mem_pool_size = 200M innodb_flush_log_at_trx_commit=2 innodb_autoextend_increment=800M #innodb_log_buffer_size = 200M innodb_log_file_size = 100M key_buffer_size=800M read_buffer_size=600M thread_cache_size=64 innodb_file_per_table=1 #独立表空间 #innodb_flush_log_at_trx_commit=2 #innodb_log_file_size=1G #(日志文件) innodb_buffer_pool_size=6G
为了适当的优化数据库性能,所以将参数做了适当的调整,这时比较坑的问题就出现了,数据库集群只能启动其中的一台,另外的两台都是报错,这时肯定是查看日志解决问题,看下面日志是配置文件参数设置问题导致,将更改配置文件逐个检查,最后发现是有3个innodb_buffer_pool_size参数不一致(3台服务器集群 基本配置差不多,区别就是一台上面还有其他应用程序在运行,所以就将其设置的小一点,导致整个系统启动异常)
部分日志:
InnoDB: Error: log file ./ib_logfile0 is of different size 0 104857600 bytes
InnoDB: than specified in the .cnf file 0 1073741824 bytes!
InnoDB: Possible causes for this error:
(a) Incorrect log file is used or log file size is changed
(b) In case default size is used this log file is from 10.0
(c) Log file is corrupted or there was not enough disk space
In case (b) you need to set innodb_log_file_size = 48M
170412 23:53:26 [ERROR] Plugin 'InnoDB' init function returned error.
170412 23:53:26 [ERROR] Plugin 'InnoDB' registration as a STORAGE ENGINE failed.
170412 23:53:26 [Note] Plugin 'FEEDBACK' is disabled.
170412 23:53:26 [ERROR] Unknown/unsupported storage engine: innodb
170412 23:53:26 [ERROR] Aborting
170412 23:53:28 [Note] WSREP: Closing send monitor...
170412 23:53:28 [Note] WSREP: Closed send monitor.
170412 23:53:28 [Note] WSREP: gcomm: terminating thread
170412 23:53:28 [Note] WSREP: gcomm: joining thread
170412 23:53:28 [Note] WSREP: gcomm: closing backend
170412 23:53:29 [Note] WSREP: view(view_id(NON_PRIM,1d5436dc,2) memb {
1d5436dc,0
} joined {
} left {
} partitioned {
effca7a8,0免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





