公司基础架构这边想提取慢作业和获悉资源浪费的情况,所以装个dr elephant看看。LinkIn开源的系统,可以对基于yarn的mr和spark作业进行性能分析和调优建议。
DRE大部分基于java开发,spark监控部分使用scala开发,使用play堆栈式框架。这是一个类似Python里面Django的框架,基于java?scala?没太细了解,直接下来就能用,需要java1.8以上。
prerequest list:
Java 1.8
PlayFramework+activator
Nodejs+npm
scala+sbt
编译服务器是设立在美国硅谷的某云主机,之前为了bigtop已经装好了java,maven,ant,scala,sbt等编译工具,所以下载activator解压放到/usr/local并加入PATH即可。
然后从 github clone一份dr-elephant下来,打开compile.conf,修改hadoop和spark版本为当前使用版本,:wq保存退出,运行compile.sh进行编译,经过短暂的等待之后,因为美国服务器,下依赖快。会有个dist文件夹,里面会打包一个dr-elephant-2.0.x.zip,拷出来解压缩就可以用了。
DRE本身需要mysql 5.5以上支持,或者mariadb最新的10.1稳定版本亦可。这里会有一个问题,就是在DRE/conf/evolutions/default/1.sql里面的这三行:
create index yarn_app_result_i4 on yarn_app_result (flow_exec_id);
create index yarn_app_result_i5 on yarn_app_result (job_def_id);
create index yarn_app_result_i6 on yarn_app_result (flow_def_id);由于在某些数据库情况下,索引长度会超过数据库本身的限制,所以,需要修改索引长度来避免无法启动的情况发生。
create index yarn_app_result_i4 on yarn_app_result (flow_exec_id(150));
create index yarn_app_result_i5 on yarn_app_result (job_def_id(150));
create index yarn_app_result_i6 on yarn_app_result (flow_def_id(150));然后就应该没啥问题了。
到数据库里创建一个叫drelephant的数据库,并给出相关访问权限用户
接下来是需要配置DRE:
打开app-conf/elephant.conf
# Play application server port
# 启动dre后play框架监听的web端口
port=8080
# Database configuration
# 数据库主机,用户名密码库名
db_url=localhost
db_name=drelephant
db_user="root"
db_password=其他默认即可,不需更改
然后是GeneralConf.xml
<configuration>
<property>
<name>drelephant.analysis.thread.count</name>
<value>3</value>
<description>Number of threads to analyze the completed jobs</description>
</property>
<property>
<name>drelephant.analysis.fetch.interval</name>
<value>60000</value>
<description>Interval between fetches in milliseconds</description>
</property>
<property>
<name>drelephant.analysis.retry.interval</name>
<value>60000</value>
<description>Interval between retries in milliseconds</description>
</property>
<property>
<name>drelephant.application.search.match.partial</name>
<value>true</value>
<description>If this property is "false", search will only make exact matches</description>
</property>
</configuration>修改drelephant.analysis.thread.count,默认是3,建议修改到10,3的话从jobhistoryserver读取的速度太慢,高于10的话又读取的太快,会对jobhistoryserver造成很大压力。下面两个一个是读取的时间周期,一个是重试读取的间隔时间周期。
然后到bin下执行start.sh启动。And then, show smile to the yellow elephant。
装完看了一下这个东西,其实本身原理并不复杂,就是读取各种jmx,metrics,日志信息,自己写一个也不是没有可能。功能主要是把作业信息里的内容汇总放到一屏里面显示,省的在JHS的页面里一个一个点了。
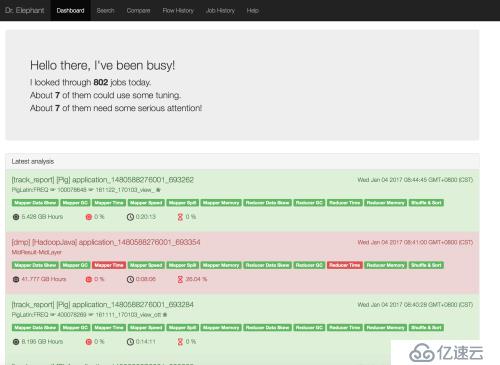
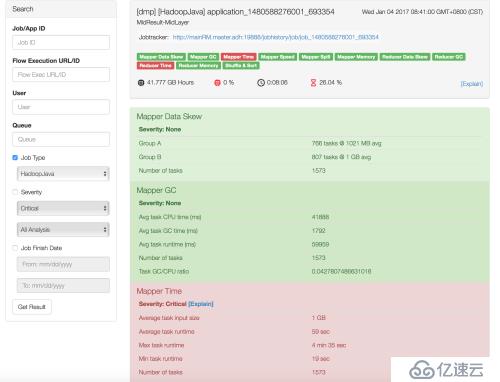
That's it, so easy
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



