HADOOPз”ҹжҖҒеңҲзҹҘиҜҶжҰӮиҝ°
дёҖ. hadoop з”ҹжҖҒжҰӮеҶө
HadoopжҳҜдёҖдёӘз”ұApacheеҹәйҮ‘дјҡжүҖејҖеҸ‘зҡ„еҲҶеёғејҸзі»з»ҹеҹәзЎҖжһ¶жһ„гҖӮз”ЁжҲ·еҸҜд»ҘеңЁдёҚдәҶи§ЈеҲҶеёғејҸеә•еұӮз»ҶиҠӮзҡ„жғ…еҶөдёӢпјҢејҖеҸ‘еҲҶеёғејҸзЁӢеәҸгҖӮе……еҲҶеҲ©з”ЁйӣҶзҫӨзҡ„еЁҒеҠӣиҝӣиЎҢй«ҳйҖҹиҝҗз®—е’ҢеӯҳеӮЁгҖӮе…·жңүеҸҜйқ гҖҒй«ҳж•ҲгҖҒеҸҜдјёзј©зҡ„зү№зӮ№гҖӮ
Hadoopзҡ„ж ёеҝғжҳҜYARN,HDFSе’ҢMapreduce
дёӢеӣҫжҳҜhadoopз”ҹжҖҒзі»з»ҹпјҢйӣҶжҲҗsparkз”ҹжҖҒеңҲгҖӮеңЁжңӘжқҘдёҖж®өж—¶й—ҙеҶ…пјҢhadoopе°ҶдәҺsparkе…ұеӯҳпјҢhadoopдёҺsparkйғҪиғҪйғЁзҪІеңЁyarnгҖҒmesosзҡ„иө„жәҗз®ЎзҗҶзі»з»ҹд№ӢдёҠгҖӮ
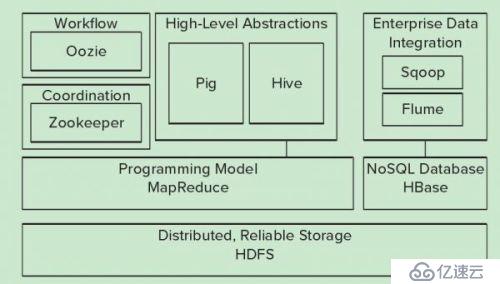
1гҖҒHDFSпјҲHadoopеҲҶеёғејҸж–Ү件系з»ҹпјү
жәҗиҮӘдәҺGoogleзҡ„GFSи®әж–ҮпјҢеҸ‘иЎЁдәҺ2003е№ҙ10жңҲпјҢHDFSжҳҜGFSе…ӢйҡҶзүҲгҖӮ
HDFSжҳҜHadoopдҪ“зі»дёӯж•°жҚ®еӯҳеӮЁз®ЎзҗҶзҡ„еҹәзЎҖгҖӮе®ғжҳҜдёҖдёӘй«ҳеәҰе®№й”ҷзҡ„зі»з»ҹпјҢиғҪжЈҖжөӢе’Ңеә”еҜ№зЎ¬д»¶ж•…йҡңпјҢз”ЁдәҺеңЁдҪҺжҲҗжң¬зҡ„йҖҡ用硬件дёҠиҝҗиЎҢгҖӮ
HDFSз®ҖеҢ–дәҶж–Ү件зҡ„дёҖиҮҙжҖ§жЁЎеһӢпјҢйҖҡиҝҮжөҒејҸж•°жҚ®и®ҝй—®пјҢжҸҗдҫӣй«ҳеҗһеҗҗйҮҸеә”з”ЁзЁӢеәҸж•°жҚ®и®ҝй—®еҠҹиғҪпјҢйҖӮеҗҲеёҰжңүеӨ§еһӢж•°жҚ®йӣҶзҡ„еә”з”ЁзЁӢеәҸгҖӮ
е®ғжҸҗдҫӣдәҶдёҖж¬ЎеҶҷе…ҘеӨҡж¬ЎиҜ»еҸ–зҡ„жңәеҲ¶пјҢж•°жҚ®д»Ҙеқ—зҡ„еҪўејҸпјҢеҗҢж—¶еҲҶеёғеңЁйӣҶзҫӨдёҚеҗҢзү©зҗҶжңәеҷЁдёҠгҖӮ
2гҖҒMapreduceпјҲеҲҶеёғејҸи®Ўз®—жЎҶжһ¶пјү
жәҗиҮӘдәҺgoogleзҡ„MapReduceи®әж–ҮпјҢеҸ‘иЎЁдәҺ2004е№ҙ12жңҲпјҢHadoopMapReduceжҳҜgoogle MapReduce е…ӢйҡҶзүҲгҖӮ
MapReduceжҳҜдёҖз§ҚеҲҶеёғејҸи®Ўз®—жЁЎеһӢпјҢз”Ёд»ҘиҝӣиЎҢеӨ§ж•°жҚ®йҮҸзҡ„и®Ўз®—гҖӮе®ғеұҸи”ҪдәҶеҲҶеёғејҸи®Ўз®—жЎҶжһ¶з»ҶиҠӮпјҢе°Ҷи®Ўз®—жҠҪиұЎжҲҗmapе’ҢreduceдёӨйғЁеҲҶпјҢ
е…¶дёӯMapеҜ№ж•°жҚ®йӣҶдёҠзҡ„зӢ¬з«Ӣе…ғзҙ иҝӣиЎҢжҢҮе®ҡзҡ„ж“ҚдҪңпјҢз”ҹжҲҗй”®-еҖјеҜ№еҪўејҸдёӯй—ҙз»“жһңгҖӮReduceеҲҷеҜ№дёӯй—ҙз»“жһңдёӯзӣёеҗҢвҖңй”®вҖқзҡ„жүҖжңүвҖңеҖјвҖқиҝӣиЎҢ规зәҰпјҢд»Ҙеҫ—еҲ°жңҖз»Ҳз»“жһңгҖӮ
MapReduceйқһеёёйҖӮеҗҲеңЁеӨ§йҮҸи®Ўз®—жңәз»„жҲҗзҡ„еҲҶеёғејҸ并иЎҢзҺҜеўғйҮҢиҝӣиЎҢж•°жҚ®еӨ„зҗҶгҖӮ
3. HBASEпјҲеҲҶеёғејҸеҲ—еӯҳж•°жҚ®еә“пјү
жәҗиҮӘGoogleзҡ„Bigtableи®әж–ҮпјҢеҸ‘иЎЁдәҺ2006е№ҙ11жңҲпјҢHBaseжҳҜGoogleBigtableе…ӢйҡҶзүҲгҖӮ
HBaseжҳҜдёҖдёӘе»әз«ӢеңЁHDFSд№ӢдёҠпјҢйқўеҗ‘еҲ—зҡ„й’ҲеҜ№з»“жһ„еҢ–ж•°жҚ®зҡ„еҸҜдјёзј©гҖҒй«ҳеҸҜйқ гҖҒй«ҳжҖ§иғҪгҖҒеҲҶеёғејҸе’Ңйқўеҗ‘еҲ—зҡ„еҠЁжҖҒжЁЎејҸж•°жҚ®еә“гҖӮ
HBaseйҮҮз”ЁдәҶBigTableзҡ„ж•°жҚ®жЁЎеһӢпјҡеўһејәзҡ„зЁҖз–ҸжҺ’еәҸжҳ е°„иЎЁпјҲKey/ValueпјүпјҢе…¶дёӯпјҢй”®з”ұиЎҢе…ій”®еӯ—гҖҒеҲ—е…ій”®еӯ—е’Ңж—¶й—ҙжҲіжһ„жҲҗгҖӮ
HBaseжҸҗдҫӣдәҶеҜ№еӨ§и§„жЁЎж•°жҚ®зҡ„йҡҸжңәгҖҒе®һж—¶иҜ»еҶҷи®ҝй—®пјҢеҗҢж—¶пјҢHBaseдёӯдҝқеӯҳзҡ„ж•°жҚ®еҸҜд»ҘдҪҝз”ЁMapReduceжқҘеӨ„зҗҶпјҢе®ғе°Ҷж•°жҚ®еӯҳеӮЁе’Ң并иЎҢи®Ўз®—е®ҢзҫҺең°з»“еҗҲеңЁдёҖиө·гҖӮ
4. ZookeeperпјҲеҲҶеёғејҸеҚҸдҪңжңҚеҠЎпјү
жәҗиҮӘGoogleзҡ„Chubbyи®әж–ҮпјҢеҸ‘иЎЁдәҺ2006е№ҙ11жңҲпјҢZookeeperжҳҜChubbyе…ӢйҡҶзүҲ
и§ЈеҶіеҲҶеёғејҸзҺҜеўғдёӢзҡ„ж•°жҚ®з®ЎзҗҶй—®йўҳпјҡз»ҹдёҖе‘ҪеҗҚпјҢзҠ¶жҖҒеҗҢжӯҘпјҢйӣҶзҫӨз®ЎзҗҶпјҢй…ҚзҪ®еҗҢжӯҘзӯү
Hadoopзҡ„и®ёеӨҡ组件дҫқиө–дәҺZookeeperпјҢе®ғиҝҗиЎҢеңЁи®Ўз®—жңәйӣҶзҫӨдёҠйқўпјҢз”ЁдәҺз®ЎзҗҶHadoopж“ҚдҪңгҖӮ
5. HIVEпјҲж•°жҚ®д»“еә“пјү
з”ұfacebookејҖжәҗпјҢжңҖеҲқз”ЁдәҺи§ЈеҶіжө·йҮҸз»“жһ„еҢ–зҡ„ж—Ҙеҝ—ж•°жҚ®з»ҹи®Ўй—®йўҳгҖӮ
Hiveе®ҡд№үдәҶдёҖз§Қзұ»дјјSQLзҡ„жҹҘиҜўиҜӯиЁҖ(HQL),е°ҶSQLиҪ¬еҢ–дёәMapReduceд»»еҠЎеңЁHadoopдёҠжү§иЎҢгҖӮйҖҡеёёз”ЁдәҺзҰ»зәҝеҲҶжһҗгҖӮ
HQLз”ЁдәҺиҝҗиЎҢеӯҳеӮЁеңЁHadoopдёҠзҡ„жҹҘиҜўиҜӯеҸҘпјҢHiveи®©дёҚзҶҹжӮүMapReduceејҖеҸ‘дәәе‘ҳд№ҹиғҪзј–еҶҷж•°жҚ®жҹҘиҜўиҜӯеҸҘпјҢ然еҗҺиҝҷдәӣиҜӯеҸҘиў«зҝ»иҜ‘дёәHadoopдёҠйқўзҡ„MapReduceд»»еҠЎгҖӮ
6.Pig(ad-hocи„ҡжң¬пјү
з”ұyahoo!ејҖжәҗпјҢи®ҫи®ЎеҠЁжңәжҳҜжҸҗдҫӣдёҖз§ҚеҹәдәҺMapReduceзҡ„ad-hoc(и®Ўз®—еңЁqueryж—¶еҸ‘з”ҹ)ж•°жҚ®еҲҶжһҗе·Ҙе…·
Pigе®ҡд№үдәҶдёҖз§Қж•°жҚ®жөҒиҜӯиЁҖвҖ”PigLatinпјҢе®ғжҳҜMapReduceзј–зЁӢзҡ„еӨҚжқӮжҖ§зҡ„жҠҪиұЎ,Pigе№іеҸ°еҢ…жӢ¬иҝҗиЎҢзҺҜеўғе’Ңз”ЁдәҺеҲҶжһҗHadoopж•°жҚ®йӣҶзҡ„и„ҡжң¬иҜӯиЁҖ(Pig Latin)гҖӮ
е…¶зј–иҜ‘еҷЁе°ҶPig Latinзҝ»иҜ‘жҲҗMapReduceзЁӢеәҸеәҸеҲ—е°Ҷи„ҡжң¬иҪ¬жҚўдёәMapReduceд»»еҠЎеңЁHadoopдёҠжү§иЎҢгҖӮйҖҡеёёз”ЁдәҺиҝӣиЎҢзҰ»зәҝеҲҶжһҗгҖӮ
7.Sqoop(ж•°жҚ®ETL/еҗҢжӯҘе·Ҙе…·пјү
SqoopжҳҜSQL-to-Hadoopзҡ„зј©еҶҷпјҢдё»иҰҒз”ЁдәҺдј з»ҹж•°жҚ®еә“е’ҢHadoopд№ӢеүҚдј иҫ“ж•°жҚ®гҖӮж•°жҚ®зҡ„еҜје…Ҙе’ҢеҜјеҮәжң¬иҙЁдёҠжҳҜMapreduceзЁӢеәҸпјҢе……еҲҶеҲ©з”ЁдәҶMRзҡ„并иЎҢеҢ–е’Ңе®№й”ҷжҖ§гҖӮ
SqoopеҲ©з”Ёж•°жҚ®еә“жҠҖжңҜжҸҸиҝ°ж•°жҚ®жһ¶жһ„пјҢз”ЁдәҺеңЁе…ізі»ж•°жҚ®еә“гҖҒж•°жҚ®д»“еә“е’ҢHadoopд№Ӣй—ҙиҪ¬з§»ж•°жҚ®гҖӮ
8.FlumeпјҲж—Ҙеҝ—收йӣҶе·Ҙе…·пјү
ClouderaејҖжәҗзҡ„ж—Ҙеҝ—收йӣҶзі»з»ҹпјҢе…·жңүеҲҶеёғејҸгҖҒй«ҳеҸҜйқ гҖҒй«ҳе®№й”ҷгҖҒжҳ“дәҺе®ҡеҲ¶е’Ңжү©еұ•зҡ„зү№зӮ№гҖӮ
е®ғе°Ҷж•°жҚ®д»Һдә§з”ҹгҖҒдј иҫ“гҖҒеӨ„зҗҶ并жңҖз»ҲеҶҷе…Ҙзӣ®ж Үзҡ„и·Ҝеҫ„зҡ„иҝҮзЁӢжҠҪиұЎдёәж•°жҚ®жөҒпјҢеңЁе…·дҪ“зҡ„ж•°жҚ®жөҒдёӯпјҢж•°жҚ®жәҗж”ҜжҢҒеңЁFlumeдёӯе®ҡеҲ¶ж•°жҚ®еҸ‘йҖҒж–№пјҢд»ҺиҖҢж”ҜжҢҒ收йӣҶеҗ„з§ҚдёҚеҗҢеҚҸи®®ж•°жҚ®гҖӮ
еҗҢж—¶пјҢFlumeж•°жҚ®жөҒжҸҗдҫӣеҜ№ж—Ҙеҝ—ж•°жҚ®иҝӣиЎҢз®ҖеҚ•еӨ„зҗҶзҡ„иғҪеҠӣпјҢеҰӮиҝҮж»ӨгҖҒж јејҸиҪ¬жҚўзӯүгҖӮжӯӨеӨ–пјҢFlumeиҝҳе…·жңүиғҪеӨҹе°Ҷж—Ҙеҝ—еҶҷеҫҖеҗ„з§Қж•°жҚ®зӣ®ж ҮпјҲеҸҜе®ҡеҲ¶пјүзҡ„иғҪеҠӣгҖӮ
жҖ»зҡ„жқҘиҜҙпјҢFlumeжҳҜдёҖдёӘеҸҜжү©еұ•гҖҒйҖӮеҗҲеӨҚжқӮзҺҜеўғзҡ„жө·йҮҸж—Ҙеҝ—收йӣҶзі»з»ҹгҖӮеҪ“然д№ҹеҸҜд»Ҙз”ЁдәҺ收йӣҶе…¶д»–зұ»еһӢж•°жҚ®
9. Oozie(е·ҘдҪңжөҒи°ғеәҰеҷЁпјү
OozieжҳҜдёҖдёӘеҸҜжү©еұ•зҡ„е·ҘдҪңдҪ“зі»пјҢйӣҶжҲҗдәҺHadoopзҡ„е Ҷж ҲпјҢз”ЁдәҺеҚҸи°ғеӨҡдёӘMapReduceдҪңдёҡзҡ„жү§иЎҢгҖӮе®ғиғҪеӨҹз®ЎзҗҶдёҖдёӘеӨҚжқӮзҡ„зі»з»ҹпјҢеҹәдәҺеӨ–йғЁдәӢ件жқҘжү§иЎҢпјҢеӨ–йғЁдәӢ件еҢ…жӢ¬ж•°жҚ®зҡ„е®ҡж—¶е’Ңж•°жҚ®зҡ„еҮәзҺ°гҖӮ
Oozieе·ҘдҪңжөҒжҳҜж”ҫзҪ®еңЁжҺ§еҲ¶дҫқиө–DAGпјҲжңүеҗ‘ж— зҺҜеӣҫ DirectAcyclic Graphпјүдёӯзҡ„дёҖз»„еҠЁдҪңпјҲдҫӢеҰӮпјҢHadoopзҡ„Map/ReduceдҪңдёҡгҖҒPigдҪңдёҡзӯүпјүпјҢе…¶дёӯжҢҮе®ҡдәҶеҠЁдҪңжү§иЎҢзҡ„йЎәеәҸгҖӮ
OozieдҪҝз”ЁhPDLпјҲдёҖз§ҚXMLжөҒзЁӢе®ҡд№үиҜӯиЁҖпјүжқҘжҸҸиҝ°иҝҷдёӘеӣҫгҖӮ
10. Yarn(еҲҶеёғејҸиө„жәҗз®ЎзҗҶеҷЁпјү
YARNжҳҜдёӢдёҖд»ЈMapReduceпјҢеҚіMRv2пјҢжҳҜеңЁз¬¬дёҖд»ЈMapReduceеҹәзЎҖдёҠжј”еҸҳиҖҢжқҘзҡ„пјҢдё»иҰҒжҳҜдёәдәҶи§ЈеҶіеҺҹе§ӢHadoopжү©еұ•жҖ§иҫғе·®пјҢдёҚж”ҜжҢҒеӨҡи®Ўз®—жЎҶжһ¶иҖҢжҸҗеҮәзҡ„гҖӮ
yarnжҳҜдёӢдёҖд»Ј Hadoop и®Ўз®—е№іеҸ°пјҢyarnжҳҜдёҖдёӘйҖҡз”Ёзҡ„иҝҗиЎҢж—¶жЎҶжһ¶пјҢз”ЁжҲ·еҸҜд»Ҙзј–еҶҷиҮӘе·ұзҡ„и®Ўз®—жЎҶжһ¶пјҢеңЁиҜҘиҝҗиЎҢзҺҜеўғдёӯиҝҗиЎҢгҖӮ
з”ЁдәҺиҮӘе·ұзј–еҶҷзҡ„жЎҶжһ¶дҪңдёәе®ўжҲ·з«Ҝзҡ„дёҖдёӘlibпјҢеңЁиҝҗз”ЁжҸҗдәӨдҪңдёҡж—¶жү“еҢ…еҚіеҸҜгҖӮиҜҘжЎҶжһ¶дёәжҸҗдҫӣдәҶд»ҘдёӢеҮ дёӘ组件пјҡ
иө„жәҗз®ЎзҗҶпјҡеҢ…жӢ¬еә”з”ЁзЁӢеәҸз®ЎзҗҶе’ҢжңәеҷЁиө„жәҗз®ЎзҗҶ
иө„жәҗеҸҢеұӮи°ғеәҰ
е®№й”ҷжҖ§пјҡеҗ„дёӘ组件еқҮжңүиҖғиҷ‘е®№й”ҷжҖ§
жү©еұ•жҖ§пјҡеҸҜжү©еұ•еҲ°дёҠдёҮдёӘиҠӮзӮ№
еҶ…еӯҳDAGи®Ўз®—жЁЎеһӢ)
SparkжҳҜдёҖдёӘApacheйЎ№зӣ®пјҢе®ғиў«ж ҮжҰңдёәвҖңеҝ«еҰӮй—Әз”өзҡ„йӣҶзҫӨи®Ўз®—вҖқгҖӮе®ғжӢҘжңүдёҖдёӘз№ҒиҚЈзҡ„ејҖжәҗзӨҫеҢәпјҢ并且жҳҜзӣ®еүҚжңҖжҙ»и·ғзҡ„ApacheйЎ№зӣ®гҖӮ
жңҖж—©SparkжҳҜUC BerkeleyAMP labжүҖејҖжәҗзҡ„зұ»Hadoop MapReduceзҡ„йҖҡз”Ёзҡ„并иЎҢи®Ўз®—жЎҶжһ¶гҖӮ
SparkжҸҗдҫӣдәҶдёҖдёӘжӣҙеҝ«гҖҒжӣҙйҖҡз”Ёзҡ„ж•°жҚ®еӨ„зҗҶе№іеҸ°гҖӮе’ҢHadoopзӣёжҜ”пјҢSparkеҸҜд»Ҙи®©дҪ зҡ„зЁӢеәҸеңЁеҶ…еӯҳдёӯиҝҗиЎҢж—¶йҖҹеәҰжҸҗеҚҮ100еҖҚпјҢжҲ–иҖ…еңЁзЈҒзӣҳдёҠиҝҗиЎҢж—¶йҖҹеәҰжҸҗеҚҮ10еҖҚ
12. KafkaпјҲеҲҶеёғејҸж¶ҲжҒҜйҳҹеҲ—пјү
KafkaжҳҜLinkedinдәҺ2010е№ҙ12жңҲд»ҪејҖжәҗзҡ„ж¶ҲжҒҜзі»з»ҹпјҢе®ғдё»иҰҒз”ЁдәҺеӨ„зҗҶжҙ»и·ғзҡ„жөҒејҸж•°жҚ®гҖӮ
жҙ»и·ғзҡ„жөҒејҸж•°жҚ®еңЁwebзҪ‘з«ҷеә”з”Ёдёӯйқһеёёеёёи§ҒпјҢиҝҷдәӣж•°жҚ®еҢ…жӢ¬зҪ‘з«ҷзҡ„pvгҖҒз”ЁжҲ·и®ҝй—®дәҶд»Җд№ҲеҶ…е®№пјҢжҗңзҙўдәҶд»Җд№ҲеҶ…е®№зӯүгҖӮ
иҝҷдәӣж•°жҚ®йҖҡеёёд»Ҙж—Ҙеҝ—зҡ„еҪўејҸи®°еҪ•дёӢжқҘпјҢ然еҗҺжҜҸйҡ”дёҖж®өж—¶й—ҙиҝӣиЎҢдёҖж¬Ўз»ҹи®ЎеӨ„зҗҶгҖӮ
13.AmbariпјҲе®үиЈ…йғЁзҪІй…ҚзҪ®з®ЎзҗҶе·Ҙе…·пјү
Apache Ambari зҡ„дҪңз”ЁжқҘиҜҙпјҢе°ұжҳҜеҲӣе»әгҖҒз®ЎзҗҶгҖҒзӣ‘и§Ҷ Hadoop зҡ„йӣҶзҫӨпјҢжҳҜдёәдәҶи®© Hadoop д»ҘеҸҠзӣёе…ізҡ„еӨ§ж•°жҚ®иҪҜ件жӣҙе®№жҳ“дҪҝз”Ёзҡ„дёҖдёӘwebе·Ҙе…·гҖӮ





