service mysqld start:启动数据库服务
MYSQL * mysql_init(MYSQL *mysql);初始化mysql句柄.如果mysql为NULL, 则分配一个.
连接数据库:
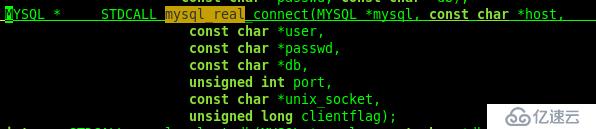
关闭连接:void STDCALL mysql_close(MYSQL *sock);
执行sql语句:int mysql_query(MYSQL *connection ,const char *query);如果成功返回0,query为sql语句。
获取结果:MYSQL_RES * STDCALL mysql_store_result(MYSQL *mysql);执行此函数前必须调用sql:select* from stu
返回结果集中行的数目:int mysql_num_rows ( MYSQL_RES * result )
返回结果集中l列的数目:int mysql_num_fields(MYSQL_RES * result )
注:要取得被 INSERT,UPDATE 或者 DELETE 查询所影响到的行的数目,用 mysql_affected_rows()。
MYSQL_FIELD *mysql_fetch_fields(MYSQL_RES *result);
对于结果集,返回所有MYSQL_FIELD结构的数组。每个结构提供了结果集中1列的字段定义。关于结果列所有列的MYSQL_FIELD结构的数组。
MYSQL_ROW mysql_fetch_row(MYSQL_RES *result)
检索一个结果集合的下一行。当在mysql_store_result()之后使用时,如果没有更多的行可检索时,mysql_fetch_row()返回NULL。
注:在行中值的数量由mysql_num_fields(result)给出。如果row保存了从一个对用mysql_fetch_row()调用返回的值,指向该值的指针作为row[0]到row[mysql_num_fields(result)-1]来存取。在行中的NULL值由NULL指针指出。
在行中字段值的长度可以通过调用mysql_fetch_lengths()获得。空字段和包含NULL的字段长度都是 0;你可以通过检查该值的指针区分他们。如果指针是NULL,字段是NULL;否则字段是空的。
索引:是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。
如果想按特定职员的姓来查找他,则与在表中搜索所有的行相比,索引有助于更快地获取信息。
例如这样一个查询:select * from table1 where id=10000。如果没有索引,必须遍历整个表,直到ID等于10000的这一行被找到为止;有了索引之后(必须是在ID这一列上建立的索引),即可在索引中查找。由于索引是经过某种算法优化过的,因而查找次数要少的多。可见,索引是用来定位的。
数据库索引好比是一本书前面的目录,能加快数据库的查询速度。
索引分为聚簇索引和非聚簇索引两种。
聚簇索引:是按照数据存放的物理位置为顺序的,而非聚簇索引就不一样了;聚簇索引能提高多行检索的速度,而非聚簇索引对于单行的检索很快。
根据数据库的功能,可以在数据库设计器中创建三种索引:唯一索引、主键索引和聚簇索引。
注:尽管唯一索引有助于定位信息,但为获得最佳性能结果,建议改用主键或唯一约束。
唯一索引 唯一索引是不允许其中任何两行具有相同索引值的索引。
当现有数据中存在重复的键值时,大多数数据库不允许将新创建的唯一索引与表一起保存。数据库还可能防止添加将在表中创建重复键值的新数据。例如,如果在employee表中职员的姓(lname)上创建了唯一索引,则任何两个员工都不能同姓。
主键索引
注:主键是表中的一个或多个字段,它的值用于惟一地标识表中的某一条记录,使用索引可快速访问数据库表中的特定信息。
数据库表经常有一列或多列组合,其值唯一标识表中的每一行。该列称为表的主键。
主键列不允许空值。 唯一索引允许空值。
创建 PRIMARY KEY 或 UNIQUE 约束会自动为指定的列创建唯一索引。创建 UNIQUE 约束和创建独立于约束的唯一索引没有明显的区别。数据验证的方式是相同的,而且查询优化器不会区分唯一索引是由约束创建的还是手动创建的。但是,如果您的目的是要实现数据完整性,则应为列创建 UNIQUE 或 PRIMARY KEY 约束。这样做才能使索引的目标明确。
在数据库关系图中为表定义主键将自动创建主键索引,主键索引是唯一索引的特定类型。该索引要求主键中的每个值都唯一。当在查询中使用主键索引时,它还允许对数据的快速访问。
聚簇索引
在聚集索引中,表中行的物理顺序与键值的逻辑(索引)顺序相同。一个表只能包含一个聚集索引。
如果某索引不是聚集索引,则表中行的物理顺序与键值的逻辑顺序不匹配。与非聚集索引相比,聚集索引通常提供更快的数据访问速度。
索引列
可以基于数据库表中的单列或多列创建索引。多列索引可以区分其中一列可能有相同值的行。
如果经常同时搜索两列或多列或按两列或多列排序时,索引也很有帮助。例如,如果经常在同一查询中为姓和名两列设置判据,那么在这两列上创建多列索引将很有意义。
确定索引的有效性:
检查查询的WHERE和JOIN子句。在任一子句中包括的每一列都是索引可以选择的对象。
建立索引时需考虑:
注:对新索引进行试验以检查它对运行查询性能的影响。
考虑已在表上创建的索引数量。最好避免在单个表上有很多索引。
检查已在表上创建的索引的定义。最好避免包含共享列的重叠索引。
检查某列中唯一数据值的数量,并将该数量与表中的行数进行比较。比较的结果就是该列的可选择性,这有助于确定该列是否适合建立索引,如果适合,确定索引的类型。
触发器(trigger)是SQL server 提供给程序员和数据分析员来保证数据完整性的一种方法,它是与表事件相关的特殊的存储过程,它的执行不是由程序调用,也不是手工启动,而是由事件来触发,比如当对一个表进行操作( insert,delete, update)时就会激活它执行。触发器经常用于加强数据的完整性约束和业务规则等。
(1)触发器可以查询其他表,而且可以包含复杂的SQL语句。它们主要用于强制服从复杂的业务规则或要求。例如:您可以根据客户当前的帐户状态,控制是否允许插入新订单。
(2)触发器也可用于强制引用完整性,以便在多个表中添加、更新或删除行时,保留在这些表之间所定义的关系。然而,强制引用完整性的最好方法是在相关表中定义主键和外键约束。如果使用数据库关系图,则可以在表之间创建关系以自动创建外键约束。
触发器与存储过程的唯一区别是触发器不能执行EXECUTE语句调用,而是在用户执行Transact-SQL语句时自动触发执行。
触发器有如下作用:
可在写入数据表前,强制检验或转换数据。
触发器发生错误时,异动的结果会被撤销。
部份数据库管理系统可以针对数据定义语言(DDL)使用触发器,称为DDL触发器。
可依照特定的情况,替换异动的指令 (INSTEAD OF)。
SQL Server 包括三种常规类型的触发器:DML 触发器、DDL 触发器和登录触发器。
当数据库中表中的数据发生变化时,包括insert,update,delete任意操作,如果我们对该表写了对应的DML触发器,那么该触发器自动执行。DML触发器的主要作用在于强制执行业 务规则,以及扩展Sql Server约束,默认值等。因为我们知道约束只能约束同一个表中的数据,而触发器中则可以执行任意Sql命令。
它是Sql Server2005新增的触发器,主要用于审核与规范对数据库中表,触发器,视图等结构上的操作。比如在修改表,修改列,新增表,新增列等。它在数据库结构发生变化时执行,我们主要用它来记录数据库的修改过程,以及限制程序员对数据库的修改,比如不允许删除某些指定表等。
登录触发器将为响应 LOGIN 事件而激发存储过程。与 SQL Server 实例建立用户会话时将引发此事件。登录触发器将在登录的身份验证阶段完成之后且用户会话实际建立之前激发。因此,来自触发器内部且通常将到达用户的所有消息(例如错误消息和来自 PRINT 语句的消息)会传送到 SQL Server 错误日志。如果身份验证失败,将不激发登录触发器。
注:约束,是指对你的表,或表中的列等等,进行某些条件的限制.重点是“限制”.
触发器,是指在你进行一些操作时,比如DELETE UPDATE等操作时,引起的一些另外的操作(是做了摸个动作之后,引起的反应).
事务(Transaction)是访问并可能更新数据库中各种数据项的一个程序执行单元(unit)。事务通常由高级数据库操纵语言或编程语言(如SQL,C++或Java)书写的用户程序的执行所引起,并用形如begin transaction和end transaction语句(或函数调用)来界定。事务由事务开始(begin transaction)和事务结束(end transaction)之间执行的全体操作组成。
例如:在关系数据库中,一个事务可以是一条SQL语句,一组SQL语句或整个程序。
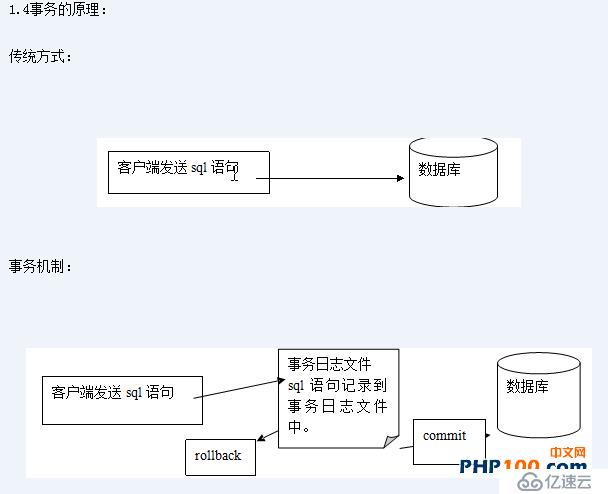
事务是恢复和并发控制的基本单位。
事务应该具有4个属性:原子性、一致性、隔离性、持久性。这四个属性通常称为ACID特性。
原子性(atomicity):一个事务是一个不可分割的工作单位,事务中包括的诸操作要么都做,要么都不做。
一致性(consistency):事务必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
隔离性(isolation):一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
持久性(durability):持久性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
事务类型:
(1)手动事务
手动事务允许显式处理若干过程,这些过程包括:开始事务、控制事务边界内的每个连接和资源登记、确定事务结果(提交或中止)以及结束事务。尽管此模型提供了对事务的标准控制,但它缺少一些内置于自动事务模型的简化操作。例如,在手动事务中数据存储区之间没有自动登记和协调。此外,与自动事务不同,手动事务中事务不在对象间流动。
如果选择手动控制分布式事务,则必须管理恢复、并发、安全性和完整性。也就是说,必须应用维护与事务处理关联的 ACID 属性所需的所有编程方法。
(2)自动事务
.NET 页、XML Web services方法或 .NET Framework 类一旦被标记为参与事务,它们将自动在事务范围内执行。您可以通过在页、XML Web services 方法或类中设置一个事务属性值来控制对象的事务行为。特性值反过来确定实例化对象的事务性行为。因此,根据声明特性值的不同,对象将自动参与现有事务或正在进行的事务,成为新事务的根或者根本不参与事务。声明事务属性的语法在 .NET Framework 类、.NET 页和 XML Web services 方法中稍有不同。
注:一般来说,对于安全性要求比较高的业务,建议使用事务。
存储引擎
我们说数据库是组织、存储和管理数据的仓库。那么,数据库存储数据的方式,就是存储引擎。
在mysql中,存储引擎是以插件的形式加载的。Mysql的存储引擎种类繁多,对于我们来说,要熟悉两种存储引擎去,MyISAM和inonoDB。Myisam不支持事务。 Innodb支持事务。
拓展:例如,如果你在研究大量的临时数据,你也许需要使用内存存储引擎。内存存储引擎能够在内存中存储所有的表格数据。又或者,你也许需要一个支持事务处理的数据库(以确保事务处理不成功时数据的回退能力)。
这些不同的技术以及配套的相关功能在MySQL中被称作存储引擎(也称作表类型)。MySQL默认配置了许多不同的存储引擎,可以预先设置或者在MySQL服务器中启用。你可以选择适用于服务器、数据库和表格的存储引擎,以便在选择如何存储你的信息、如何检索这些信息以及你需要你的数据结合什么性能和功能的时候为你提供最大的灵活性。选择如何存储和检索你的数据的这种灵活性是MySQL为什么如此受欢迎的主要原因。
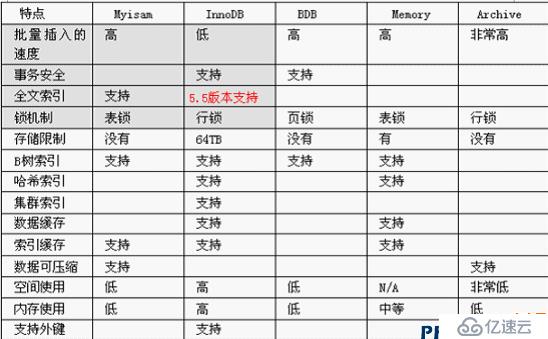
各种存储引擎特点:
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





