这篇文章给大家介绍Facebook中怎么实现Hadoop和AvatarNode集群,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
Facebook将数据存储在利用Hadoop/Hive搭建的数据仓库上,这个数据仓库拥有4800个内核,具有5.5PB的存储量,每个节点可存储12TB大小的数据,同时,它还具有两层网络拓扑。Facebook中的MapReduce集群是动态变化的,它基于负载情况和集群节点之间的配置信息可动态移动。
Facebook的数据仓库架构,在这个架构中,网络服务器和内部服务生成日志数据,这里Facebook使用开源日志收集系统,它可以将数以百计的日志数据集存储在NFS服务器上,但大部分日志数据会复制到同一个中心的HDFS实例中,而HDFS存储的数据都会放到利用Hive构建的数据仓库中。Hive提供了类SQL的语言来与MapReduce结合,创建并发布多种摘要和报告,以及在它们的基础上进行历史分析。Hive上基于浏览器的接口允许用户执行Hive查询。Oracle和MySQL数据库用来发布这些摘要,这些数据容量相对较小,但查询频率较高并需要实时响应。一些旧的数据需要及时归档,并存储在较便宜的存储器上。
下面介绍Facebook在AvatarNode和调度策略方面所做的一些工作。AvatarNode主要用于HDFS的恢复和启动,若HDFS崩溃,原有技术恢复首先需要花10~15分钟来读取12GB的文件镜像并写回,还要用20~30分钟处理来自2000个DataNode的数据块报告,最后用40~60分钟来恢复崩溃的NameNode和部署软件。表3-1说明了BackupNode和AvatarNode的区别,AvatarNode作为普通的NameNode启动,处理所有来自DataNode的消息。AvatarDataNode与DataNode相似,支持多线程和针对多个主节点的多队列,但无法区分原始和备份。人工恢复使用AvatarShell命令行工具,AvatarShell执行恢复操作并更新ZooKeeper的zNode,恢复过程对用户来说是透明的。分布式Avatar文件系统实现在现有文件系统的上层。
基于位置的调度策略在实际应用中存在着一些问题:如需要高内存的任务可能会被分配给拥有低内存的TaskTracker;CPU资源有时未被充分利用;为不同硬件的TaskTracker进行配置也比较困难等。Facebook采用基于资源的调度策略,即公平享有调度方法,实时监测系统并收集CPU和内存的使用情况,调度器会分析实时的内存消耗情况,然后在任务之间公平分配任务的内存使用量。它通过读取/proc/目录解析进程树,并收集进程树上所有的CPU和内存的使用信息,然后通过TaskCounters在心跳(heartbeat)时发送信息。
Facebook的数据仓库使用Hive,这里HDFS支持三种文件格式:文本文件(TextFile),方便其他应用程序读写;顺序文件(SequenceFile),只有Hadoop能够读取并支持分块压缩;RCFile,使用顺序文件基于块的存储方式,每个块按列存储,这样有较好的压缩率和查询性能。Facebook未来会在Hive上进行改进,以支持索引、视图、子查询等新功能。
现在Facebook使用Hadoop遇到的挑战有:
服务质量和隔离性方面,较大的任务会影响集群性能;
安全性方面,如果软件漏洞导致NameNode事务日志崩溃该如何处理;
数据归档方面,如何选择归档数据,以及数据如何归档;
性能提升方面,如何有效地解决瓶颈等。
解决Namenode顽疾
Google在2004年创造了MapReduce,MapReduce系统获得成功的原因之一是它为编写需要大规模并行处理的代码提供了简单的编程模式。MapReduce集群可包括数以千计的并行操作的计算机。同时MapReduce允许程序员在如此庞大的集群中快速的转换数据并执行数据。它受到了Lisp的函数编程特性和其他函数式语言的启发。MapReduce和云计算非常相配。MapReduce的关键特点是它能够对开发人员隐藏操作并行语义 — 并行编程的具体工作方式。
HDFS(Hadoop Distributed Filesystem)是专为MapReduce框架而下大规模分布式数据处理而设计的,HDFS可将大数据集(TB级)存储为单个文件,而大多文件系统并不具备这样的能力。(编者注:NTFS5 Max Files on Volume:264 bytes (16 ExaBytes) minus 1KB,1EB = 1,000,000 TB)。这也是HDFS风靡全球的重要原因。
目前Facebook Hadoop集群内的HDFS物理磁盘空间承载超过100PB的数据(分布在不同数据中心的100多个集群)。由于HDFS存储着Hadoop应用需要处理的数据,因此优化HDFS成为Facebook为用户提供高效、可靠服务至关重要的因素。
HDFS Namenode是如何工作的?
HDFS客户端通过被称之为Namenode单服务器节点执行文件系统原数据操作,同时DataNode会与其他DataNode进行通信并复制数据块以实现冗余,这样单一的DataNode损坏不会导致集群的数据丢失。
但NameNode出现故障的损失确是无法容忍的。NameNode主要职责是跟踪文件如何被分割成文件块、文件块又被哪些节点存储,以及分布式文件系统的整体运行状态是否正常等。但如果NameNode节点停止运行的话将会导致数据节点无法通信,客户端无法读取和写入数据到HDFS,实际上这也将导致整个系统停止工作。
The HDFS Namenode is a single point of failure (SPOF)
Facebook也深知“Namenode-as-SPOF”所带来问题的严重性,所以Facebook希望建立一套系统已破除“Namenode-as-SPOF”带来的隐患。但在了解这套系统之前,首先来看一下Facebook在使用和部署HDFS都遇到了哪些问题。
Facebook数据仓库的使用情况
在Facebook的数据仓库中部署着最大的HDFS集群,数据仓库的使用情况是传统的Hadoop MapReduce工作负载——在大型集群中一小部分运行MapReduce批处理作业
因为集群非常庞大,客户端和众多DataNode节点与NameNode节点传输海量的原数据,这导致NameNode的负载非常沉重。而来自CPU、内存、磁盘和网络带来的压力也使得数据仓库集群中NameNode高负载状况屡见不鲜。在使用过程中Facebook发现其数据仓库中由于HDFS引发的故障占总故障率的41%。

HDFS NameNode是HDFS中的重要组成部分,同时也是整个数据仓库中的重要组成部分。虽然高可用的NameNode只可以预防数据仓库10%的计划外停机,不过消除NameNode对于SPOF来说可谓是重大的胜利,因为这使得Facebook可执行预订的硬件和软件回复。事实上,Facebook预计如果解决NameNode可消除集群50%的计划停机时间。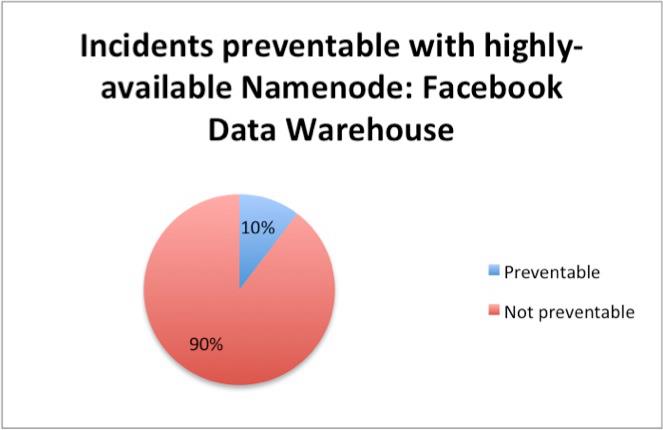
那么高可用性NameNode是什么样子的?它将如何工作?让我们来看一下高度可用性NameNode的图表。
在此结构中,客户端可与Primary NameNode与Standby NameNode通信,同样众多DataNode
也具备给Primary NameNode与Standby NameNode发送block reports的能力。实质上Facebook所研发的AvatarNode就是具备高可用NameNode的解决方案。
Avatarnode:具备NameNode故障转移的解决方案
为了解决单NameNode节点的设计缺陷,大约在两年前Facebook开始在内部使用AvatarNode工作。
同时AvatarNode提供了高可用性的NameNode以及热故障切换和回滚功能,目前Facebook已经将AvatarNode贡献到了开源社区。经过无数次的测试和Bug修复,AvatarNode目前已在Facebook最大的Hadoop数据仓库中稳定运行。在这里很大程度上要感谢Facebook的工程师Dmytro Molkov。
当发生故障时,AvatarNode的两个高可用NameNode节点可手动故障转移。AvatarNode将现有的NameNode代码打包并放置在Zookeeper层。
AvatarNode的基本概念如下:
1.具备Primary NameNode与Standby NameNode
2.当前Master主机名保存在ZooKeeper之中
3.改进的DataNode发送block reports到Primary NameNode与Standby NameNode
4.改进的HDFS客户端将在每个事物开始之前对Zookeeper进行检查,如果失败会转移到另外的事务之中。同时如果AvatarNode故障转移出现在写入的过程中,AvatarNode的机制将允许保证完整的数据写入。
Avatarnode客户端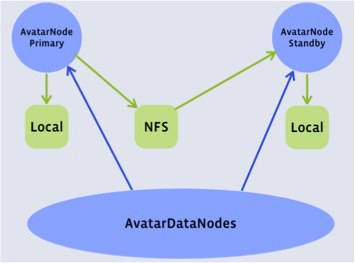
关于Facebook中怎么实现Hadoop和AvatarNode集群就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





