在前段时间看了杰昆菲尼克斯的小丑电影,心里很好奇大部分观众看完这部电影之后对此有什么评价,然后看了看豆瓣短评之后,觉得通过python把短评中出现最多的单词提取出来,做成一张词云,看看这部电影给观众们留下的关键词是什么。
首先刚开始的时候 ,是通过requests去模拟抓取数据,发现短评翻页翻到20页之后就需要登录豆瓣用户才有权限查看,所以打算通过使用selenium模拟浏览器动作自动化将页面中的数据爬取下来,然后存储到特定的txt文件,由于没打算做其他的分析,就不打算存放到数据库中。
关于流行的自动化测试框架selenium的工作原理,以及selenium和chromdriver对应的版本安装就不详细赘述,有兴趣的同学可以参考:
https://blog.csdn.net/weixin_43241295/article/details/83784692
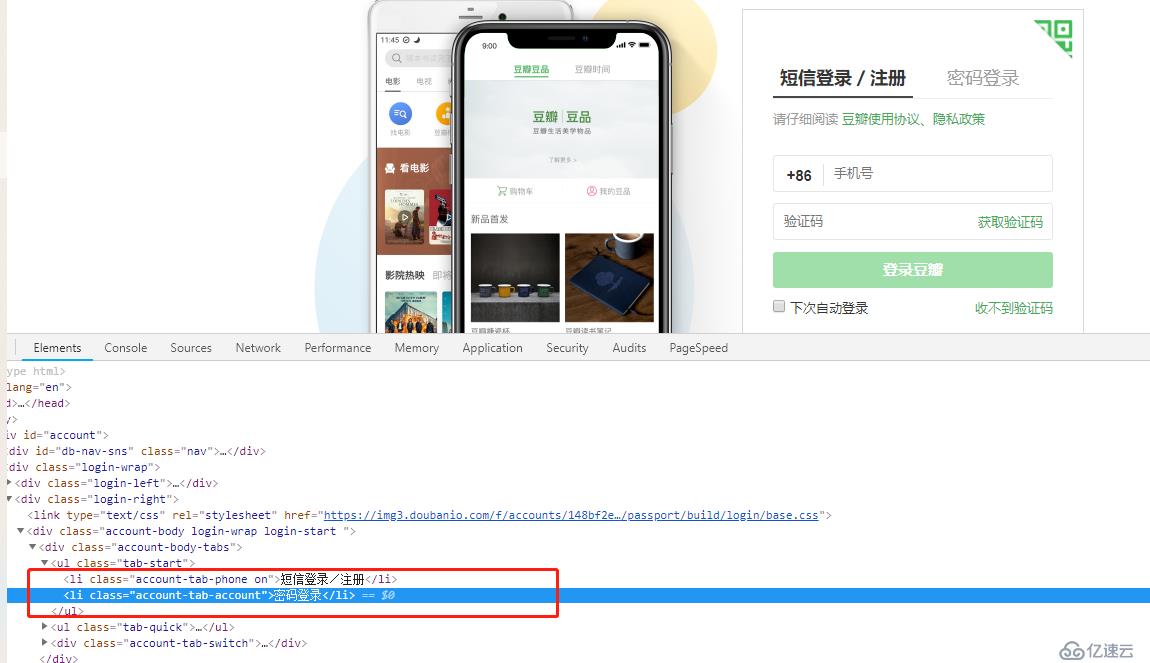
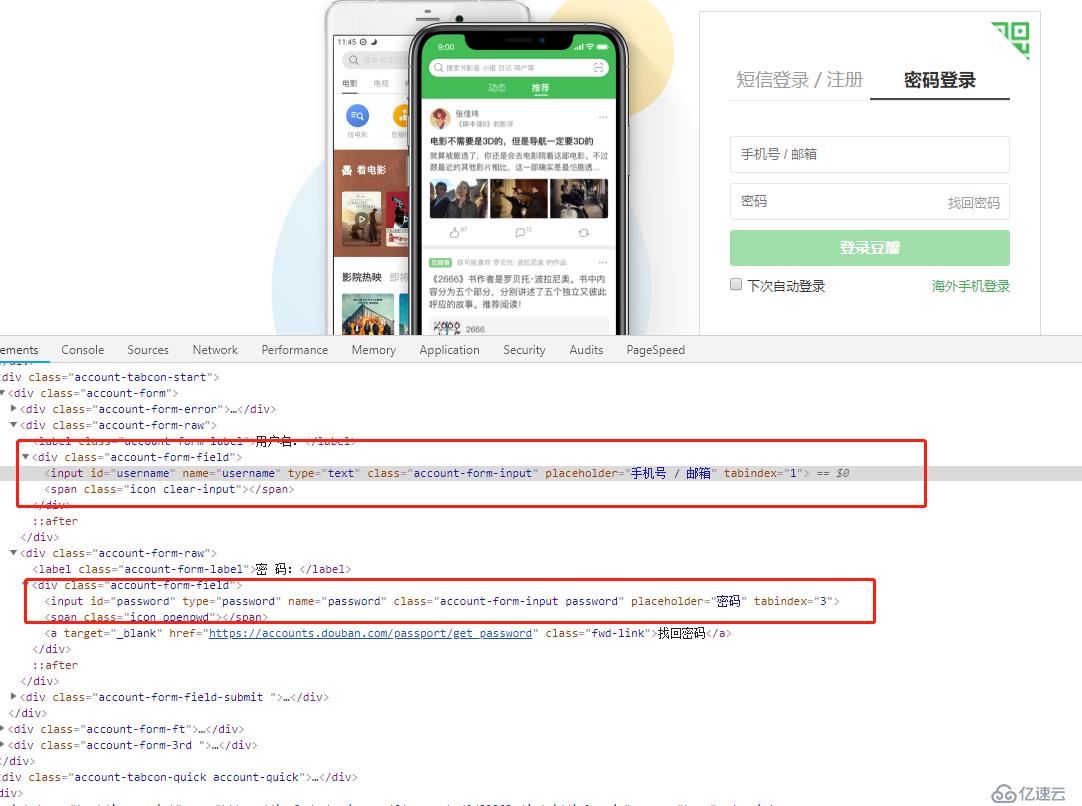
从页面上看来,大概流程就是点击导航栏中的密码登录,然后输入用户名和密码,点击登录按钮,至于看网上一些豆瓣爬虫时会出现的验证图片,我没有遇到过,我直接登录就OK了,所以接下来就需要通过selenium模拟整个登录过程。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
def crawldouban():
name = "你的用户名"
passw = "你的密码"
# 启动chrome
options = Options()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
browser = webdriver.Chrome(executable_path="/usr/bin/chromedriver", options=options)
# 获取登录网址
browser.get("https://accounts.douban.com/passport/login")
time.sleep(3)
# 登录自动化操作流程
browser.find_element_by_class_name("account-tab-account").click()
form = browser.find_element_by_class_name("account-tabcon-start")
username = form.find_element_by_id("username")
password = form.find_element_by_id("password")
username.send_keys(name)
password.send_keys(passw)
browser.find_element_by_class_name("account-form-field-submit").click()
time.sleep(3)接下来就是,获取页面中的评论,然后将评论存储到指定的文本文件中,(我就不模拟查询电影然后,跳转到短评的整个过程了),直接从拿到的短评页面地址出发,不断点击下一页然后不断重复提取评论,写入的操作。
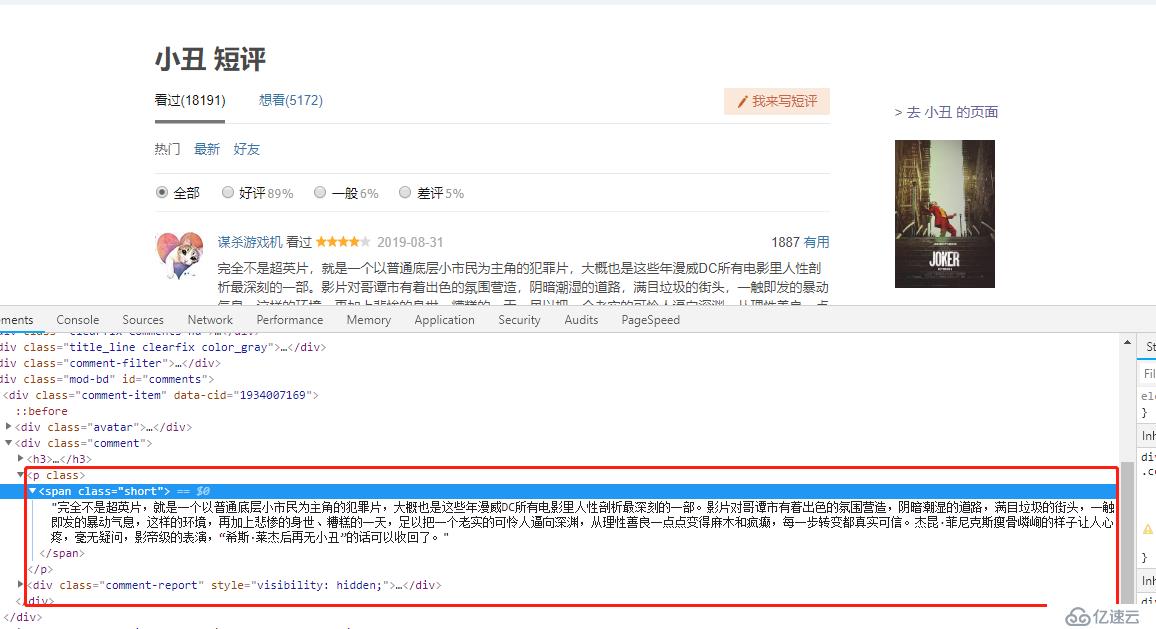
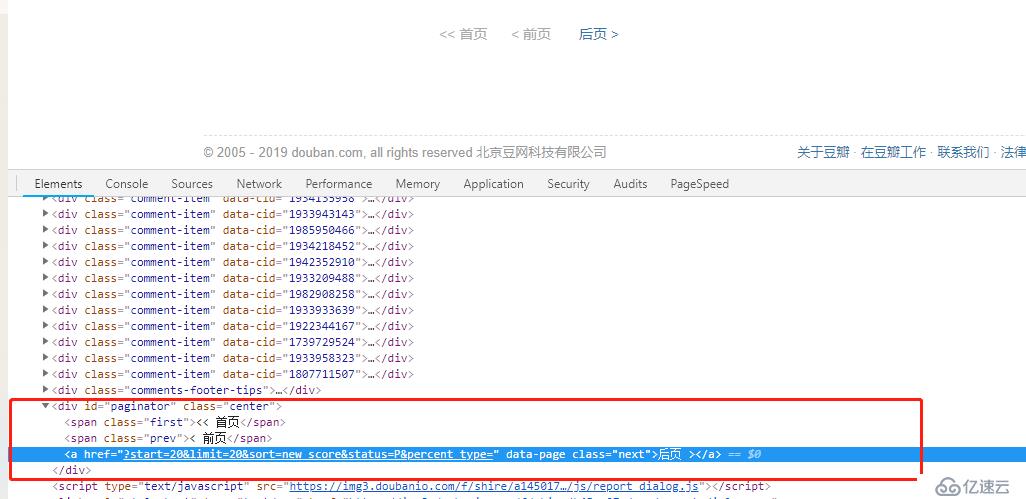
browser.get("https://movie.douban.com/subject/27119724/comments?status=P")
comments = browser.find_elements_by_class_name("short")
WriteComment(comments)
while True:
link = browser.find_element_by_class_name("next")
path = link.get_attribute('href')
if not path:
break
# print(path)
link.click()
time.sleep(3)
comments = browser.find_elements_by_class_name("short")
WriteComment(comments)
browser.quit()
# 将评论写入到指定的文本文件
def WriteComment(comments):
with open("comments.txt", "a+") as f:
for comment in comments:
f.write(comment.text+" \n") 代码解析:抓取的代码没啥好讲的,就是找到classname是'short‘的元素,获取里面的文本内容写到指定文本文件即可,里面主要有个循环判断是否还有下一页,通过获取下一页的超链接,当获取不到时证明已经在最后一页了。
大概讲讲思路吧,我这里的数据处理比较粗糙,没有结合pandas+numpy,我将爬取下来的数据,简单的将换行符切割然后组成新的数据,然后通过jieba分词,将新的数据进行分词,最后再读取本地的一个停顿词文件,获取一个停顿词列表。生成词云指定停顿词,以及字体文件,背景颜色等,再把词云图片保存到本地。
from wordcloud import WordCloud
from scipy.misc import imread
import jieba
# 处理从文本中读取的内容
def text_read(file_path):
filename = open(file_path, 'r', encoding='utf-8')
texts = filename.read()
texts_split = texts.split("\n")
filename.close()
return texts_split
def data_handle(picture_name):
# 读取从网站上爬取下来的数据
comments = text_read("comments.txt")
comments = "".join(comments)
# 分词, 读取停顿词
lcut = jieba.lcut(comments)
cut_text = "/".join(lcut)
stopwords = text_read("chineseStopWords.txt")
# 生成词云图
bmask = imread("backgrounds.jpg")
wordcloud = WordCloud(font_path='/usr/share/fonts/chinese/simhei.ttf', mask=bmask, background_color='white', max_font_size=250, width=1300, height=800, stopwords=stopwords)
wordcloud.generate(cut_text)
wordcloud.to_file(picture_name)
if __name__ == "__main__":
data_handle("joker6.jpg")这是我自己扣的一张图片作为背景:

最终效果图:

写爬虫到数据分析,大概有思路以及整理需要用到的工具大概花了两个晚上。整体来说,还是一些比较浅显易懂的东西,对于有关爬虫大规模并发采集 以及数据分析等内容还在学习,记录下自己学习过程还是蛮有趣的。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



