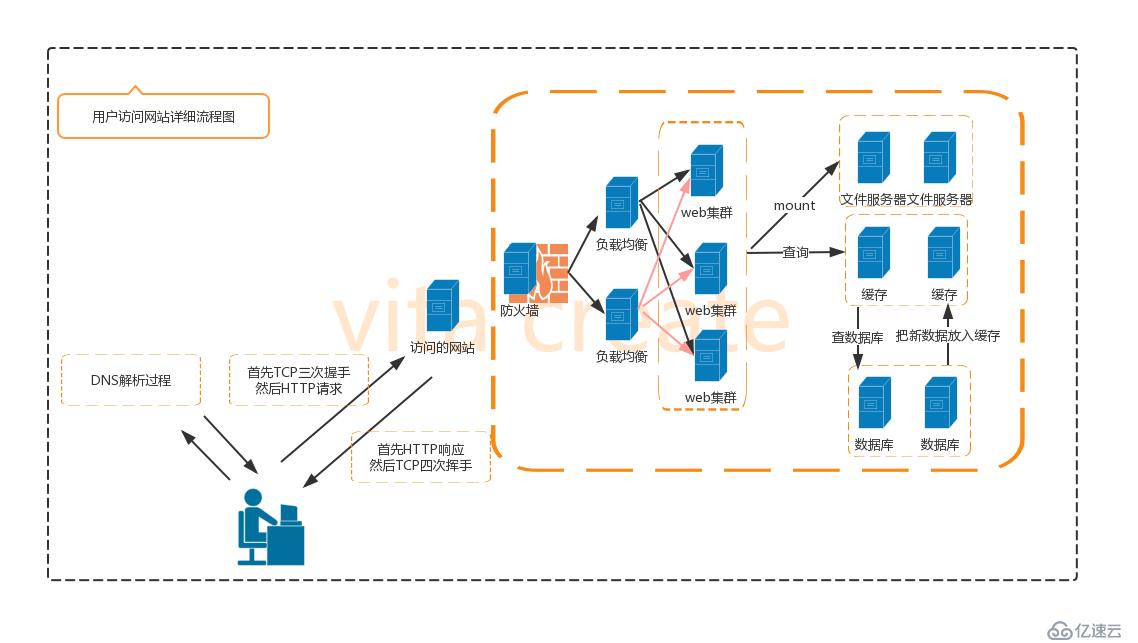
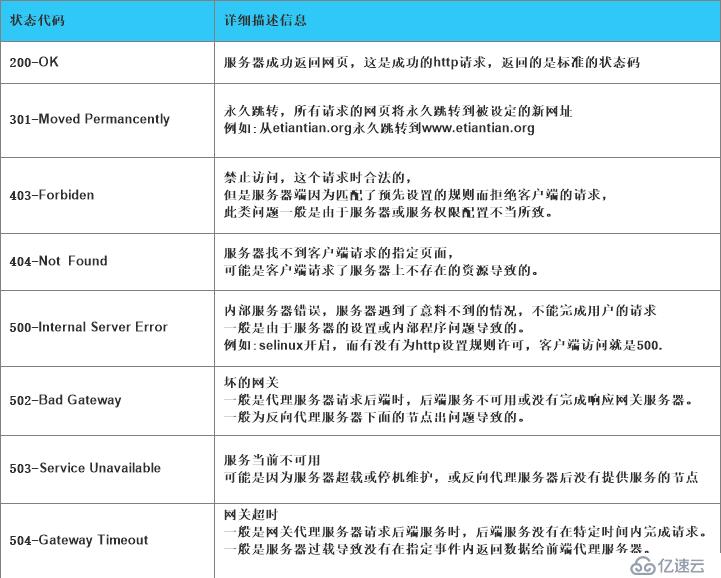
用户访问网站流程 1.首先进行DNS解析 2.TCP/IP三次握手 3.http发送请求 4.大规模网站集群架构 5.http响应请求 6.TCP/IP四次挥手
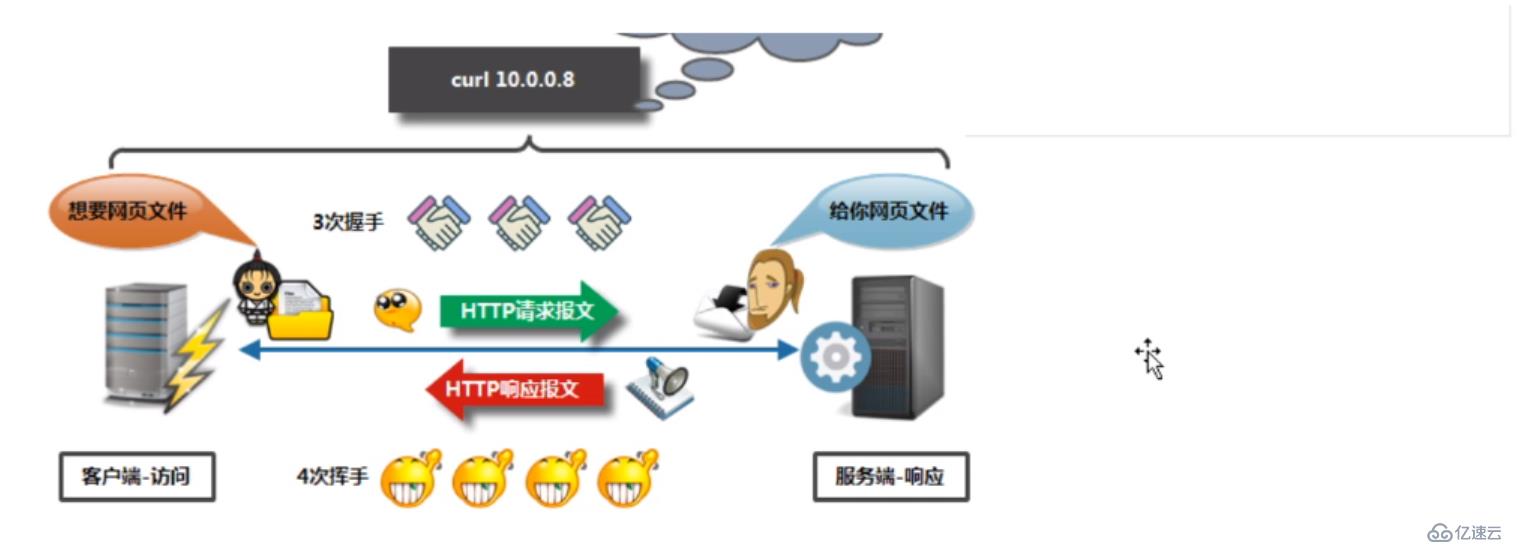
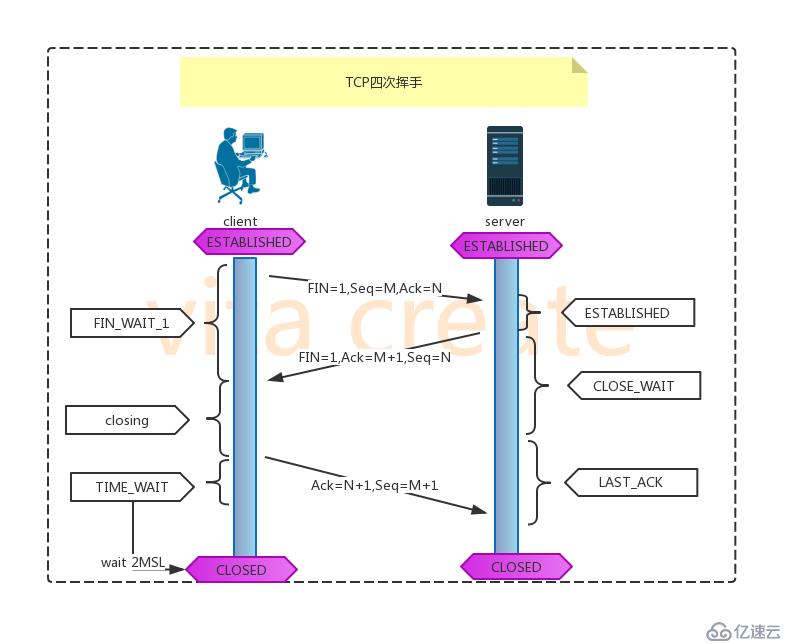
wireshark抓包查看 这里没有看到四次挥手,由于现在HTTP协议是长连接,HTTP请求头中connection:keep-alive,即一次TCP连接,可进行多次HTTP请求 所以TCP连接没有关闭。


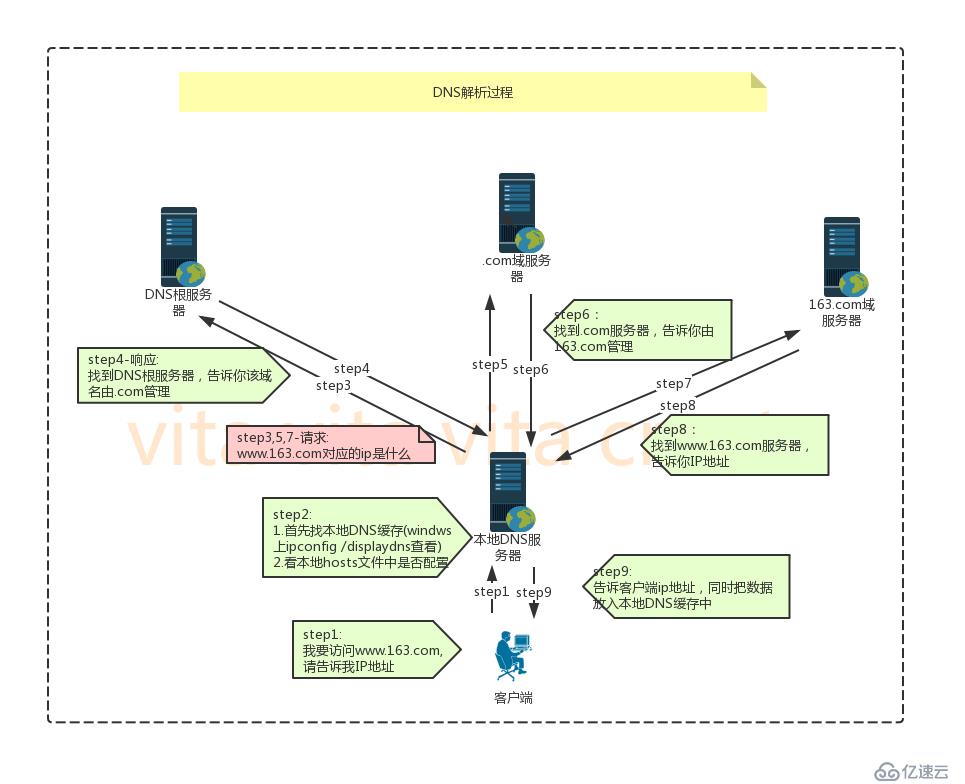
1.用户本地电脑输入网址,例如www.163.com,首先查找本地DNS缓存,windows上可以在命令窗口执行ipconfig /displaydns查看。 2.本地DNS缓存中没有,就查找本地hosts文件,查看是否有该域名对应的ip信息。 3.hosts文件中没有找到,就去根DNS服务器查找,告知该域名属于.com域服务器管理。 4.到.com服务器查找该域名对应的ip,告知归163.com服务器管理。 5.到163.com服务器查找该域名对应的ip,找到了对应IP,返回给客户端 6.客户端接收返回的信息,把域名和IP对应信息保存到本地DNS缓存,同时请求该IP的服务器。
建立过程说明
1.由client发送建立TCP连接的请求报文,
其中包含seq序列号x-发送端随机生成,
并且将报文中的SYN字段设置为1,表示需要建立TCP连接
2.server端回复client发送的TCP连接请求报文,
其中包含seq序列号y-由server端随机生成,
并将SYN设置为1,
而且会产生Ack字段,是client端的序列号x+1,以便A收到信息时,知晓自己的TCP建立请求已经得到了验证
3.client端接收到server端的验证请求后,
回复序列号seq=x+1,
Ack=y+1
4.连接建立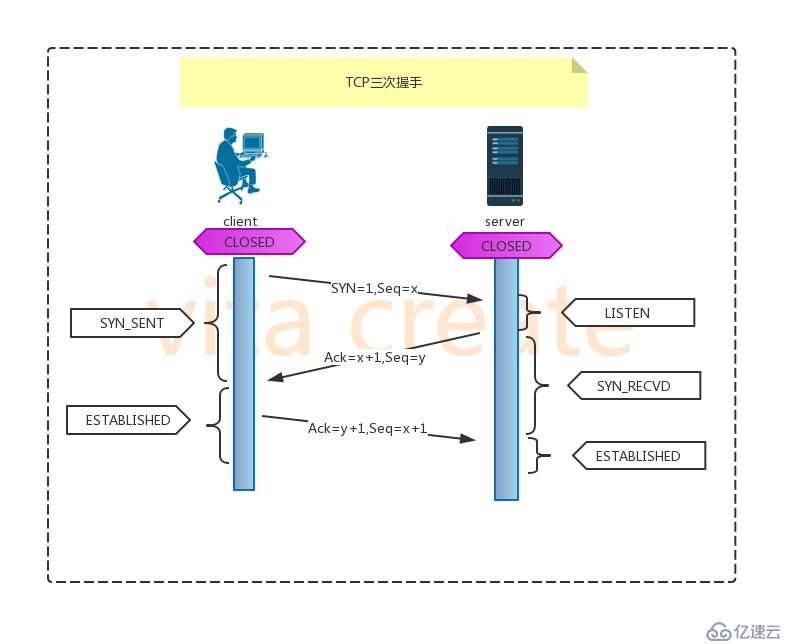
包含请求起始行,请求头,请求空行,请求体内容,后面详细介绍
包含响应起始行,响应头,响应空行,响应体内容,后面详细介绍
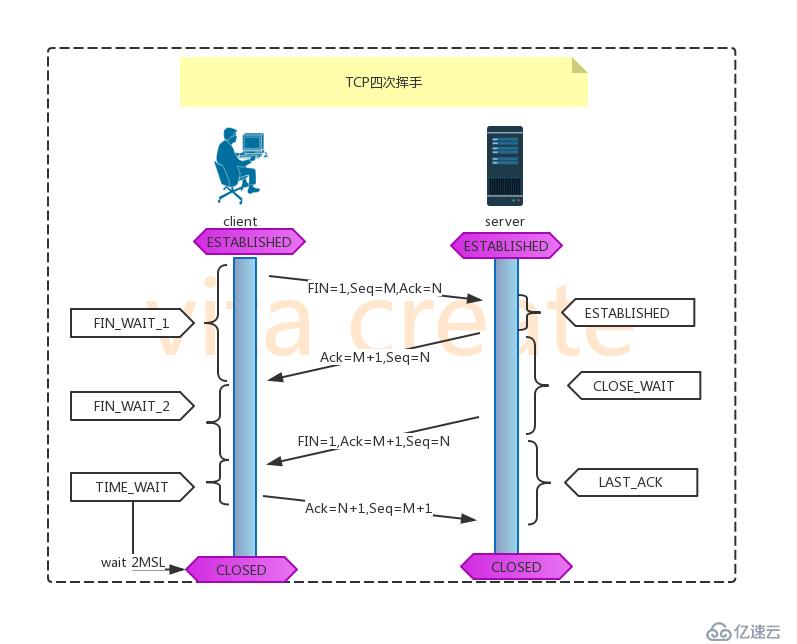
断开过程 1.client端发送断开TCP连接请求, 其中包含序列号M,client端随机生成, Ack=N, FIN设置为1,表示需要断开TCP连接 2.server端回复请求, 其中包含序列号N,为client端发送的ack, Ack=M+1,以便client端知晓自己的TCP断开请求得到了验证。 3.server端回复完client端的断开请求后,不会马上断开连接, server会先确保所有传输到client端的数据传输完成, 只要确认数据传输完成, FIN设置为1, 并发送随机序列号N, Ack=M+1 4.client收到server的TCP断开请求后,会回复server的断开请求, 包含序列号=M+1, Ack=N+1 5.server端接受到断开请求,断开连接。。
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于万维网(WWW-World Wide Web)服务器与本地浏览器之间传输文本的传送协议。
HTTP是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。
它在1990年提出,经过几年的使用与发展,得到不断的完善和扩展。
HTTP协议工作在客户端--服务端框架。
浏览器作为HTTP客户端,通过URL向HTTP服务端即web服务器发送请求。
Web服务器根据收到的请求,向客户端发送响应信息。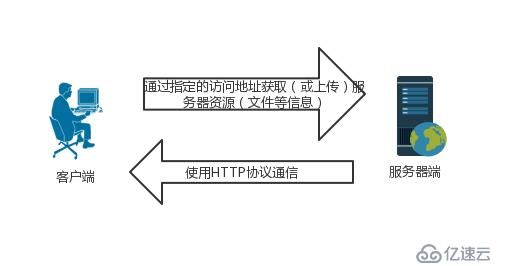
1.是基于TCP/IP之上的应用层协议。
2.基于请求--响应模式
3.无连接协议
4.无状态协议http协议是基于TCP/IP协议之上的应用层协议。
HTTP协议规定,请求从客户端发出,服务器端响应请求。 即请求是从客户端开始建立的,服务端在没有接收到请求时,不会发送响应信息。

HTTP是一种不保存状态的协议。HTTP协议自身不对请求和响应之间的通信状态进行保存。 即在HTTP级别,协议对于发送请求或响应都不做持久化处理。 使用HTTP协议,每当有新的请求发送时,就会有对应的响应产生。 协议本身不会保留之前的请求或响应报文信息。 这是为了更快的处理大量事务,确保协议的可伸缩性。 但是随着web的发展,无状态导致业务的处理出现问题。 例如用户登录购物网站,即使跳转到了该网站的其他页面,也需要保持登录状态。 为了保存用户的状态信息,HTTP/1.1引入了Cookie技术。
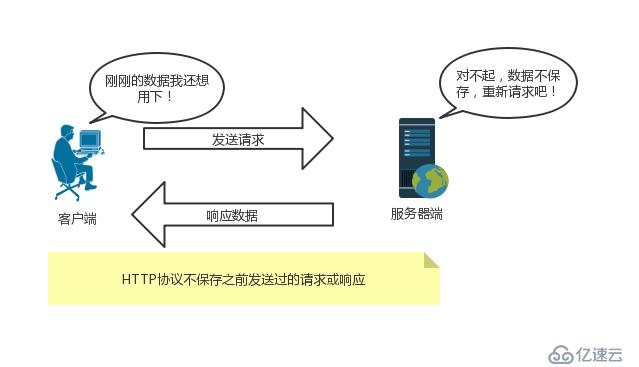
无连接的含义是限制每次连接只处理一个请求。
服务器处理完用户的请求,并收到用户的应答后,即断开连接。
这种方式可以节省传输时间。
HTTP1.1是长连接,在请求头中,connection:keep-alive,即一次TCP连接可以处理多个HTTP请求。
"请求方式:get与post请求"
1.GET提交的数据会放在URL之后,以?分隔URL与传输的数据,参数之间以&相连,如EditBook?name=test1&id=123456
POST会把数据放在请求体中。
2.GET请求的数据有大小限制(因为浏览器对URL的长度有限制),
POST提交的数据没有大小限制。
3.GET与POST请求,在服务端获取数据的方式不同。
1.IP----独立IP数
独立IP数是指不同IP地址的计算机访问网站时,被统计的总次数。
由于在一个局域网中,访问外部网站时,IP都是相同的,所以独立IP数比实际的用户数量要少很多
2.PV----Page View,即页面浏览量或点击量,
不管客户端是否相同,IP是否相同,用于访问一个页面,就计算为一个PV。
3.UV----独立访客数,即Unique Visitor,同一个客户端(PC或移动端)访问网站被计为一个访客。
一天(00:00-24:00)内相同的客户端访问一个网站,只计为一次UV。
cookie:标识用户主机身份信息。web应用程序是一种可以通过Web访问的应用程序,程序的最大好处是用户只需要浏览器即可。
应用程序有两种模式,C/S、B/S。
C/S是客户端/服务器端程序,B/S是浏览器/服务器端程序,这类程序一般借助于浏览器访问。
web应用程序一般都是B/S模式。在网络编程的意义下,浏览器是socket客户端,服务器是socket服务端。import socket
def server():
server_sock = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
server_sock.bind(("127.0.0.1", 8800))
server_sock.listen(5)
while True:
# 一个连接关闭了,继续接受下个连接
conn, client_addr = server_sock.accept()
data = conn.recv(1024)
print("recv_data-----", data)
# 发送数据到浏览器端
# \r\n\r\n表示响应体中的空行,表示响应头内容结束。。这里是根据HTTP协议的要求,回复响应数据
conn.send("HTTP/1.1 200 OK\r\nstatus: 200\r\nContent-Type:text/html\r\n\r\n".encode("utf8"))
conn.send("<h2>Hello, vita!</h2>".encode("utf8"))
# 发送完数据,就关闭连接,因为HTTP协议是无连接的。
conn.close()
if __name__ == '__main__':
server()
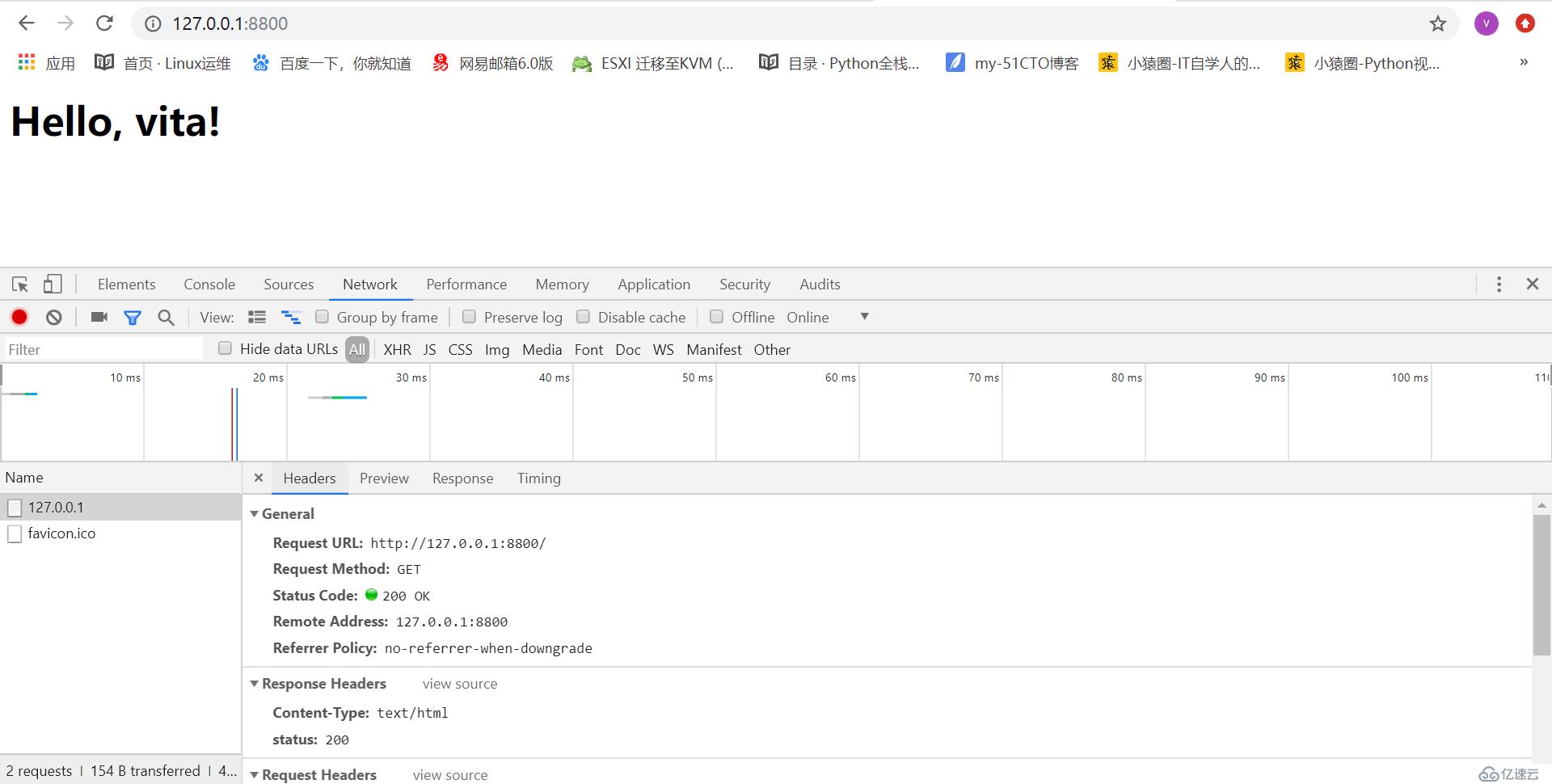
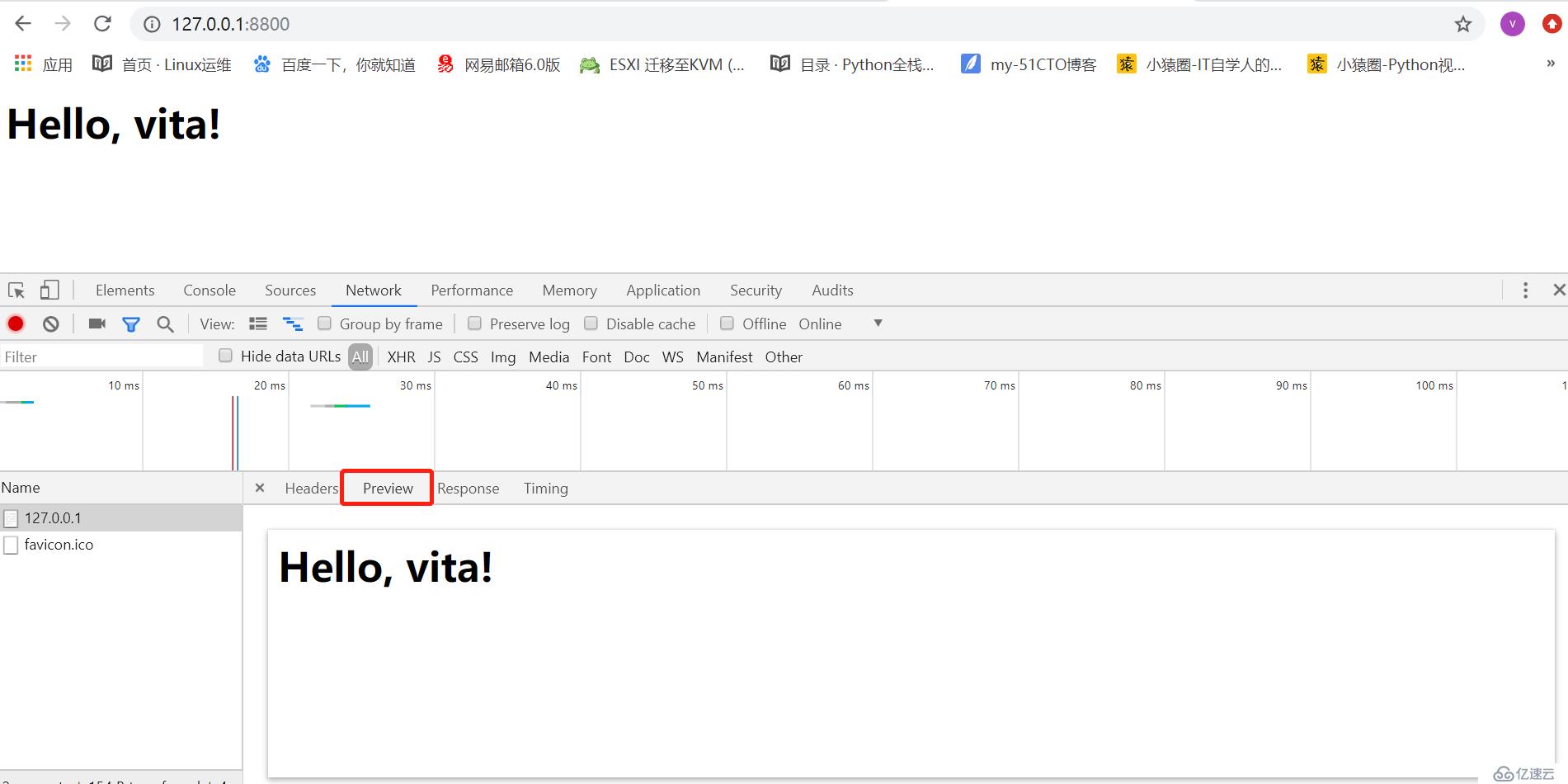

index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<!--默认不写,是当前页面的访问地址-->
<form action=http://127.0.0.1:8800 method="post" target="_blank">
用户名 <input type="text" name="user">
密码 <input type="password" name="pwd">
<input type="submit">
</form>
</body>
</html>
上面我们演示了最简单的web应用,是我们手动处理的接收HTTP请求,解析HTTP请求,发送HTTP响应。
如果我们自己来写这些底层代码,还没开始写动态HTML,就要花很多时间去读HTTP规范。
正确的做法是底层代码由专门的服务器软件实现,我们用Python专注于生成HTML文档。
因为我们不希望手动解析HTTP原始请求数据和设置相应响应格式,所以,需要一个统一的接口协议来实现这样的服务器软件,让我们能够专心用python编写Web业务。
这个接口就是WSGI(web server gateway interface)。
wsgiref模块就是python基于wsgi协议开发的服务模块。from wsgiref.simple_server import make_server
def application(environ,start_response):
# 按着HTTP协议解析数据:environ
# 按着http协议组装数据:start_response
print(type(environ))
print(environ)
path = environ.get("PATH_INFO")
start_response('200 OK', [])
if path == "/login":
with open("login.html", "rb") as f:
data = f.read()
elif path == "/index":
with open("index.html", "rb") as f:
data = f.read()
# 第一次请求时,会请求该路径,扇面演示我们已经看到,该路径是Title旁边的图标
# 需要对该路径的返回做个处理,否则会报错
# 因为如果不做处理,data就没有值,那么后面return [data]就会报data没有定义的错误
elif path == "/favicon.ico":
# 这里是一个图片
with open("favicon.ico", "rb") as f:
data = f.read()
return [data]
# make_server(host,port,app) app是回调函数
httpd = make_server("127.0.0.1",8800,application)
# 等待用户连接:conn,addr=sock.accept()
httpd.serve_forever()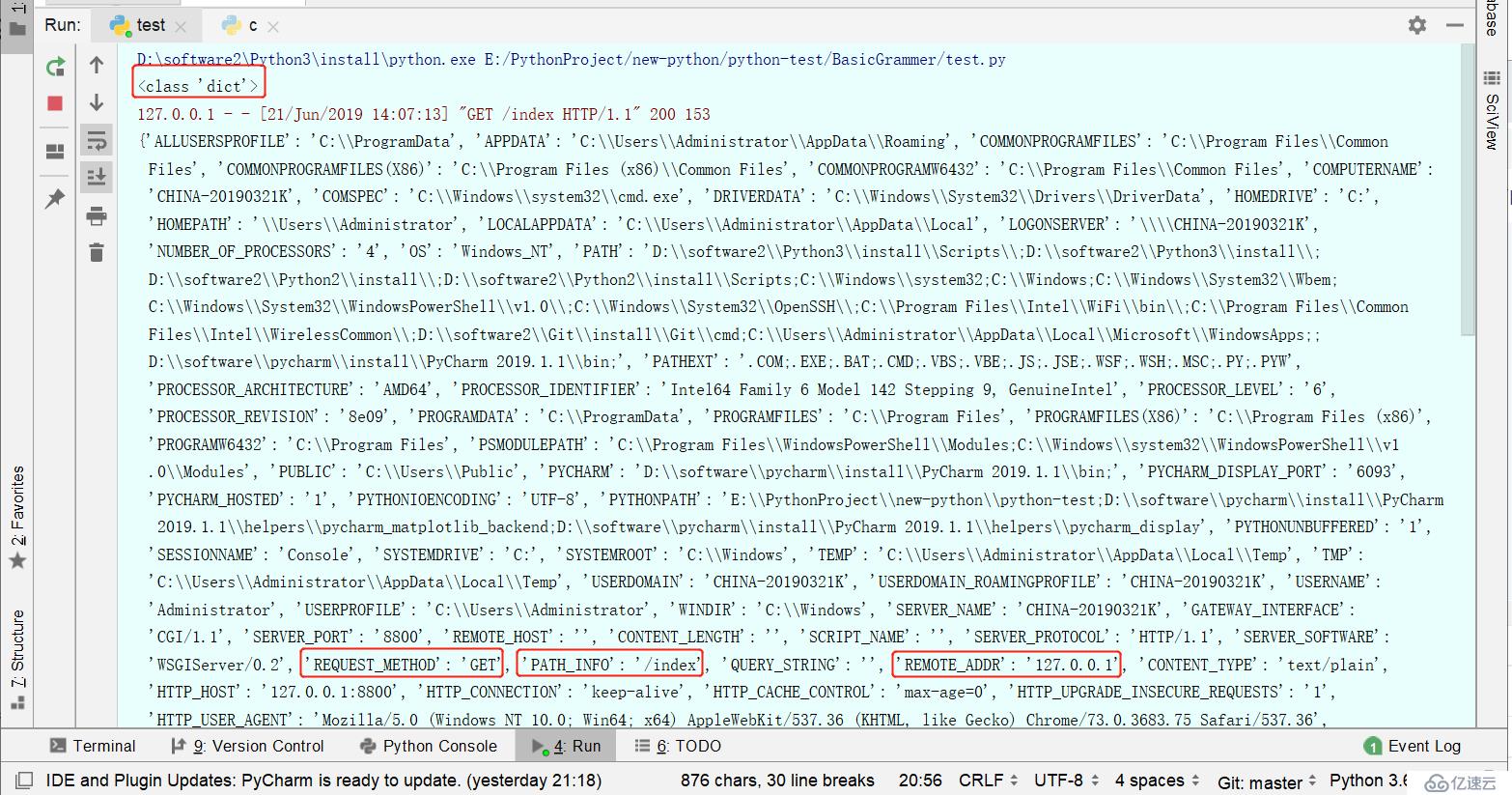
git地址 https://github.com/aawuliliaa/python-test/tree/master/excercise/9.Django/1.myWebStruct
main.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
from wsgiref.simple_server import make_server
from urls import url_patterns
from views import *
def application(environ, start_response):
path = environ.get("PATH_INFO")
start_response("200 OK", [])
func = None
# url_patterns是一个列表,列表中的每项是一个数组
for item in url_patterns:
if path == item[0]:
func = item[1]
break
if func:
# 这种return []是wsgiref模块规定的模式
return [func(environ)]
if __name__ == '__main__':
# 启动socket服务,等待连接
httpd = make_server("127.0.0.1", 8800, application)
httpd.serve_forever()
models.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import pymysql
def get_data(user,password):
conn = pymysql.connect(
host="10.0.0.61",
port=3306,
user="root",
password="123",
database='db1'
)
cur = conn.cursor()
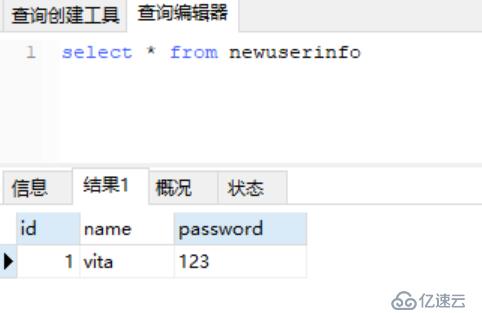
sql = "select * from newuserinfo WHERE NAME ='%s' AND PASSWORD ='%s'" % (user, password)
cur.execute(sql)
return cur
urls.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
from views import *
url_patterns=[
("/index", index),
("/login", login),
("/favicon.ico", favicon),
("/auth", auth)
]views.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
from urllib.parse import parse_qs
from models import get_data
def index(environ):
with open("./templates/index.html","rb") as f:
data = f.read()
return data
def login(environ):
with open("./templates/login.html", "rb") as f:
data = f.read()
return data
def favicon(environ):
with open("./templates/favicon.ico", "rb") as f:
data = f.read()
return data
def auth(environ):
try:
request_body_size = int(environ.get('CONTENT_LENGTH', 0))
except (ValueError):
request_body_size = 0
request_body = environ['wsgi.input'].read(request_body_size)
data = parse_qs(request_body)
# 我这个是windows系统,所以这里要以gbk解码,如果是linux或mac,要用utf8解码
# 获取页面上的用户名和密码
user = data.get(b"user")[0].decode("gbk")
pwd = data.get(b"pwd")[0].decode("gbk")
cur = get_data(user, pwd)
# 如果用户名,密码正确,就展示index页面
if cur.fetchone():
return index(environ)
else:
return b'user or pwd is wrong!'
login.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<form action="http://127.0.0.1:8800/auth" method="post" target="_blank">
用户名 <input type="text" name="user">
密码 <input type="text" name="pwd">
<input type="submit">
</form>
</body>
</html>index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
index page
</body>
</html>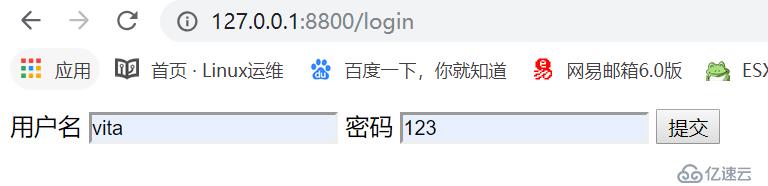
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



