Titanic 案例是Kaggle 入门案例,链接地址https://www.kaggle.com/c/titanic 。以下是摘自官网上的描述信息:
加载训练数据
data_train = pd.read_csv("./input/train.csv")预览数据
data_train.head()
训练集数据说明: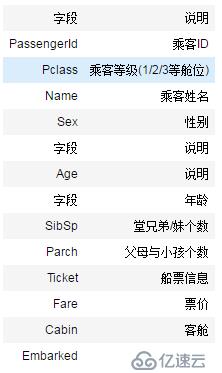
查看数据集信息
data_train.info()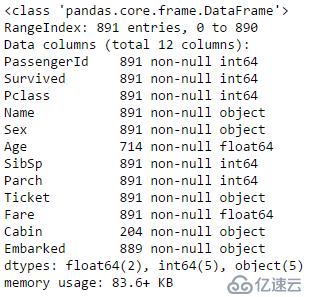
查看有缺失值的列
ata_train.columns[data_train.isnull().any()].tolist()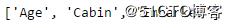
计算缺失数
age_null_count = data_train.Age.isnull().sum()
cabin_null_count = data_train.Cabin.isnull().sum()
embarked_null_count = data_train.Embarked.isnull().sum()
print('Age列缺失:%s' %age_null_count)
print('Cabin列缺失:%s' %cabin_null_count)
print('Embarked列缺失:%s' %embarked_null_count)
Age列缺失值
使用Age列中位数填充缺失值
data_train.Age.fillna(data_train.Age.median())Cabin列缺失值
Cabin列数据缺失条目较多,计算Survived列与Cabin列数据关系
Survived_cabin = data_train.Survived[pd.notnull(data_train.Cabin)].value_counts()
print(Survived_cabin)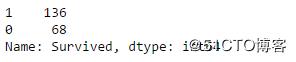
Survived_nocabin = data_train.Survived[pd.isnull(data_train.Cabin)].value_counts()
print(Survived_nocabin)
可以发现有Cabin信息的乘客获救几率要大。将Cabin列数据作为一个分类标签处理
Embarked列缺失值
使用Embarked列众数填充缺失值
data_train.Embarked.fillna(data_train.Embarked.mode())获救人数情况
# 绘制获救人数情况
data_train.Survived.value_counts().plot(kind='bar')
plt.title("获救情况")
plt.xticks([0,1], ["未获救","获救"], rotation=0)
plt.ylabel("人数")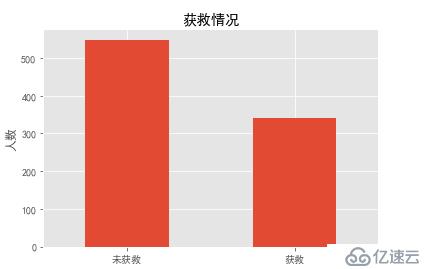
各等级的乘客年龄分布
data_train.Age[data_train.Pclass == 1].plot(kind='kde')
data_train.Age[data_train.Pclass == 2].plot(kind='kde')
data_train.Age[data_train.Pclass == 3].plot(kind='kde')
plt.xlabel("年龄")
plt.ylabel("密度")
plt.title("各等级的乘客年龄分布")
plt.legend(('一等舱', '二等舱','三等舱'),loc='best')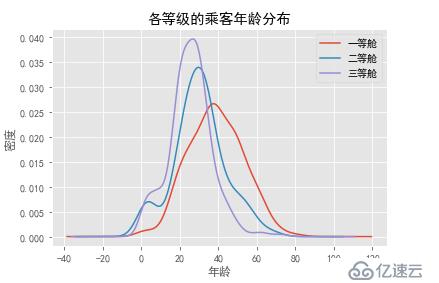
各乘客等级的获救情况
Survived_0 = data_train.Pclass[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Pclass[data_train.Survived == 1].value_counts()
df=pd.DataFrame({'获救':Survived_1, '未获救':Survived_0})
df.plot(kind='bar', stacked=True)
plt.title("船舱等级的获救情况")
plt.xlabel("船舱等级")
plt.ylabel("人数")
plt.xticks(rotation=0)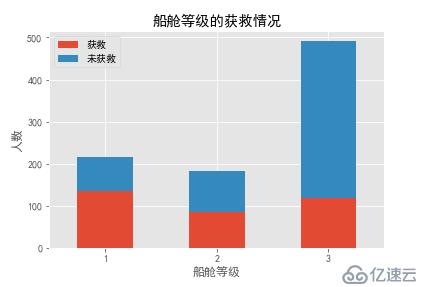
绘制登船口岸上船人数
data_train.Embarked.value_counts().plot(kind='bar')
plt.title("各登船口岸上船人数")
plt.ylabel("人数")
plt.xticks(rotation=0)
各登录港口的获救情况
Survived_0 = data_train.Embarked[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Embarked[data_train.Survived == 1].value_counts()
df=pd.DataFrame({'获救':Survived_1, '未获救':Survived_0})
df.plot(kind='bar', stacked=True)
plt.title("登陆港口乘客的获救情况")
plt.xlabel("登陆港口")
plt.ylabel("人数")
plt.xticks(rotation=0)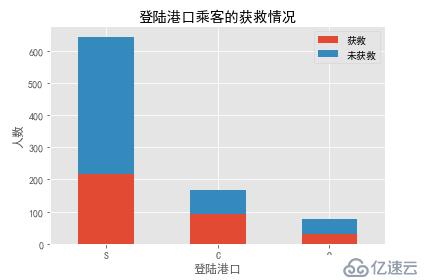
各性别的获救情况
Survived_m = data_train.Survived[data_train.Sex == 'male'].value_counts()
Survived_f = data_train.Survived[data_train.Sex == 'female'].value_counts()
df=pd.DataFrame({'男性':Survived_m, '女性':Survived_f})
df.plot(kind='bar', stacked=True)
plt.title("男女性别获救情况")
plt.xlabel("性别")
plt.ylabel("人数")
plt.xticks([0,1], ["未获救","获救"], rotation=0)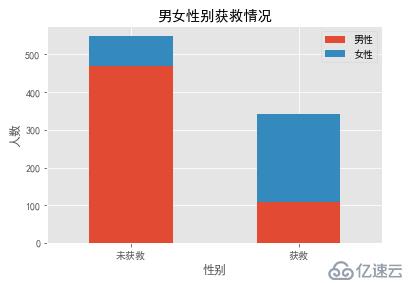
SibSp字段获救情况
SibSp_0 = data_train.SibSp[data_train.Survived == 0].value_counts()
SibSp_1 = data_train.SibSp[data_train.Survived == 1].value_counts()
SibSp_df=pd.DataFrame({'未获救':SibSp_0, '获救':SibSp_1})
SibSp_df.plot(kind='bar',stacked=True)
plt.title("堂兄弟/妹个数获救情况")
plt.xlabel("堂兄弟/妹个数")
plt.ylabel("人数")
plt.xticks(rotation=0)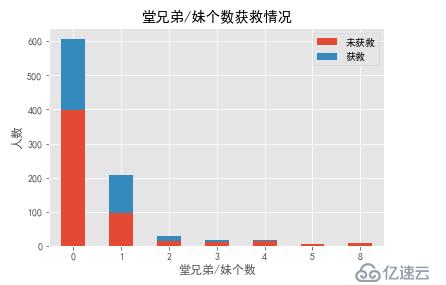
Parch字段获救情况
Parch_0 = data_train.Parch[data_train.Survived == 0].value_counts()
Parch_1 = data_train.Parch[data_train.Survived == 1].value_counts()
Parch_df=pd.DataFrame({'未获救':Parch_0, '获救':Parch_1})
Parch_df.plot(kind='bar',stacked=True)
plt.title("父母与小孩个数获救情况")
plt.xlabel("父母与小孩个数")
plt.ylabel("人数")
plt.xticks(rotation=0)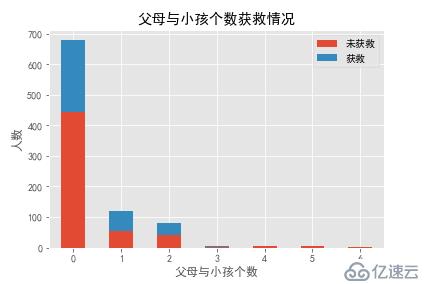
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





