这篇文章主要介绍了Redis数据结构中链表与字典的使用案例,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
关于链表的基础概念其实你在学习Redis之前一定积累了不少,所以本文将默认你已经掌握了链表相关的基础知识,而Redis的链表其实也就是普通的链表~
因为Redis是使用C语言编写的,因此Redis的数据结构的定义都是使用C语法定义的,你不需要完全理解下方C语言声明结构体的语法,但我认为依靠大家的Java知识也能理解这就像是在Java中定义了一个链表对象
Redis链表节点的结构
typedef struct listNode {
struct listNode *prev; //指向前一个链表节点
struct listNode *next; //指向后一个链表节点
void *value; //当前节点的值(可以按需设定不同数据类型的value)
} listNode;很明显,当每一个节点内记录了前后两个节点位置之后,链表节点之间就能够彼此前后相连,组成双向通行车道(可以双向遍历)
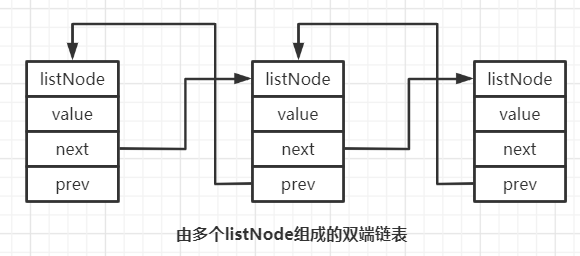
上面讲解了Redis的链表的节点表示,并由此引申了一下可以借此构建Redis双端链表,而事实上,对于每一个存在的双端链表,Redis使用一个list结构来表示
typedef struct list {
listNode *head; //表头节点
listNode *tail; //表尾节点
unsigned long len; //链表所包含的节点的数量
void *(*dup)(void *ptr); //节点复制函数
void (*free)(void *ptr); //节点释放函数
void (*match)(void *ptr, void *key);//节点值对比函数
} list;很明显,你看到三个好像是返回值为void的函数,但是看不懂C语法,没关系,传统后端功夫,自然是点到为止
我不想现在就告诉你,链表被广泛用于实现Redis的各种功能,比如列表键、发布于订阅、慢查询、监视器等,等我们后面讲到这几部分的时候,白泽再结合链表和你细说~
和链表一样,Redis所使用的C语言并没有内置字典这种数据结构,因此Redis构建了自己的字典实现。如果你学过数据结构,你会发现Redis的字典事实上就是数据结构中的邻接表,即使没学过,往下看就好啦~
数组 + 链表 ==> 邻接表,实锤
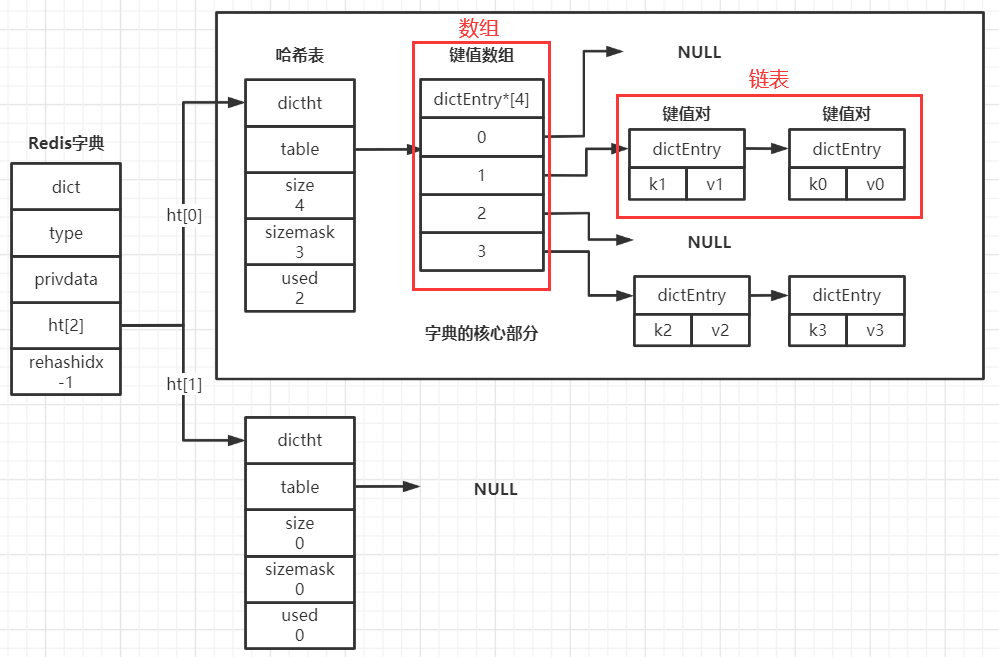
还记得吗,上面我们说Redis链表可以用list描述,但是链表存储的数据本质上,是由一系列listNode节点通过前后指针相连存储的;类似的,Redis字典可以用如下dict描述,但是字典存储的数据本质上,是由数组 + 若干链表组合得到的数据结构存储的,字典dict结构如下:
typedef struct dict {
dictType *type; //类型特定函数
void *privdata; //私有数据
dictht ht[2]; //哈希表数组
int trehashidx; //rehash索引,当rehash不在进行时,值为-1
} dict;现在你只需要关注其中的哈希表数组ht[2],它的数据类型为dictht,因此也是一种复合的数据结构,如下:
typedef struct dictht {
dictEntry **table; //哈希表数组
unsigned long size; //哈希表大小
unsigned long sizemax; //哈希表大小掩码,用于计算索引值,等于size - 1
unsigned long used; //该哈希表已有节点的数量
} dictht;哈希表dictht是Redis字典的核心,dictht的四个属性中,size、sizemax、used都是用于描述table属性整体状态。看到这你就明白了,dictht的核心是dictEntry类型的table属性(再次提醒,如果没有C语言的基础,本文中一切你看不懂的语法,包括数据类型,你只需要一眼带过即可,我们的目的是学习Redis的设计思想)
table属性是一个数组,数组中的每个元素都是一个指向dictEntry结构的指针,每个dictEntry结构保存一个键值对,并含有一个指向下一个dictEntry的指针,结构如下:
typedef struct dictEntry {
void *key; //键
union { //值(可以是一个指针,可以是一个uint64_t类型的整数,也可以是一个int64_t类型的整数)
void *val;
uint64_t u64;
int64_t s64;
} v;
struct dictEntry *next;//指向下个哈希表节点,形成链表
} dictEntry;我们知道,字典是用来存储数据的,并且是以键值对的形式存储的,那么我每次存入一个键值对放在字典的哪里?这就是哈希算法为你解决的事情:程序需要先根据键值对的键计算出哈希值和索引值,然后再根据索引值,将包含新键值对的哈希表节点放到哈希表数组的指定索引上面
比如我已经有下面这个字典,然后要插入一个键值对数据:k1 : v1,则程序有如下计算过程:(用户只是往Redis服务器中插入了一条数据,下面都是程序内部的工作~)
hash = dict->type->hashFunction(k1); //计算k1键的hash值(得到某个数值)
index = hash & dict->ht[0].sizemask = 1; //计算k1键插入位置的索引值
解决键冲突
键冲突:当不同的key值计算得到的dictEntry索引值相同时,就称发生键冲突(我要插入的位置已经被占用了,插入使得链表长度由1变多,当然第一次插入不算冲突)
解决方法:
就像上面我要插入一个k1 :v1的键值对,并计算得到插入位置的索引为1(但是distEntry数组中索引为1的位置已经有k0 :v0键值对存放了),因此程序会在哈希表ht[0]的dictEntry数组的索引为1的位置上插入一个dictEntry节点,放在原本链表首部的前一位置(抢占首位),其中存放着k1 : v1键值对,插入后的图如下:
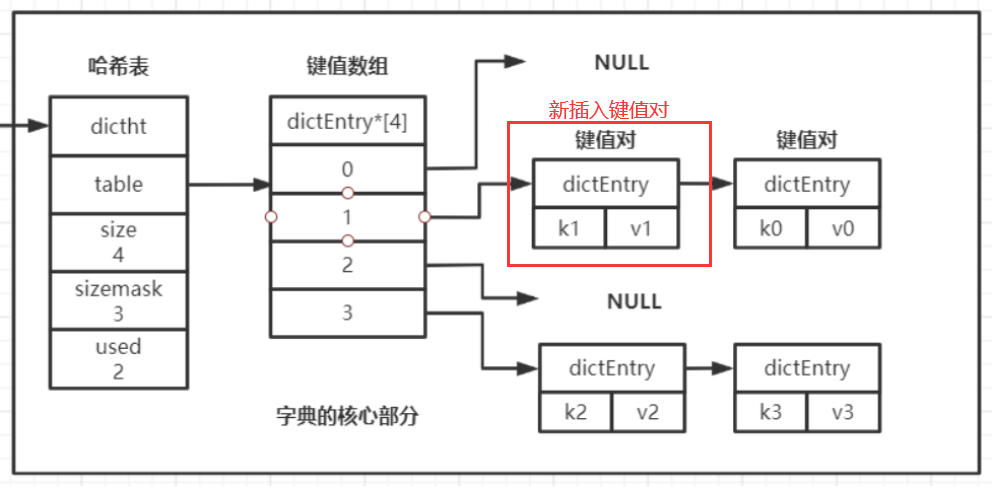
你可能疑惑新插入的键值对的位置在每个dictEntry链表的最前面,而不是尾部,原因是每个dictEntry中除了保存键值对之外,只记录了下一个dictEntry的地址(上面我已经给出了dictEntry的结构了~),程序无法直接得到dictEntry链表的最后一个节点,但可以直接得到第一个节点(通过dictEntry数组索引直接定位),因此每次插入的dictEntry节点(键值对)都将直接插入到对应索引的链表的头部(因此dictEntry数组的内容是不断在变的)
一句话来说:distEntry数组帮助使用索引定位,distEntry链表,用于处理冲突,不断维护所存储的键值对数据
随着操作的不断执行(增、删、改、查),哈希表保存的键值对会逐渐增多或者减少,为了让哈希表的负载因子维持在一个合理范围内,当哈希表保存的键值对数量太多或太少时,程序会对哈希表的大小进行相应的扩展或者收缩(不知道你是否记得还有一个哈希表ht[1]的存在,这个表就是为了和ht[0]配合进行rehash而存在的)
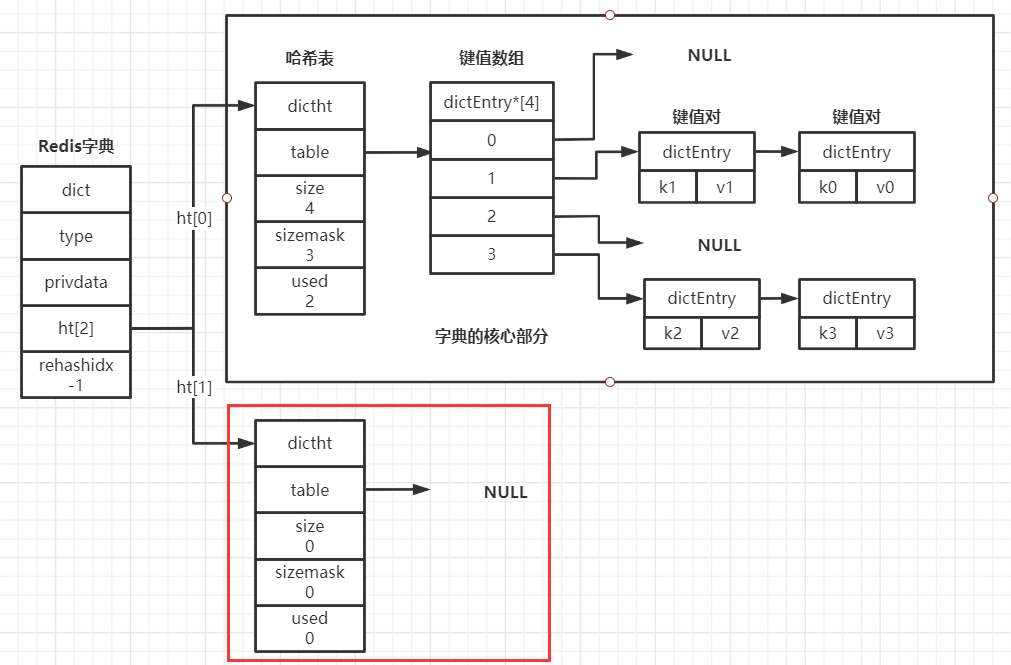
rehash步骤:
为字典的ht[1]哈希表分配空间
如果程序执行扩展操作:
ht[1].size = 第一个大于等于ht[0].used * 2(ht[0]已经使用的空间大小乘2)的2的n次方幂
如果程序执行收缩操作:
ht[1].size = 第一个大于等于ht[0].used(ht[0]已经使用的空间大小)的2的n次方幂
将保存在ht[0]上的键值对rehash到ht[1]上,因为size不同,所以是重新hash,而不是整体复制
当ht[0]内键值对全部迁移到ht[1]中后,释放ht[0],然后将ht[1]和ht[0]的互换(rehash结束),此时ht[0]就是一个rehash后的哈希表,而ht[1]依旧为空表,为下次rehash做准备
上面提到的在哈希表ht[0]的负载因子过大或者过小会触发rehash,但是,事实上rehash迁移的过程不是一蹴而就的(很明显,如果数据ht[0]的数据很多,每次rehash如果都迁移全部数据,需要花费较大时间等待,用户在rehash期间访问Redis服务器将会陷入无响应的状态)
渐进式过程:
将rehash的过程分摊在后续的每次增、删、改、查操作上,在rehash期间,每次对字典执行操作,程序除了执行指定操作外,还会顺带将ht[0]哈希表在rehashidx索引(从0开始,-1表示rehash未开始)上的所有键值对rehash到ht[1],当每次局部rehash工作完成后,程序将rehashidx属性的值增一
注意:每次对字典进行增、删、改、查会在ht[0]和ht[1]上同时进行,比如查找一个键,则会现在ht[0]上查找,没找到再去ht[1]上查找,诸如此类,除了增加操作每次都将直接hash到ht[1]上,不会对ht[0]执行任何添加操作
感谢你能够认真阅读完这篇文章,希望小编分享的“Redis数据结构中链表与字典的使用案例”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



