小编给大家分享一下java算法之余弦相似度计算字符串相似率的示例分析,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
Java中的集合主要分为四类:1、List列表:有序的,可重复的;2、Queue队列:有序,可重复的;3、Set集合:不可重复;4、Map映射:无序,键唯一,值不唯一。
功能需求:最近在做通过爬虫技术去爬取各大相关网站的新闻,储存到公司数据中。这里面就有一个技术点,就是如何保证你已爬取的新闻,再有相似的新闻
或者一样的新闻,那就不存储到数据库中。(因为有网站会去引用其它网站新闻,或者把其它网站新闻拿过来稍微改下内容就发布到自己网站中)。
先推荐一篇博客,对于余弦相似度算法的理论讲的比较清晰,我们也是按照这个方式来计算相似度的。网址:相似度算法之余弦相似度。
我这边先把计算两个字符串的相似度理论知识再梳理一遍。
(1)首先是要明白通过向量来计算相识度公式。
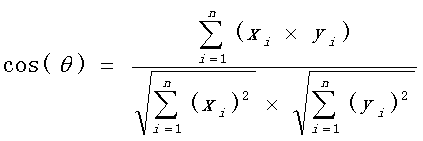
(2)明白:余弦值越接近1,也就是两个向量越相似,这就叫"余弦相似性",
余弦值越接近0,也就是两个向量越不相似,也就是这两个字符串越不相似。
举一个例子来说明,用上述理论计算文本的相似性。为了简单起见,先从句子着手。
句子A:这只皮靴号码大了。那只号码合适。
句子B:这只皮靴号码不小,那只更合适。
怎样计算上面两句话的相似程度?
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。
第一步,分词。
句子A:这只/皮靴/号码/大了。那只/号码/合适。
句子B:这只/皮靴/号码/不/小,那只/更/合适。
第二步,计算词频。(也就是每个词语出现的频率)
句子A:这只1,皮靴1,号码2,大了1。那只1,合适1,不0,小0,更0
句子B:这只1,皮靴1,号码1,大了0。那只1,合适1,不1,小1,更1
第三步,写出词频向量。
句子A:(1,1,2,1,1,1,0,0,0)
句子B:(1,1,1,0,1,1,1,1,1)
第四步:运用上面的公式:计算如下:
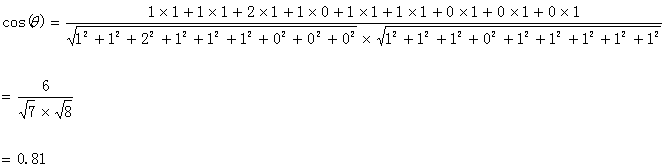
计算结果中夹角的余弦值为0.81非常接近于1,所以,上面的句子A和句子B是基本相似的
我把我们实际开发过程中字符串相似率计算代码分享出来。
展示一些主要jar包
<!--结合操作工具包-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.5</version>
</dependency>
<!--bean实体注解工具包-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<!--汉语言包,主要用于分词-->
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.6.5</version>
</dependency>/**
* 计算两个字符串的相识度
*/
public class Similarity {
public static final String content1="今天小小和爸爸一起去摘草莓,小小说今天的草莓特别的酸,而且特别的小,关键价格还贵";
public static final String content2="今天小小和妈妈一起去草原里采草莓,今天的草莓味道特别好,而且价格还挺实惠的";
public static void main(String[] args) {
double score=CosineSimilarity.getSimilarity(content1,content2);
System.out.println("相似度:"+score);
score=CosineSimilarity.getSimilarity(content1,content1);
System.out.println("相似度:"+score);
}
}先看运行结果:

通过运行结果得出:
(1)第一次比较相似率为:0.772853 (说明这两条句子还是挺相似的),第二次比较相似率为:1.0 (说明一模一样)。
(2)我们可以看到这个句子的分词效果,后面是词性。
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.seg.common.Term;
import java.util.List;
import java.util.stream.Collectors;
/**
* 中文分词工具类*/
public class Tokenizer {
/**
* 分词*/
public static List<Word> segment(String sentence) {
//1、 采用HanLP中文自然语言处理中标准分词进行分词
List<Term> termList = HanLP.segment(sentence);
//上面控制台打印信息就是这里输出的
System.out.println(termList.toString());
//2、重新封装到Word对象中(term.word代表分词后的词语,term.nature代表改词的词性)
return termList.stream().map(term -> new Word(term.word, term.nature.toString())).collect(Collectors.toList());
}
}这里面真正用到的其实就词名和权重。
import lombok.Data;
import java.util.Objects;
/**
* 封装分词结果*/
@Data
public class Word implements Comparable {
// 词名
private String name;
// 词性
private String pos;
// 权重,用于词向量分析
private Float weight;
public Word(String name, String pos) {
this.name = name;
this.pos = pos;
}
@Override
public int hashCode() {
return Objects.hashCode(this.name);
}
@Override
public boolean equals(Object obj) {
if (obj == null) {
return false;
}
if (getClass() != obj.getClass()) {
return false;
}
final Word other = (Word) obj;
return Objects.equals(this.name, other.name);
}
@Override
public String toString() {
StringBuilder str = new StringBuilder();
if (name != null) {
str.append(name);
}
if (pos != null) {
str.append("/").append(pos);
}
return str.toString();
}
@Override
public int compareTo(Object o) {
if (this == o) {
return 0;
}
if (this.name == null) {
return -1;
}
if (o == null) {
return 1;
}
if (!(o instanceof Word)) {
return 1;
}
String t = ((Word) o).getName();
if (t == null) {
return 1;
}
return this.name.compareTo(t);
}
}import com.jincou.algorithm.tokenizer.Tokenizer;
import com.jincou.algorithm.tokenizer.Word;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.util.CollectionUtils;
import java.math.BigDecimal;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.atomic.AtomicInteger;
/**
* 判定方式:余弦相似度,通过计算两个向量的夹角余弦值来评估他们的相似度 余弦夹角原理: 向量a=(x1,y1),向量b=(x2,y2) similarity=a.b/|a|*|b| a.b=x1x2+y1y2
* |a|=根号[(x1)^2+(y1)^2],|b|=根号[(x2)^2+(y2)^2]*/
public class CosineSimilarity {
protected static final Logger LOGGER = LoggerFactory.getLogger(CosineSimilarity.class);
/**
* 1、计算两个字符串的相似度
*/
public static double getSimilarity(String text1, String text2) {
//如果wei空,或者字符长度为0,则代表完全相同
if (StringUtils.isBlank(text1) && StringUtils.isBlank(text2)) {
return 1.0;
}
//如果一个为0或者空,一个不为,那说明完全不相似
if (StringUtils.isBlank(text1) || StringUtils.isBlank(text2)) {
return 0.0;
}
//这个代表如果两个字符串相等那当然返回1了(这个我为了让它也分词计算一下,所以注释掉了)
// if (text1.equalsIgnoreCase(text2)) {
// return 1.0;
// }
//第一步:进行分词
List<Word> words1 = Tokenizer.segment(text1);
List<Word> words2 = Tokenizer.segment(text2);
return getSimilarity(words1, words2);
}
/**
* 2、对于计算出的相似度保留小数点后六位
*/
public static double getSimilarity(List<Word> words1, List<Word> words2) {
double score = getSimilarityImpl(words1, words2);
//(int) (score * 1000000 + 0.5)其实代表保留小数点后六位 ,因为1034234.213强制转换不就是1034234。对于强制转换添加0.5就等于四舍五入
score = (int) (score * 1000000 + 0.5) / (double) 1000000;
return score;
}
/**
* 文本相似度计算 判定方式:余弦相似度,通过计算两个向量的夹角余弦值来评估他们的相似度 余弦夹角原理: 向量a=(x1,y1),向量b=(x2,y2) similarity=a.b/|a|*|b| a.b=x1x2+y1y2
* |a|=根号[(x1)^2+(y1)^2],|b|=根号[(x2)^2+(y2)^2]
*/
public static double getSimilarityImpl(List<Word> words1, List<Word> words2) {
// 向每一个Word对象的属性都注入weight(权重)属性值
taggingWeightByFrequency(words1, words2);
//第二步:计算词频
//通过上一步让每个Word对象都有权重值,那么在封装到map中(key是词,value是该词出现的次数(即权重))
Map<String, Float> weightMap1 = getFastSearchMap(words1);
Map<String, Float> weightMap2 = getFastSearchMap(words2);
//将所有词都装入set容器中
Set<Word> words = new HashSet<>();
words.addAll(words1);
words.addAll(words2);
AtomicFloat ab = new AtomicFloat();// a.b
AtomicFloat aa = new AtomicFloat();// |a|的平方
AtomicFloat bb = new AtomicFloat();// |b|的平方
// 第三步:写出词频向量,后进行计算
words.parallelStream().forEach(word -> {
//看同一词在a、b两个集合出现的此次
Float x1 = weightMap1.get(word.getName());
Float x2 = weightMap2.get(word.getName());
if (x1 != null && x2 != null) {
//x1x2
float oneOfTheDimension = x1 * x2;
//+
ab.addAndGet(oneOfTheDimension);
}
if (x1 != null) {
//(x1)^2
float oneOfTheDimension = x1 * x1;
//+
aa.addAndGet(oneOfTheDimension);
}
if (x2 != null) {
//(x2)^2
float oneOfTheDimension = x2 * x2;
//+
bb.addAndGet(oneOfTheDimension);
}
});
//|a| 对aa开方
double aaa = Math.sqrt(aa.doubleValue());
//|b| 对bb开方
double bbb = Math.sqrt(bb.doubleValue());
//使用BigDecimal保证精确计算浮点数
//double aabb = aaa * bbb;
BigDecimal aabb = BigDecimal.valueOf(aaa).multiply(BigDecimal.valueOf(bbb));
//similarity=a.b/|a|*|b|
//divide参数说明:aabb被除数,9表示小数点后保留9位,最后一个表示用标准的四舍五入法
double cos = BigDecimal.valueOf(ab.get()).divide(aabb, 9, BigDecimal.ROUND_HALF_UP).doubleValue();
return cos;
}
/**
* 向每一个Word对象的属性都注入weight(权重)属性值
*/
protected static void taggingWeightByFrequency(List<Word> words1, List<Word> words2) {
if (words1.get(0).getWeight() != null && words2.get(0).getWeight() != null) {
return;
}
//词频统计(key是词,value是该词在这段句子中出现的次数)
Map<String, AtomicInteger> frequency1 = getFrequency(words1);
Map<String, AtomicInteger> frequency2 = getFrequency(words2);
//如果是DEBUG模式输出词频统计信息
// if (LOGGER.isDebugEnabled()) {
// LOGGER.debug("词频统计1:\n{}", getWordsFrequencyString(frequency1));
// LOGGER.debug("词频统计2:\n{}", getWordsFrequencyString(frequency2));
// }
// 标注权重(该词出现的次数)
words1.parallelStream().forEach(word -> word.setWeight(frequency1.get(word.getName()).floatValue()));
words2.parallelStream().forEach(word -> word.setWeight(frequency2.get(word.getName()).floatValue()));
}
/**
* 统计词频
* @return 词频统计图
*/
private static Map<String, AtomicInteger> getFrequency(List<Word> words) {
Map<String, AtomicInteger> freq = new HashMap<>();
//这步很帅哦
words.forEach(i -> freq.computeIfAbsent(i.getName(), k -> new AtomicInteger()).incrementAndGet());
return freq;
}
/**
* 输出:词频统计信息
*/
private static String getWordsFrequencyString(Map<String, AtomicInteger> frequency) {
StringBuilder str = new StringBuilder();
if (frequency != null && !frequency.isEmpty()) {
AtomicInteger integer = new AtomicInteger();
frequency.entrySet().stream().sorted((a, b) -> b.getValue().get() - a.getValue().get()).forEach(
i -> str.append("\t").append(integer.incrementAndGet()).append("、").append(i.getKey()).append("=")
.append(i.getValue()).append("\n"));
}
str.setLength(str.length() - 1);
return str.toString();
}
/**
* 构造权重快速搜索容器
*/
protected static Map<String, Float> getFastSearchMap(List<Word> words) {
if (CollectionUtils.isEmpty(words)) {
return Collections.emptyMap();
}
Map<String, Float> weightMap = new ConcurrentHashMap<>(words.size());
words.parallelStream().forEach(i -> {
if (i.getWeight() != null) {
weightMap.put(i.getName(), i.getWeight());
} else {
LOGGER.error("no word weight info:" + i.getName());
}
});
return weightMap;
}
}这个具体实现代码因为思维很紧密所以有些地方写的比较绕,同时还手写了AtomicFloat原子类。
import java.util.concurrent.atomic.AtomicInteger;
/**
* jdk没有AtomicFloat,写一个
*/
public class AtomicFloat extends Number {
private AtomicInteger bits;
public AtomicFloat() {
this(0f);
}
public AtomicFloat(float initialValue) {
bits = new AtomicInteger(Float.floatToIntBits(initialValue));
}
//叠加
public final float addAndGet(float delta) {
float expect;
float update;
do {
expect = get();
update = expect + delta;
} while (!this.compareAndSet(expect, update));
return update;
}
public final float getAndAdd(float delta) {
float expect;
float update;
do {
expect = get();
update = expect + delta;
} while (!this.compareAndSet(expect, update));
return expect;
}
public final float getAndDecrement() {
return getAndAdd(-1);
}
public final float decrementAndGet() {
return addAndGet(-1);
}
public final float getAndIncrement() {
return getAndAdd(1);
}
public final float incrementAndGet() {
return addAndGet(1);
}
public final float getAndSet(float newValue) {
float expect;
do {
expect = get();
} while (!this.compareAndSet(expect, newValue));
return expect;
}
public final boolean compareAndSet(float expect, float update) {
return bits.compareAndSet(Float.floatToIntBits(expect), Float.floatToIntBits(update));
}
public final void set(float newValue) {
bits.set(Float.floatToIntBits(newValue));
}
public final float get() {
return Float.intBitsToFloat(bits.get());
}
@Override
public float floatValue() {
return get();
}
@Override
public double doubleValue() {
return (double) floatValue();
}
@Override
public int intValue() {
return (int) get();
}
@Override
public long longValue() {
return (long) get();
}
@Override
public String toString() {
return Float.toString(get());
}
}把大致思路再捋一下:
(1)先分词:分词当然要按一定规则,不然随便分那也没有意义,那这里通过采用HanLP中文自然语言处理中标准分词进行分词。
(2)统计词频:就统计上面词出现的次数。
(3)通过每一个词出现的次数,变成一个向量,通过向量公式计算相似率。
以上是“java算法之余弦相似度计算字符串相似率的示例分析”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



