本篇内容主要讲解“如何使用Centos7系统搭建Hadoop-3.1.4完全分布式集群”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“如何使用Centos7系统搭建Hadoop-3.1.4完全分布式集群”吧!
未来的竞争,是数据之争。大数据本质上是Hadoop的生态群,下面是常用技术词汇
ETL:代表提取、转换和加载。
Hadoop:分布式系统基础架构
HDFS:分布式文件系统
HBase:大数据的NoSQL数据库
Hive:数据仓库工具
DAG :第二代计算引擎
Spark:第三代数据处理引擎
Flink:第四代数据处理引擎
MapReduce:最初的并行计算框架
Sqoop:nosql数据库和传统数据库之间传输数据的工具
Hive:数据仓库工具
Storm:分布式实时计算系统
Flume:分布式的海量日志采集系统。
Kafka:分布式发布订阅消息系统
ElasticSearch:分布式搜索引擎
Kibana:ElasticSearch大数据的图形化展示工具
Logstash:Elasticsearch 的传送带
Neo4j:nosql图形数据库
Oozie:工作流调度系统 -YARN:作业调度和集群资源管理的框架
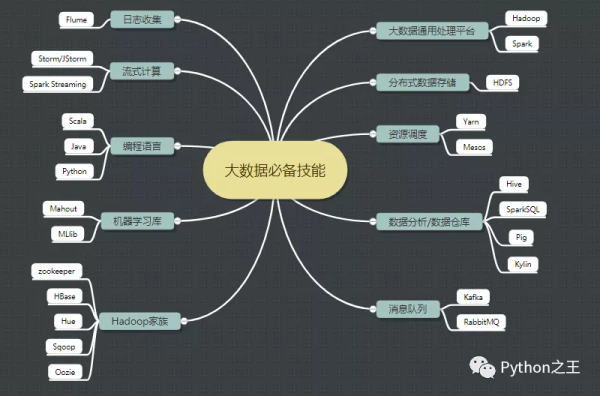
大数据是基于集群的分布式系统。所谓集群是指一组独立的计算机系统构成的一多处理器系统,它们之间通过网络实现进程间的通信,让若干台计算机联合起来工作(服务),可以是并行的,也可以是做备份。
分布式 :分布式的主要工作是分解任务,将职能拆解,多个人在一起做不同的事
集群:集群主要是将同一个业务,部署在多个服务器上 ,多个人在一起做同样的事
Hadoop是Apache旗下的一个用Java语言实现开源软件框架,是一个存储和计算大规模数据的软件平台。
Hadoop是Apache Lucene创始人 Doug Cutting 创建的,最早起源一个Nutch项目。
2003年Google发表了一篇GFS论文,为大规模数据存储提供了可行的解决方案。
2004年 Google发表论文MapReduce系统,为大规模数据计算提供可行的解决方案。Nutch的开发人员以谷歌的论文为基础,完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目Hadoop。
到2008年1月,Hadoop成为Apache顶级项目,迎来了它的快速发展期。
如今,国内外的互联网巨头基本都在使用Hadoop框架作为大数据解决方案,越来越多的企业将Hadoop 技术作为进入大数据领域的必备技术。
目前,Hadoop发行版本分为开源社区版和商业版。
开源社区版:指由Apache软件基金会维护的版本,是官方维护的版本体系,版本丰富,兼容性稍差。
商业版:指由第三方商业公司在社区版Hadoop基础上进行了一些修改、整合以及各个服务组件兼容性测试而发行的版本,比较著名的有cloudera的CDH等。
开源社区版本:一般使用2.x版本系列,3.x版本系列:该版本是最新版本,但是还不太稳定。
废话不说了,开始今天的主题:使用三台Centos7系统搭建Hadoop2.X完全分布式集群
去年使用CentOS 7搭建了hadoop3.X分布式集群,由于换了电脑,考虑到电脑安装了很多前其他的东西,这次是使用二台Centos7系统搭建Hadoop完全分布式集群,虽然Centos更新到8版本,但是很多大数据学习都是选择基于Centos7系统搭建。这里不搭建一台的伪分布式,搭建的版本是目前Haddop3.X稳定的Hadoop-3.1.4。
去年对应的文章教程:
https://blog.csdn.net/weixin_44510615/article/details/104625802
https://blog.csdn.net/weixin_44510615/article/details/106540129
Centos7的下载地址:http://mirrors.aliyun.com/centos/7.9.2009/isos/x86_64/CentOS-7-x86_64-DVD-2009.iso。共4.8g。
在集群搭建前的准备,需要在VMwear Workstation搭建一个Centos7系统,关于搭建过程,由于简单,这里直接省略。
在通过物理机连接虚拟机的时候,需要有VMnet1和VMnet8两个虚拟网卡。
如果安装Vmware没有VMnet1和VMnet8,据我以前踩的坑,网上说安装cclear软件包进行注册表的删除,那是不断删除下载Vmware,并没有解决问题,最终采用系统刷机的办法,得以解决。
因此,搭建虚拟机的前提是,本地主机必须有虚拟本地环境,不然你怎么搞都是白搭。
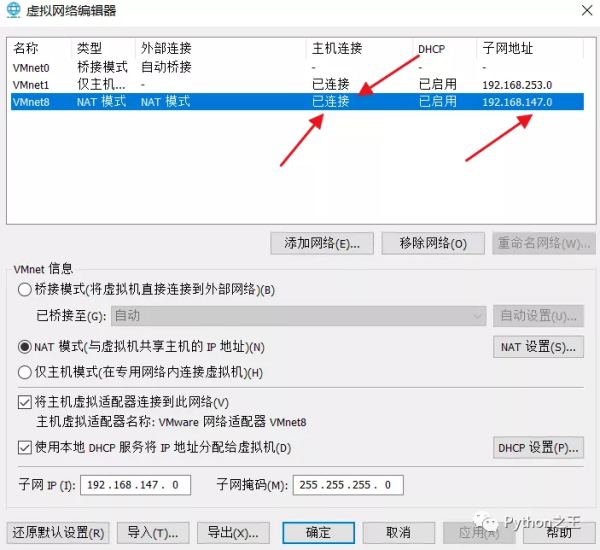
在这里插入图片描述
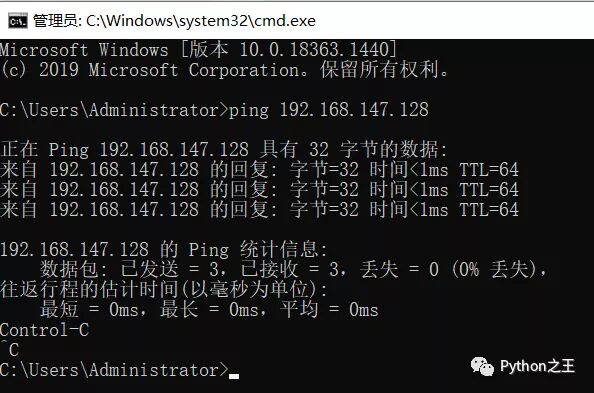
在此,就可以实现本地ping通虚拟机的IP,实现本地和虚拟机的信息连接。
这样,就可以通过xshell对centos7进行远程的连接。
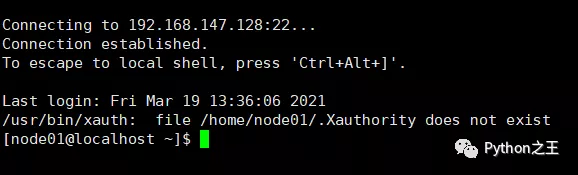
在第一次使用Centos7,需要对创建的用户提供管理员的权限,因此需要使用root账号进行相关的修改,防止出现node01 不在 sudoers 文件中。此事将被报告。的报错。

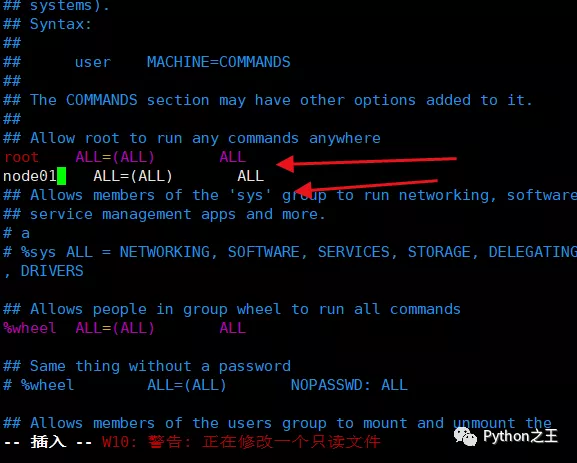
使 用 :wq! 保存退出、
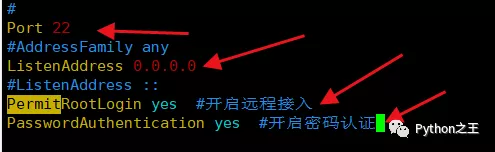
如果远程连接失败,应该没有开发端口和IP地址。需要设置sudo vim /etc/ssh/sshd_config
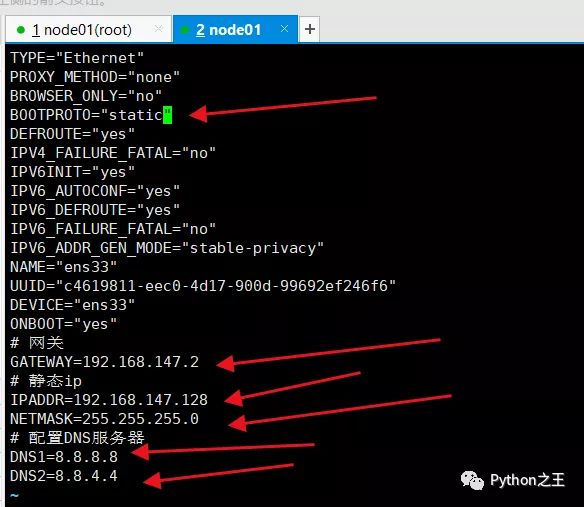
设置静态ip,通过ifconfig

重启网卡
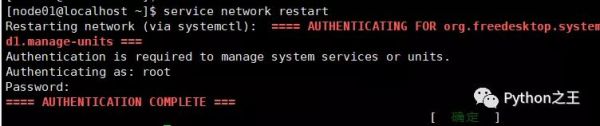
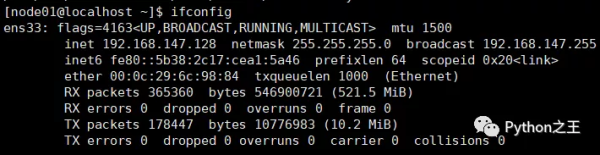
一开始下载速度很慢,需要配置阿里云yum源,下面来源官方文档,使用的是root账号。
#配置阿里云yum源 yum install -y wget cd /etc/yum.repos.d/ mv CentOS-Base.repo CentOS-Base.repo.bak wget http://mirrors.aliyun.com/repo/Centos-7.repo mv Centos-7.repo CentOS-Base.repo #配置epel源 wget https://mirrors.aliyun.com/repo/epel-7.repo #清除缓存并更新 yum clean all yum makecache yum update
由于 hadoop 框架的启动是依赖 java 环境,因此需要准备 jdk 环境。目前,OpenJDK 和 Oracle Java 是最主要的两个 Java 实现。卸载Linux系统原有jdkOpenJDK,然后安装Oracle Java。
具体博客:https://blog.csdn.net/weixin_44510615/article/details/104425843

并通过设置静态分别为192.168.147.129,并将三台Centos7主机名分别设置node01和node02,区别centos7机器。
之前创建用户名使用node01,发现自己搞错了,于是把两个主机的用户名都设置为hadoop。
关于Centos7修改用户名:[root@node01 ~]# usermod -l hadoop -d /home/hadoop -m node01。
自此我们有两台Centos电脑,在hadoop集群不使用root账号。

xshell均可连接成功。
[root@node01 ~]# vim /etc/sysconfig/network ######### HOSTNAME=node01 [root@node01 ~]# vim /etc/hosts ######### 192.168.147.128 node01 192.168.147.129 node02 [root@node01 ~]# systemctl stop firewalld [root@node01 ~]# systemctl disable firewalld.service [root@node02 ~]# vim /etc/sysconfig/network ######### HOSTNAME=node02 [root@node02 ~]# vim /etc/hosts ######### 192.168.147.128 node01 192.168.147.129 node02 [root@node02 ~]# systemctl stop firewalld [root@node02 ~]# systemctl disable firewalld.service
实现hadoop账号自由在node01和node02切换,具体查看我的博客:https://blog.csdn.net/weixin_44510615/article/details/104528001?

下载hadoop下载链接:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.1.4/hadoop-3.1.4.tar.gz
[hadoop@node01 ~]$ ls hadoop-3.1.4.tar.gz module wget-log 公共 模板 视频 图片 文档 下载 音乐 桌面 [hadoop@node01 ~]$ mkdir -p module/hadoop [hadoop@node01 ~]$ tar -zxvf hadoop-3.1.4.tar.gz -C module/hadoop/ [hadoop@node01 ~]$ cd module/hadoop/hadoop-3.1.4/ [hadoop@node01 hadoop-3.1.4]$ sudo mkdir -p data/tmp [hadoop@node01 hadoop-3.1.4]$ ls bin data etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share

在配置集群/分布式模式时,需要修改“hadoop/etc/hadoop”目录下的配置文件,这里仅设置正常启动所必须的设置项,包括workers、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml共5个文件,更多设置项可查看官方说明。
[hadoop@node01 hadoop]# vim hadoop-env.sh ############ export JAVA_HOME=/usr/java/jdk1.8.0_281/ [hadoop@node01 hadoop]# vim yarn-env.sh ############ export JAVA_HOME=/usr/java/jdk1.8.0_231
在Master节点的workers文件中指定Slave节点,也就是node02
[hadoop@node01 hadoop]$ vim workers [hadoop@node01 hadoop]$ cat workers node02
请把core-site.xml文件修改为如下内容:
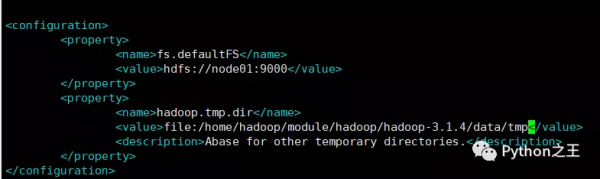
请把hdfs-site.xml文件修改为如下内容:
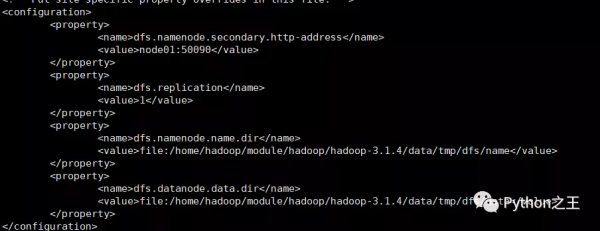
对于Hadoop的分布式文件系统HDFS而言,一般都是采用冗余存储,冗余因子通常为3,也就是说,一份数据保存三份副本。但是,本教程只有一个Slave节点作为数据节点,即集群中只有一个数据节点,数据只能保存一份,所以 ,dfs.replication的值还是设置为 1。
请把mapred-site.xml文件修改为如下内容:
[hadoop@node01 hadoop]$ cat mapred-site.xml <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
请把yarn-site.xml文件修改为如下内容:
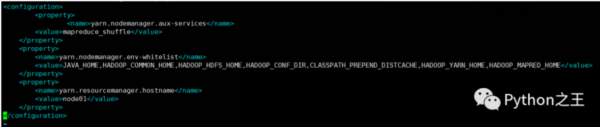
在etc/profile增加hadoop路径:
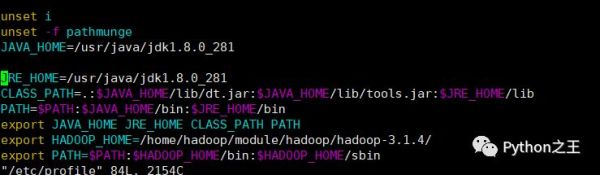

初始化HDFS,执行 namenode 初始化命令:
hdfs namenode -format
可能出现创建文件夹失败的问题,这个权限问题,使用 root 账号使用命令sudo chmod -R a+w /绝对路径。初始化HDFS失败都要把之前创建的文件夹给删除。
直接执行start-all.sh,启动 Hadoop。此时 node02上的相关服务也会被启动:
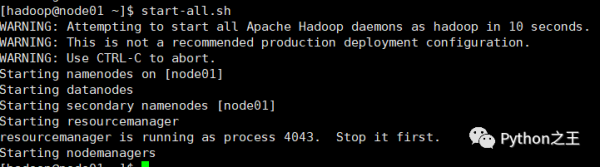
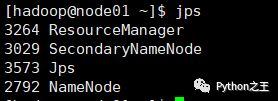
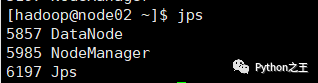
在每台服务器上使用 jps 命令查看服务进程,
或直接进入 Web-UI 界面进行查看,端口为 9870。可以看到此时有一个可用的 Datanode:

接着可以查看 Yarn 的情况,端口号为 8088 :
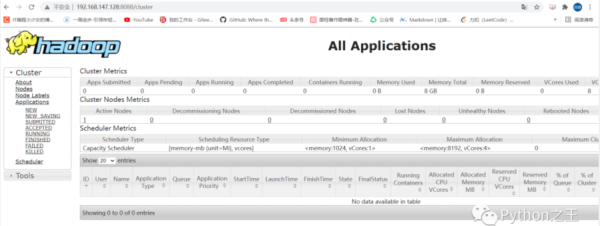
至此,Hadoop分布式集群搭建成功。
到此,相信大家对“如何使用Centos7系统搭建Hadoop-3.1.4完全分布式集群”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





