PythonдёӯжҖҺд№Ҳжһ„е»әдёҖдёӘеҶізӯ–ж ‘
жң¬зҜҮж–Үз« з»ҷеӨ§е®¶еҲҶдә«зҡ„жҳҜжңүе…іPythonдёӯжҖҺд№Ҳжһ„е»әдёҖдёӘеҶізӯ–ж ‘пјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еӯҰд№ пјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·пјҢиҜқдёҚеӨҡиҜҙпјҢи·ҹзқҖе°Ҹзј–дёҖиө·жқҘзңӢзңӢеҗ§гҖӮ
еҶізӯ–ж ‘
еҶізӯ–ж ‘жҳҜеҪ“д»ҠжңҖејәеӨ§зҡ„зӣ‘зқЈеӯҰд№ ж–№жі•зҡ„з»„жҲҗйғЁеҲҶгҖӮеҶізӯ–ж ‘еҹәжң¬дёҠжҳҜдёҖдёӘдәҢеҸүж ‘зҡ„жөҒзЁӢеӣҫпјҢе…¶дёӯжҜҸдёӘиҠӮзӮ№ж №жҚ®жҹҗдёӘзү№еҫҒеҸҳйҮҸе°ҶдёҖз»„и§ӮжөӢеҖјжӢҶеҲҶгҖӮ
еҶізӯ–ж ‘зҡ„зӣ®ж ҮжҳҜе°Ҷж•°жҚ®еҲҶжҲҗеӨҡдёӘз»„пјҢиҝҷж ·дёҖдёӘз»„дёӯзҡ„жҜҸдёӘе…ғзҙ йғҪеұһдәҺеҗҢдёҖдёӘзұ»еҲ«гҖӮеҶізӯ–ж ‘д№ҹеҸҜд»Ҙз”ЁжқҘиҝ‘дјјиҝһз»ӯзҡ„зӣ®ж ҮеҸҳйҮҸгҖӮеңЁиҝҷз§Қжғ…еҶөдёӢпјҢж ‘е°ҶиҝӣиЎҢжӢҶеҲҶпјҢдҪҝжҜҸдёӘз»„зҡ„еқҮж–№иҜҜе·®жңҖе°ҸгҖӮ
еҶізӯ–ж ‘зҡ„дёҖдёӘйҮҚиҰҒзү№жҖ§жҳҜе®ғ们еҫҲе®№жҳ“иў«и§ЈйҮҠгҖӮдҪ ж №жң¬дёҚйңҖиҰҒзҶҹжӮүжңәеҷЁеӯҰд№ жҠҖжңҜе°ұеҸҜд»ҘзҗҶи§ЈеҶізӯ–ж ‘еңЁеҒҡд»Җд№ҲгҖӮеҶізӯ–ж ‘еӣҫеҫҲе®№жҳ“и§ЈйҮҠгҖӮ
еҲ©ејҠ
еҶізӯ–ж ‘ж–№жі•зҡ„дјҳзӮ№жҳҜпјҡ
еҶізӯ–ж ‘иғҪеӨҹз”ҹжҲҗеҸҜзҗҶи§Јзҡ„规еҲҷгҖӮ
еҶізӯ–ж ‘еңЁдёҚйңҖиҰҒеӨ§йҮҸи®Ўз®—зҡ„жғ…еҶөдёӢиҝӣиЎҢеҲҶзұ»гҖӮ
еҶізӯ–ж ‘иғҪеӨҹеӨ„зҗҶиҝһз»ӯеҸҳйҮҸе’ҢеҲҶзұ»еҸҳйҮҸгҖӮ
еҶізӯ–ж ‘жҸҗдҫӣдәҶдёҖдёӘжҳҺзЎ®зҡ„жҢҮзӨәпјҢе“Әдәӣеӯ—ж®өжҳҜжңҖйҮҚиҰҒзҡ„гҖӮ
еҶізӯ–ж ‘ж–№жі•зҡ„зјәзӮ№жҳҜпјҡ
еҶізӯ–ж ‘дёҚеӨӘйҖӮеҗҲдәҺзӣ®ж ҮжҳҜйў„жөӢиҝһз»ӯеұһжҖ§еҖјзҡ„дј°и®Ўд»»еҠЎгҖӮ
еҶізӯ–ж ‘еңЁзұ»еӨҡгҖҒи®ӯз»ғж ·жң¬е°‘зҡ„еҲҶзұ»й—®йўҳдёӯе®№жҳ“еҮәй”ҷгҖӮ
еҶізӯ–ж ‘зҡ„и®ӯз»ғеңЁи®Ўз®—дёҠеҸҜиғҪеҫҲжҳӮиҙөгҖӮз”ҹжҲҗеҶізӯ–ж ‘зҡ„иҝҮзЁӢеңЁи®Ўз®—дёҠйқһеёёжҳӮиҙөгҖӮеңЁжҜҸдёӘиҠӮзӮ№дёҠпјҢжҜҸдёӘеҖҷйҖүжӢҶеҲҶеӯ—ж®өйғҪеҝ…йЎ»иҝӣиЎҢжҺ’еәҸпјҢжүҚиғҪжүҫеҲ°е…¶жңҖдҪіжӢҶеҲҶгҖӮеңЁжҹҗдәӣз®—жі•дёӯпјҢдҪҝз”Ёеӯ—ж®өз»„еҗҲпјҢеҝ…йЎ»жҗңзҙўжңҖдҪіз»„еҗҲжқғйҮҚгҖӮеүӘжһқз®—жі•д№ҹеҸҜиғҪжҳҜжҳӮиҙөзҡ„пјҢеӣ дёәи®ёеӨҡеҖҷйҖүеӯҗж ‘еҝ…йЎ»еҪўжҲҗе’ҢжҜ”иҫғгҖӮ
PythonеҶізӯ–ж ‘
PythonжҳҜдёҖз§ҚйҖҡз”Ёзј–зЁӢиҜӯиЁҖпјҢе®ғдёәж•°жҚ®з§‘еӯҰ家жҸҗдҫӣдәҶејәеӨ§зҡ„жңәеҷЁеӯҰд№ еҢ…е’Ңе·Ҙе…·гҖӮеңЁжң¬ж–ҮдёӯпјҢжҲ‘们е°ҶдҪҝз”ЁpythonжңҖи‘—еҗҚзҡ„жңәеҷЁеӯҰд№ еҢ…scikit-learnжқҘжһ„е»әеҶізӯ–ж ‘жЁЎеһӢгҖӮжҲ‘们е°ҶдҪҝз”Ёscikit learnжҸҗдҫӣзҡ„вҖңDecisionTreeClassifierвҖқз®—жі•еҲӣе»әжЁЎеһӢпјҢ然еҗҺдҪҝз”ЁвҖңplot_treeвҖқеҮҪж•°еҸҜи§ҶеҢ–жЁЎеһӢгҖӮ
жӯҘйӘӨ1пјҡеҜје…ҘеҢ…
жҲ‘们жһ„е»әжЁЎеһӢзҡ„дё»иҰҒиҪҜ件еҢ…жҳҜpandasгҖҒscikit learnе’ҢNumPyгҖӮжҢүз…§д»Јз ҒеңЁpythonдёӯеҜје…ҘжүҖйңҖзҡ„еҢ…гҖӮ
import pandas as pd # ж•°жҚ®еӨ„зҗҶ import numpy as np # дҪҝз”Ёж•°з»„ import matplotlib.pyplot as plt # еҸҜи§ҶеҢ– from matplotlib import rcParams # еӣҫеӨ§е°Ҹ from termcolor import colored as cl # ж–Үжң¬иҮӘе®ҡд№ү from sklearn.tree import DecisionTreeClassifier as dtc # ж ‘з®—жі• from sklearn.model_selection import train_test_split # жӢҶеҲҶж•°жҚ® from sklearn.metrics import accuracy_score # жЁЎеһӢеҮҶзЎ®еәҰ from sklearn.tree import plot_tree # ж ‘еӣҫ rcParams['figure.figsize'] = (25, 20)
еңЁеҜје…Ҙжһ„е»әжҲ‘们зҡ„жЁЎеһӢжүҖйңҖзҡ„жүҖжңүеҢ…д№ӢеҗҺпјҢжҳҜж—¶еҖҷеҜје…Ҙж•°жҚ®е№¶еҜ№е…¶иҝӣиЎҢдёҖдәӣEDAдәҶгҖӮ
жӯҘйӘӨ2пјҡеҜје…Ҙж•°жҚ®е’ҢEDA
еңЁиҝҷдёҖжӯҘдёӯпјҢжҲ‘们е°ҶдҪҝз”ЁpythonдёӯжҸҗдҫӣзҡ„вҖңPandasвҖқеҢ…жқҘеҜје…Ҙ并еңЁе…¶дёҠиҝӣиЎҢдёҖдәӣEDAгҖӮжҲ‘们е°Ҷе»әз«ӢжҲ‘们зҡ„еҶізӯ–ж ‘жЁЎеһӢпјҢж•°жҚ®йӣҶжҳҜдёҖдёӘиҚҜзү©ж•°жҚ®йӣҶпјҢе®ғжҳҜеҹәдәҺзү№е®ҡзҡ„ж ҮеҮҶз»ҷз—…дәәејҖзҡ„еӨ„ж–№гҖӮи®©жҲ‘们用pythonеҜје…Ҙж•°жҚ®!
Pythonе®һзҺ°пјҡ
df = pd.read_csv('drug.csv') df.drop('Unnamed: 0', axis = 1, inplace = True) print(cl(df.head(), attrs = ['bold']))иҫ“еҮәпјҡ
Age Sex BP Cholesterol Na_to_K Drug 0 23 F HIGH HIGH 25.355 drugY 1 47 M LOW HIGH 13.093 drugC 2 47 M LOW HIGH 10.114 drugC 3 28 F NORMAL HIGH 7.798 drugX 4 61 F LOW HIGH 18.043 drugY
зҺ°еңЁжҲ‘们еҜ№ж•°жҚ®йӣҶжңүдәҶдёҖдёӘжё…жҷ°зҡ„жҰӮеҝөгҖӮеҜје…Ҙж•°жҚ®еҗҺпјҢи®©жҲ‘们дҪҝз”ЁвҖңinfoвҖқеҮҪж•°иҺ·еҸ–жңүе…іж•°жҚ®зҡ„дёҖдәӣеҹәжң¬дҝЎжҒҜгҖӮжӯӨеҮҪж•°жҸҗдҫӣзҡ„дҝЎжҒҜеҢ…жӢ¬жқЎзӣ®ж•°гҖҒзҙўеј•еҸ·гҖҒеҲ—еҗҚгҖҒйқһз©әеҖји®Ўж•°гҖҒеұһжҖ§зұ»еһӢзӯүгҖӮ
Pythonе®һзҺ°пјҡ
df.info()
иҫ“еҮәпјҡ
<class 'pandas.core.frame.DataFrame'> RangeIndex: 200 entries, 0 to 199 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Age 200 non-null int64 1 Sex 200 non-null object 2 BP 200 non-null object 3 Cholesterol 200 non-null object 4 Na_to_K 200 non-null float64 5 Drug 200 non-null object dtypes: float64(1), int64(1), object(4) memory usage: 9.5+ KB
жӯҘйӘӨ3пјҡж•°жҚ®еӨ„зҗҶ
жҲ‘们еҸҜд»ҘзңӢеҲ°еғҸSex, BPе’ҢCholesterolиҝҷж ·зҡ„еұһжҖ§еңЁжң¬иҙЁдёҠжҳҜеҲҶзұ»зҡ„е’ҢеҜ№иұЎзұ»еһӢзҡ„гҖӮй—®йўҳжҳҜпјҢscikit-learnдёӯзҡ„еҶізӯ–ж ‘з®—жі•жң¬иҙЁдёҠдёҚж”ҜжҢҒXеҸҳйҮҸ(зү№еҫҒ)жҳҜвҖңеҜ№иұЎвҖқзұ»еһӢгҖӮеӣ жӯӨпјҢжңүеҝ…иҰҒе°ҶиҝҷдәӣвҖңobjectвҖқеҖјиҪ¬жҚўдёәвҖңbinaryвҖқеҖјгҖӮи®©жҲ‘们用pythonжқҘе®һзҺ°
Pythonе®һзҺ°пјҡ
for i in df.Sex.values: if i == 'M': df.Sex.replace(i, 0, inplace = True) else: df.Sex.replace(i, 1, inplace = True) for i in df.BP.values: if i == 'LOW': df.BP.replace(i, 0, inplace = True) elif i == 'NORMAL': df.BP.replace(i, 1, inplace = True) elif i == 'HIGH': df.BP.replace(i, 2, inplace = True) for i in df.Cholesterol.values: if i == 'LOW': df.Cholesterol.replace(i, 0, inplace = True) else: df.Cholesterol.replace(i, 1, inplace = True) print(cl(df, attrs = ['bold']))
иҫ“еҮәпјҡ
Age Sex BP Cholesterol Na_to_K Drug 0 23 1 2 1 25.355 drugY 1 47 1 0 1 13.093 drugC 2 47 1 0 1 10.114 drugC 3 28 1 1 1 7.798 drugX 4 61 1 0 1 18.043 drugY .. ... ... .. ... ... ... 195 56 1 0 1 11.567 drugC 196 16 1 0 1 12.006 drugC 197 52 1 1 1 9.894 drugX 198 23 1 1 1 14.020 drugX 199 40 1 0 1 11.349 drugX [200 rows x 6 columns]
жҲ‘们еҸҜд»Ҙи§ӮеҜҹеҲ°жүҖжңүзҡ„вҖңobjectвҖқеҖјйғҪиў«еӨ„зҗҶжҲҗвҖңbinaryвҖқеҖјжқҘиЎЁзӨәеҲҶзұ»ж•°жҚ®гҖӮдҫӢеҰӮпјҢеңЁиғҶеӣәйҶҮеұһжҖ§дёӯпјҢжҳҫзӨәвҖңдҪҺвҖқзҡ„еҖјиў«еӨ„зҗҶдёә0пјҢвҖңй«ҳвҖқеҲҷиў«еӨ„зҗҶдёә1гҖӮзҺ°еңЁжҲ‘们еҮҶеӨҮеҘҪд»Һж•°жҚ®дёӯеҲӣе»әеӣ еҸҳйҮҸе’ҢиҮӘеҸҳйҮҸгҖӮ
жӯҘйӘӨ4пјҡжӢҶеҲҶж•°жҚ®
еңЁе°ҶжҲ‘们зҡ„ж•°жҚ®еӨ„зҗҶдёәжӯЈзЎ®зҡ„з»“жһ„д№ӢеҗҺпјҢжҲ‘们зҺ°еңЁи®ҫзҪ®вҖңXвҖқеҸҳйҮҸ(иҮӘеҸҳйҮҸ)пјҢвҖңYвҖқеҸҳйҮҸ(еӣ еҸҳйҮҸ)гҖӮи®©жҲ‘们用pythonжқҘе®һзҺ°
Pythonе®һзҺ°пјҡ
X_var = df[['Sex', 'BP', 'Age', 'Cholesterol', 'Na_to_K']].values # иҮӘеҸҳйҮҸ y_var = df['Drug'].values # еӣ еҸҳйҮҸ print(cl('X variable samples : {}'.format(X_var[:5]), attrs = ['bold'])) print(cl('Y variable samples : {}'.format(y_var[:5]), attrs = ['bold']))иҫ“еҮәпјҡ
X variable samples : [[ 1. 2. 23. 1. 25.355] [ 1. 0. 47. 1. 13.093] [ 1. 0. 47. 1. 10.114] [ 1. 1. 28. 1. 7.798] [ 1. 0. 61. 1. 18.043]] Y variable samples : ['drugY' 'drugC' 'drugC' 'drugX' 'drugY']
жҲ‘们зҺ°еңЁеҸҜд»ҘдҪҝз”Ёscikit learnдёӯзҡ„вҖңtrain_test_splitвҖқз®—жі•е°Ҷж•°жҚ®еҲҶжҲҗи®ӯз»ғйӣҶе’ҢжөӢиҜ•йӣҶпјҢе…¶дёӯеҢ…еҗ«жҲ‘们е®ҡд№үзҡ„Xе’ҢYеҸҳйҮҸгҖӮжҢүз…§д»Јз ҒеңЁpythonдёӯжӢҶеҲҶж•°жҚ®гҖӮ
Pythonе®һзҺ°пјҡ
X_train, X_test, y_train, y_test = train_test_split(X_var, y_var, test_size = 0.2, random_state = 0) print(cl('X_train shape : {}'.format(X_train.shape), attrs = ['bold'], color = 'black')) print(cl('X_test shape : {}'.format(X_test.shape), attrs = ['bold'], color = 'black')) print(cl('y_train shape : {}'.format(y_train.shape), attrs = ['bold'], color = 'black')) print(cl('y_test shape : {}'.format(y_test.shape), attrs = ['bold'], color = 'black'))иҫ“еҮәпјҡ
X_train shape : (160, 5) X_test shape : (40, 5) y_train shape : (160,) y_test shape : (40,)
зҺ°еңЁжҲ‘们жңүдәҶжһ„е»әеҶізӯ–ж ‘жЁЎеһӢзҡ„жүҖжңү组件гҖӮжүҖд»ҘпјҢи®©жҲ‘们继з»ӯз”Ёpythonжһ„е»әжҲ‘们зҡ„жЁЎеһӢгҖӮ
жӯҘйӘӨ5пјҡе»әз«ӢжЁЎеһӢе’Ңйў„жөӢ
еңЁscikitеӯҰд№ еҢ…жҸҗдҫӣзҡ„вҖңDecisionTreeClassifierвҖқз®—жі•зҡ„её®еҠ©дёӢпјҢжһ„е»әеҶізӯ–ж ‘жҳҜеҸҜиЎҢзҡ„гҖӮд№ӢеҗҺпјҢжҲ‘们еҸҜд»ҘдҪҝз”ЁжҲ‘们и®ӯз»ғиҝҮзҡ„жЁЎеһӢжқҘйў„жөӢжҲ‘们зҡ„ж•°жҚ®гҖӮжңҖеҗҺпјҢжҲ‘们зҡ„йў„жөӢз»“жһңзҡ„зІҫеәҰеҸҜд»Ҙз”ЁвҖңеҮҶзЎ®еәҰвҖқиҜ„дј°жҢҮж ҮжқҘи®Ўз®—гҖӮи®©жҲ‘们用pythonжқҘе®ҢжҲҗиҝҷдёӘиҝҮзЁӢ!
Pythonе®һзҺ°пјҡ
model = dtc(criterion = 'entropy', max_depth = 4) model.fit(X_train, y_train) pred_model = model.predict(X_test) print(cl('Accuracy of the model is {:.0%}'.format(accuracy_score(y_test, pred_model)), attrs = ['bold']))иҫ“еҮәпјҡ
Accuracy of the model is 88%
еңЁд»Јз Ғзҡ„第дёҖжӯҘдёӯпјҢжҲ‘们е®ҡд№үдәҶдёҖдёӘеҗҚдёәвҖңmodelвҖқеҸҳйҮҸзҡ„еҸҳйҮҸпјҢжҲ‘们еңЁе…¶дёӯеӯҳеӮЁDecisionTreeClassifierжЁЎеһӢгҖӮжҺҘдёӢжқҘпјҢжҲ‘们е°ҶдҪҝз”ЁжҲ‘们зҡ„и®ӯз»ғйӣҶеҜ№жЁЎеһӢиҝӣиЎҢжӢҹеҗҲе’Ңи®ӯз»ғгҖӮд№ӢеҗҺпјҢжҲ‘们е®ҡд№үдәҶдёҖдёӘеҸҳйҮҸпјҢз§°дёәвҖңpred_modelвҖқеҸҳйҮҸпјҢе…¶дёӯжҲ‘们е°ҶжЁЎеһӢйў„жөӢзҡ„жүҖжңүеҖјеӯҳеӮЁеңЁж•°жҚ®дёҠгҖӮжңҖеҗҺпјҢжҲ‘们计算дәҶжҲ‘们зҡ„йў„жөӢеҖјдёҺе®һйҷ…еҖјзҡ„зІҫеәҰпјҢе…¶еҮҶзЎ®зҺҮдёә88%гҖӮ
жӯҘйӘӨ6пјҡеҸҜи§ҶеҢ–жЁЎеһӢ
зҺ°еңЁжҲ‘们жңүдәҶеҶізӯ–ж ‘жЁЎеһӢпјҢи®©жҲ‘们еҲ©з”Ёpythonдёӯscikit learnеҢ…жҸҗдҫӣзҡ„вҖңplot_treeвҖқеҮҪж•°жқҘеҸҜи§ҶеҢ–е®ғгҖӮжҢүз…§д»Јз Ғд»Һpythonдёӯзҡ„еҶізӯ–ж ‘жЁЎеһӢз”ҹжҲҗдёҖдёӘжјӮдә®зҡ„ж ‘еӣҫгҖӮ
Pythonе®һзҺ°пјҡ
feature_names = df.columns[:5] target_names = df['Drug'].unique().tolist() plot_tree(model, feature_names = feature_names, class_names = target_names, filled = True, rounded = True) plt.savefig('tree_visualization.png')иҫ“еҮәпјҡ
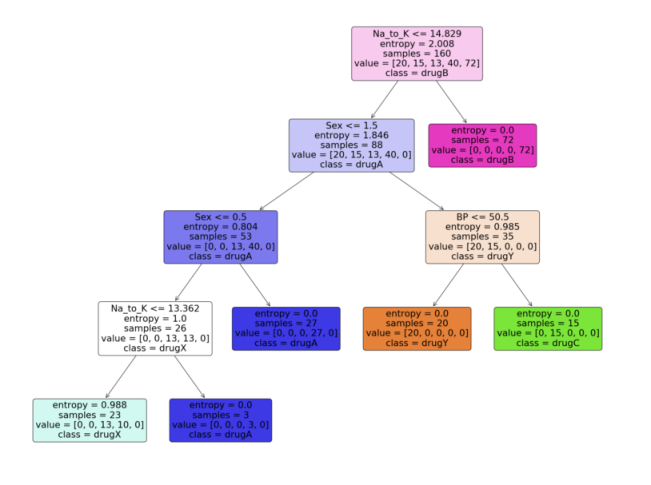
з»“и®ә
жңүеҫҲеӨҡжҠҖжңҜе’Ңе…¶д»–з®—жі•з”ЁдәҺдјҳеҢ–еҶізӯ–ж ‘е’ҢйҒҝе…ҚиҝҮжӢҹеҗҲпјҢжҜ”еҰӮеүӘжһқгҖӮиҷҪ然еҶізӯ–ж ‘йҖҡеёёжҳҜдёҚзЁіе®ҡзҡ„пјҢиҝҷж„Ҹе‘ізқҖж•°жҚ®зҡ„еҫ®е°ҸеҸҳеҢ–дјҡеҜјиҮҙжңҖдјҳж ‘з»“жһ„зҡ„е·ЁеӨ§еҸҳеҢ–пјҢдҪҶе…¶з®ҖеҚ•жҖ§дҪҝе…¶жҲҗдёәе№ҝжіӣеә”з”Ёзҡ„жңүеҠӣеҖҷйҖүгҖӮеңЁзҘһз»ҸзҪ‘з»ңжөҒиЎҢд№ӢеүҚпјҢеҶізӯ–ж ‘жҳҜжңәеҷЁеӯҰд№ дёӯжңҖе…Ҳиҝӣзҡ„з®—жі•гҖӮе…¶д»–дёҖдәӣйӣҶжҲҗжЁЎеһӢпјҢжҜ”еҰӮйҡҸжңәжЈ®жһ—жЁЎеһӢпјҢжҜ”жҷ®йҖҡеҶізӯ–ж ‘жЁЎеһӢжӣҙејәеӨ§гҖӮ
еҶізӯ–ж ‘з”ұдәҺе…¶з®ҖеҚ•жҖ§е’ҢеҸҜи§ЈйҮҠжҖ§иҖҢйқһеёёејәеӨ§гҖӮеҶізӯ–ж ‘е’ҢйҡҸжңәжЈ®жһ—еңЁз”ЁжҲ·жіЁеҶҢе»әжЁЎгҖҒдҝЎз”ЁиҜ„еҲҶгҖҒж•…йҡңйў„жөӢгҖҒеҢ»з–—иҜҠж–ӯзӯүйўҶеҹҹжңүзқҖе№ҝжіӣзҡ„еә”з”ЁгҖӮжҲ‘дёәжң¬ж–ҮжҸҗдҫӣдәҶе®Ңж•ҙзҡ„д»Јз ҒгҖӮ
е®Ңж•ҙд»Јз Ғпјҡ
import pandas as pd # ж•°жҚ®еӨ„зҗҶ import numpy as np # дҪҝз”Ёж•°з»„ import matplotlib.pyplot as plt # еҸҜи§ҶеҢ– from matplotlib import rcParams # еӣҫеӨ§е°Ҹ from termcolor import colored as cl # ж–Үжң¬иҮӘе®ҡд№ү from sklearn.tree import DecisionTreeClassifier as dtc # ж ‘з®—жі• from sklearn.model_selection import train_test_split # жӢҶеҲҶж•°жҚ® from sklearn.metrics import accuracy_score # жЁЎеһӢеҮҶзЎ®еәҰ from sklearn.tree import plot_tree # ж ‘еӣҫ rcParams['figure.figsize'] = (25, 20) df = pd.read_csv('drug.csv') df.drop('Unnamed: 0', axis = 1, inplace = True) print(cl(df.head(), attrs = ['bold'])) df.info() for i in df.Sex.values: if i == 'M': df.Sex.replace(i, 0, inplace = True) else: df.Sex.replace(i, 1, inplace = True) for i in df.BP.values: if i == 'LOW': df.BP.replace(i, 0, inplace = True) elif i == 'NORMAL': df.BP.replace(i, 1, inplace = True) elif i == 'HIGH': df.BP.replace(i, 2, inplace = True) for i in df.Cholesterol.values: if i == 'LOW': df.Cholesterol.replace(i, 0, inplace = True) else: df.Cholesterol.replace(i, 1, inplace = True) print(cl(df, attrs = ['bold'])) X_var = df[['Sex', 'BP', 'Age', 'Cholesterol', 'Na_to_K']].values # иҮӘеҸҳйҮҸ y_var = df['Drug'].values # еӣ еҸҳйҮҸ print(cl('X variable samples : {}'.format(X_var[:5]), attrs = ['bold'])) print(cl('Y variable samples : {}'.format(y_var[:5]), attrs = ['bold'])) X_train, X_test, y_train, y_test = train_test_split(X_var, y_var, test_size = 0.2, random_state = 0) print(cl('X_train shape : {}'.format(X_train.shape), attrs = ['bold'], color = 'red')) print(cl('X_test shape : {}'.format(X_test.shape), attrs = ['bold'], color = 'red')) print(cl('y_train shape : {}'.format(y_train.shape), attrs = ['bold'], color = 'green')) print(cl('y_test shape : {}'.format(y_test.shape), attrs = ['bold'], color = 'green')) model = dtc(criterion = 'entropy', max_depth = 4) model.fit(X_train, y_train) pred_model = model.predict(X_test) print(cl('Accuracy of the model is {:.0%}'.format(accuracy_score(y_test, pred_model)), attrs = ['bold'])) feature_names = df.columns[:5] target_names = df['Drug'].unique().tolist() plot_tree(model, feature_names = feature_names, class_names = target_names, filled = True, rounded = True) plt.savefig('tree_visualization.png')д»ҘдёҠе°ұжҳҜPythonдёӯжҖҺд№Ҳжһ„е»әдёҖдёӘеҶізӯ–ж ‘пјҢе°Ҹзј–зӣёдҝЎжңүйғЁеҲҶзҹҘиҜҶзӮ№еҸҜиғҪжҳҜжҲ‘们ж—Ҙеёёе·ҘдҪңдјҡи§ҒеҲ°жҲ–з”ЁеҲ°зҡ„гҖӮеёҢжңӣдҪ иғҪйҖҡиҝҮиҝҷзҜҮж–Үз« еӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮжӣҙеӨҡиҜҰжғ…敬иҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





