前几天给大家介绍了unicode编码和utf-8编码的理论知识,以及Python2中字符串编码问题,没来得及上车的小伙伴们可以戳这篇文章:浅谈unicode编码和utf-8编码的关系和一篇文章助你理解Python2中字符串编码问题。下面在Python3环境中进行代码演示,分别Windows和Linux操作系统下进行演示,以加深对字符串编码的理解。

在Python2的Python文件的文件头往往会声明字符的编码格式,通过会使用代码“#-*- coding -*-”作为编码声明,如下图所示。
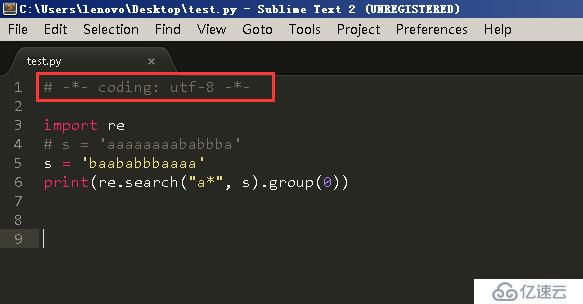
因为考虑到Python文件中可能会穿插中文,不然的话Python通过解释器来读取文件的时候,文件中的中文就有可能识别不了。而在Python3中,我们就不必像Python2的文件那样进行声明编码格式了,因为在Python3中,默认将所有的字符都视为unicode格式了。下面在Python3环境下进行代码演示。
1、首先在Windows操作系统下的Python3环境中进行演示,如下图所示。
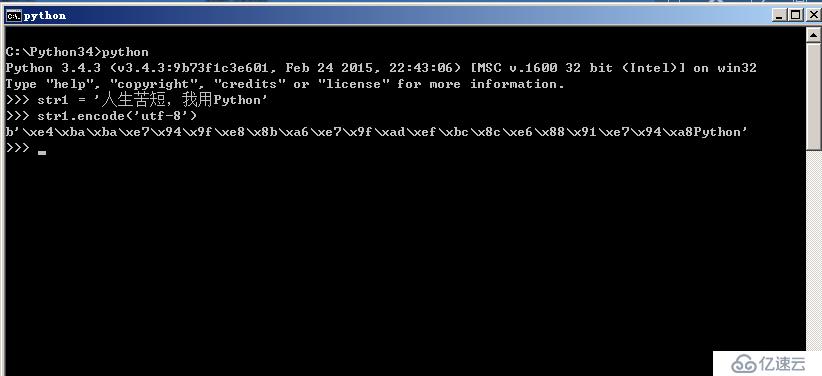
可以看到str1就是一个中文的字符串,字符串前面也没有加u以表示其为unicode编码,其实也没有必要加那个字符,因为在Python3中将所有的字符都内置成unicode字符了,这就是Python2和Python3最大的区别。所有在这里可以直接调用encode()函数对字符串进行编码,而且也不会报错。
2、接下来在Linux操作系统下的Python3环境中进行演示,如下图所示。
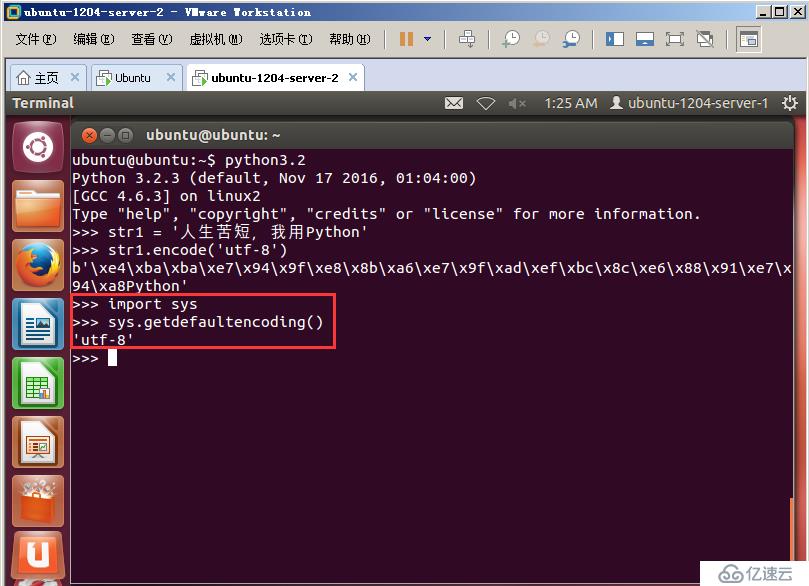
这个过程和Windows下是一样的,这里就不再赘述了。有个地方需要注意的是在Linux操作系统下,Python3的默认环境编码变为了utf-8编码,而不是Python2中的ASCII编码。
总的来说,Python3解决了一个字符编码的重要问题,所以在字符串编码的报错方面相对Python2来说要少的多,帮助我们省下了很多事情。小伙伴们,关于在Python2和Python3中字符串的编码问题这个知识点十分重要,希望大家都可以get到噢~~
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





