这篇文章主要讲解了“不常用但很有用的Python库有哪些”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“不常用但很有用的Python库有哪些”吧!
提到数据科学的python包,大家想到的估计是numpy,pandas,scikit-learn之类的,这里给大家介绍一些不常用,但是非常有用的python包,就像是痒痒挠,虽然大部分时间用不上,但是真要用起来,还是挺爽的。Python是个了不起的语言。事实上,这是世界上发展最快的语言之一(感觉没有之一,就是最快的)。在数据科学领域和开发领域,一次又一次的为我们提供便利。整个Python的生态和库使之成为所有用户都适用(初学者和高级用户)。Python之所以这么成功,原因之一就在于它的库,让Python变得灵活快速。
这篇文章中,我们会看一些不太常用的数据科学的库,除了pandas,scikit-learn,matplotlib等。尽管说到数据科学,我们想到的就是pandas和scikit-learn,了解一下其他的python的库也没什么坏处。下面就是另外一些数据科学中可能会用到的Python库。
从网络获取数据是Python科学家非常重要的任务。Wget是一个免费的工具,可以从Web上非交互式的下载文件,支持HTTP, HTTPS, 和 FTP协议,同样支持HTTP代理。由于是非交互式的,所以可以后台运行,用户没有登录也可以。所以下次你需要从网上下载图片的时候,可以试试wget。
安装:
$ pip install wget例子:
import wget url = 'http://www.futurecrew.com/skaven/song_files/mp3/razorback.mp3' filename = wget.download(url) 100% [................................................] 3841532 / 3841532 filename 'razorback.mp3'这个是干啥的呢,你在处理日期时间的时候搞得头大的时候,Pendulum就很适合你,这包是用来简化日期时间的操作的,具体使用可以看 这里 。
安装:
$ pip install pendulum例子:
import pendulum dt_toronto = pendulum.datetime(2012, 1, 1, tz='America/Toronto') dt_vancouver = pendulum.datetime(2012, 1, 1, tz='America/Vancouver') print(dt_vancouver.diff(dt_toronto).in_hours()) 3大多数的分类问题中,当所有的类别中的样本的数量大致相同时,效果是最好的,也就是样本均衡。但是在实际情况中,往往都是非均衡的数据,这往往会影响训练的过程以及后面的预测。幸好,这个库可以帮我们解决这个问题。这个和scikit-learn兼容,是scikit-learn-contrib的一部分。下次可以试试。
安装:
pip install -U imbalanced-learn # or conda install -c conda-forge imbalanced-learn例子:
请参考文档。
在清洗NLP相关的数据的时候,往往需要替换一些关键词或者提取一些关键词。通常,可以用正则表达式来干这个活,不过正则条件的数量上千的时候,就会很头大。FlashText是基于FlashText算法的一个模块,提供了这种情况下的一个替代工具,FlashText最好的地方在于运行时间是和搜索的条件的数量不相关的。更多的信息可以看这里。
安装:
$ pip install flashtext例子:
提取关键词
from flashtext import KeywordProcessor keyword_processor = KeywordProcessor() # keyword_processor.add_keyword(<unclean name>, <standardised name>) keyword_processor.add_keyword('Big Apple', 'New York') keyword_processor.add_keyword('Bay Area') keywords_found = keyword_processor.extract_keywords('I love Big Apple and Bay Area.') keywords_found ['New York', 'Bay Area']替换关键词
keyword_processor.add_keyword('New Delhi', 'NCR region') new_sentence = keyword_processor.replace_keywords('I love Big Apple and new delhi.') new_sentence 'I love New York and NCR region.'名字听起来怪怪的,不过在字符匹配的时候,用起来还是爽爽的。可以轻松的实现字符比例,token比例等。还可以在不同的数据集中进行匹配。
安装:
$ pip install fuzzywuzzy例子:
from fuzzywuzzy import fuzz from fuzzywuzzy import process # Simple Ratio fuzz.ratio("this is a test", "this is a test!") 97 # Partial Ratio fuzz.partial_ratio("this is a test", "this is a test!") 100时间序列的处理是机器学习领域经常遇到的问题。PyFlux就是专门用来处理时间序列问题的开源Python库。这个库里有一系列的时间序列模型如ARIMA, GARCH 和VAR 等。简单来说,PyFlux提供了时间序列到概率的建模,值的一试。
安装
pip install pyflux
例子
参考这里 。
交流结果是数据科学的非常重要的方面。结果可视化是个非常重要的优势。IPyvolume是个3D可视化库,不过这还是在pre-1.0的阶段,可以这样类别一下, IPyvolume是对3维数据的可视化,matplotlib是对二维数据的可视化。具体可以看 这里。
安装
Using pip $ pip install ipyvolume Conda/Anaconda $ conda install -c conda-forge ipyvolume例子
标记
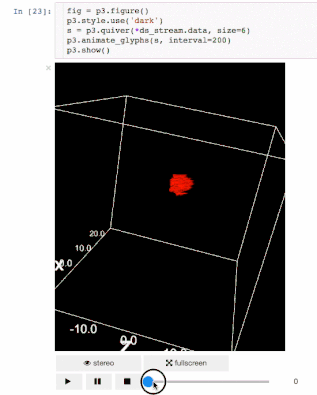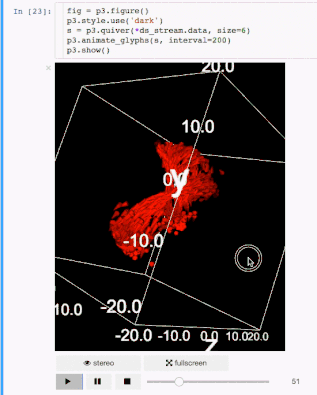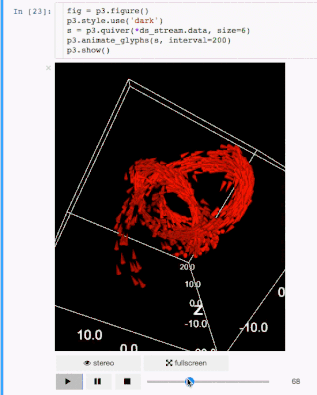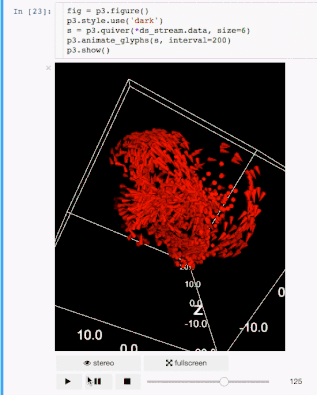
渲染
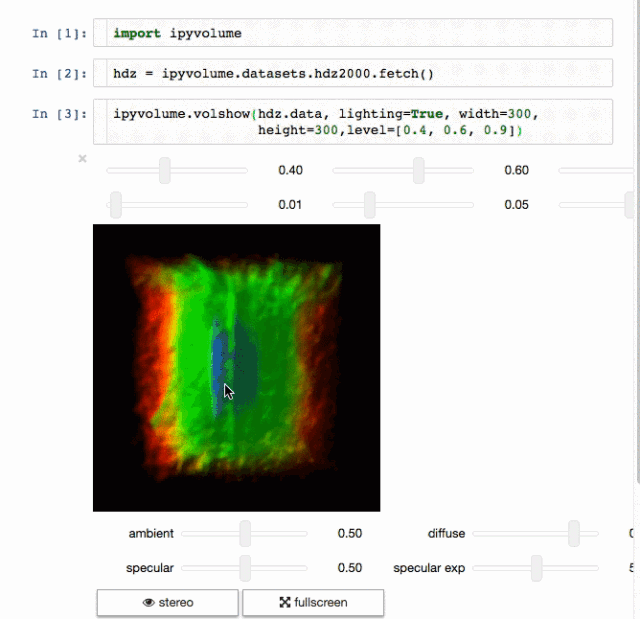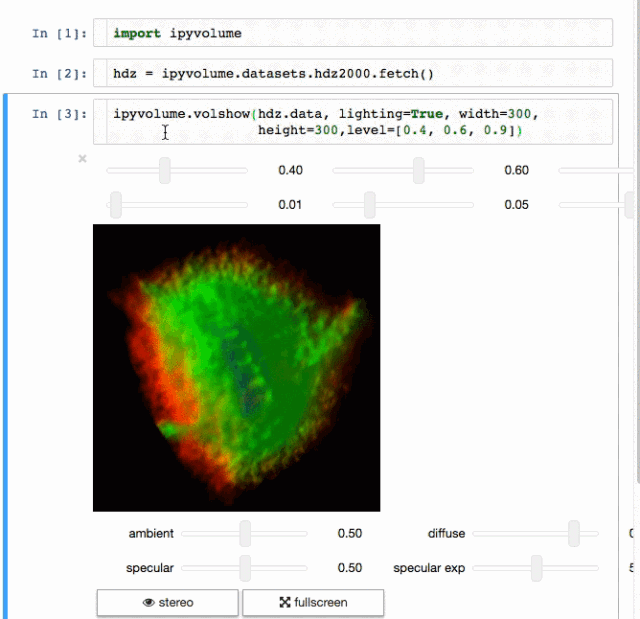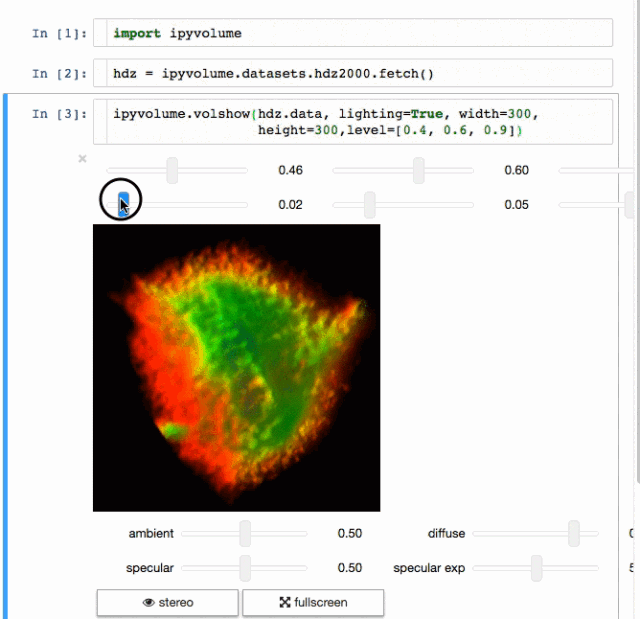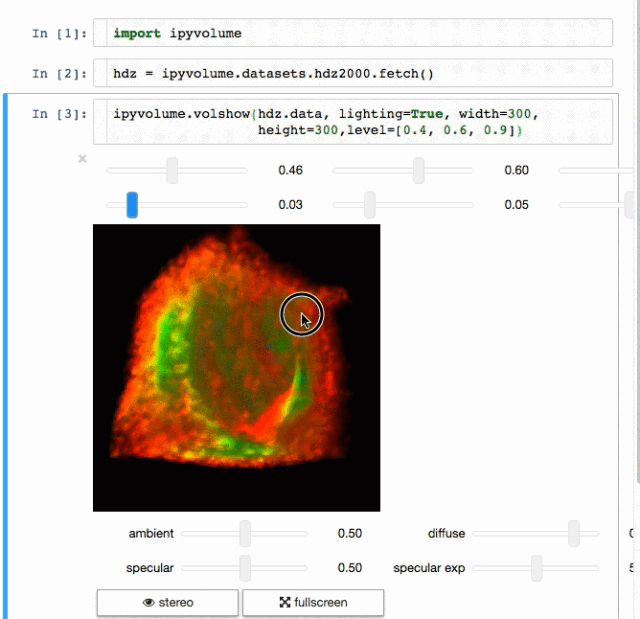
这是个创建web应用的用户生产的Python框架。基于Flask写的,可以用来构建数据可视化的app,这些app可以在网络浏览器上渲染。用户手册可见 这里.
安装
pip install dash==0.29.0 # The core dash backend pip install dash-html-components==0.13.2 # HTML components pip install dash-core-components==0.36.0 # Supercharged components pip install dash-table==3.1.3 # Interactive DataTable component (new!)例子
Gym来自OpenAI,用来做强化学习。兼容所有的数值计算库,如TensorFlow,Theano等。这个库提供了一个问题测试的环境,你可以用这个环境来实验你的强化学习算法。这些环境共享界面,使你可以写通用的算法。
安装
pip install gym
例子
感谢各位的阅读,以上就是“不常用但很有用的Python库有哪些”的内容了,经过本文的学习后,相信大家对不常用但很有用的Python库有哪些这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://www.toutiao.com/i6748767090749997581/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



