这期内容当中小编将会给大家带来有关Python中怎么爬取金融市场数据,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
1、正则表达式
具体的详细介绍可自行去网上补知识,这里只介绍一些规则和常用的用法。
# 正则表达式 规则: 单字符: . : 除换行以外所有字符 [] : 匹配集合中任意一个字符 \d : 数字 \D : 非数字 \w : 数字、字母、下划线、中文 \W : 非数字、字母、下划线、中文 \s : 空格 \S : 非空格 数量修饰: * : 任意多次 + : 至少1次 ?: 非贪婪方式,可有可无 {m} : 固定m次 {m+} : 至少m次 {m,n} : m到n次 起始: ^ : 以啥啥开头 $ : 以啥啥结尾 常用组合和函数: .* : 贪婪方式任意字符任意次数 .*? : 非贪婪方式任意字符任意次数 r = re.compile(r'正则表达式',re.S) : 最常用:将规则传递给某个参数以便反复使用 re.match\re.search\(字符串) re.findall(字符串) re.sub(正则表达式,替换内容,字符串)2、bs4
同样,详细知识自行补,这里只介绍常用的用法:select结合选择器的用法。
# bs4用法 首先加载里面的BeautifulSoup: from bs4 import BeautifulSoup soup = BeautifulSoup('网页响应回来的东西')主要有以下几种提取规则:
1、获取标签 soup.a 获取a标签(***个) 2、获取属性 soup.a.attrs 获取a标签下所有的属性和值,返回的是字典 soup.a['name'] 获取a标签下的name属性 3、获取内容 soup.a.string() soup.a.text() 建议使用这个 4、find用法 soup.find('a') 找到***个a soup.find('a',title='') 附加条件的查找 5、find_all用法 soup.find_all('a') 找到所有a soup.find_all(['a','b']) 找到所有a和b soup.find_all('a',limit=5) 找到前5个a 6、select用法——重点 结合选择器使用,常用的选择器如下: 标签选择器:如div表示为div 类选择器:.表示,如class = 'you'表示为.you id选择器:#表示,如id = 'me'表示为#me 组合选择器:如div,.you,#me 层级选择器:如div .you #me表示选取div标签下的you类下的id为me的内容 再如div > .you > #me,> 则表示只能是下面一级三、开始实战——爬取某信托网的信托在售数据
1、爬取前的准备工作——梳理好代码的逻辑
正如前面所说,写代码之前,首先要清楚你想要干什么,如果是你,你是什么样的动作来达到你的这个目的或意图。
***,你的目的或意图是什么,对于本例而言,我需要获取任意某页至某页信托在售产品的下面数据:产品名称、发行机构、发行时间、***收益、产品期限、投资行业、发行地、收益分配方式、发行规模、***收益、***收益和利率等级划分情况这12个数据。
第二,如果是人,需要哪些动作来达到这个目的。我们来看下网页。动作就清晰了:
输入网址/搜索关键字 > 进入网站 > 点击红色框框里的信托产品和在售 > 录入下面绿色框框里的相关信息 > 发现信息不全,再点击这个产品,在详情页(再下一张图)继续录入。
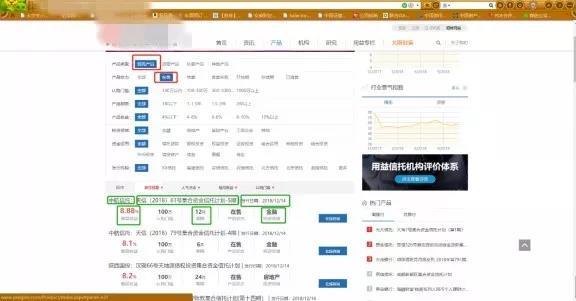
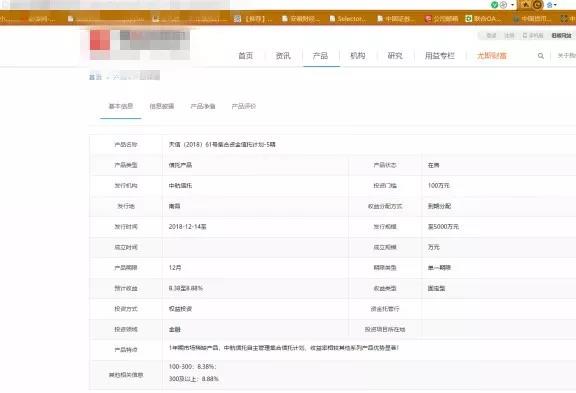
2、开始爬取
既然动作清晰了,那就可以让计算机来模拟人的这个动作进行爬取了。
然后就是写代码的逻辑了。我们用做数学题常用的倒推法来梳理这个过程。
要想获取数据 < 你得解析网页给你的响应 < 你得有个响应 < 你得发送请求 < 你得有个请求request < 你得有个url。
然后我们再正过来解题:获取url > 构建request > 发送请求 > 获取响应 > 解析响应 > 获取所需数据 > 保存数据。
所以按照这个步骤,我们可以先做出一个大框架,然后在框架的基础上补充血肉。大框架,就是定义个主函数。
值得注意的是,本例中,每个产品的信息获取,我们都有二次点击的动作,即***页数据不全,我们再点击进入详情页进行剩余数据的获取,因此,本例是有两层的数据获取过程的。***层使用正则表达式,第二层使用bs4。
① 定义主函数
如下是这个主函数,前面的写入相关数据你可以先不管,这都是在***步的获取url时,后补过来的。
回到前面的目的:提取任意某页至任意某页的数据,所以写个循环是必须的,然后在循环下方,两层网页的数据获取框架就出来了。(由于第二层网页的url是根据***层网页的某个数据拼接出来的,而***层网页是一下子提取整个页面所有产品的信息,所以第二层网页的提取也设置了个循环,对***层网页的所有产品,一个一个点进去进行提取)
# 定义一个主函数 def main(): # 写入相关数据 url_1 = 'http://www.某信托网.com/Action/ProductAJAX.ashx?' url_2 = 'http://www.某信托网/Product/Detail.aspx?' size = input('请输入每页显示数量:') start_page = int(input('请输入起始页码:')) end_page = int(input('请输入结束页码')) type = input('请输入产品类型(1代表信托,2代表资管):') items = [] # 定义一个空列表用来存储数据 # 写循环爬取每一页 for page in range(start_page, end_page + 1): # ***层网页的爬取流程 print('第{}页开始爬取'.format(page)) # 1、拼接url——可定义一个分函数1:joint url_new = joint(url_1 ,size=size ,page=page ,type=type) # 2、发起请求,获取响应——可定义一个分函数2:que_res response = que_res(url_new) # 3、解析内容,获取所需数据——可定义一个分函数3:parse_content_1 contents = parse_content_1(response) # 4、休眠2秒 time.sleep(2) # 第二层网页的爬取流程 for content in contents: print(' 第{}页{}开始下载'.format(page ,content[0])) # 1、拼接url id = content[0] url_2_new = joint(url_2 ,id=id) # joint为前面定义的第1个函数 # 2、发起请求,获取响应 response_2 = que_res(url_2_new) # que_res为前面定义的第2个函数 # 3、解析内容,获取所需数据——可定义一个分函数4:parse_content_2,直接返回字典格式的数据 item = parse_content_2(response_2 ,content) # 存储数据 items.append(item) print(' 第{}页{}结束下载'.format(page ,content[0])) # 休眠5秒 time.sleep(5) print('第{}页结束爬取'.format(page)) # 保存数据为dataframe格式CSV文件 df = pd.DataFrame(items) df.to_csv('data.csv' ,index=False ,sep=',' ,encoding='utf-8-sig') print('*'*30) print('全部爬取结束') if __name__ == '__main__': main()② 获取url —— ***层和第二层通用
由于我们需要访问两层的数据,所以希望定义一个函数,能对两层的URL都可以进行拼接。
如下图为***层页面的内容和源码,由第二个红框中的内容(X-Requested-With:XMLHttpRequest),可知这是一个AJAX get请求,且携带者第三个红框中的数据,而第三个红框中的数据,又恰好是***个红框中的url的一部分,即为:
http://www.某信托网.com/Action/ProductAJAX.ashx?加上第三个红框中的数据。
第三个框框中包括几个可变的数据:pageSize(表示一页显示多少产品);pageIndex(表示第几页);conditionStr(定义产品类型,1表示信托,2表示资管),其余的数据都是固定的(这其中有个_:1544925791285这种下划线带一串数字的东西,像是个随机数,去掉也没影响,我就给去掉了)。
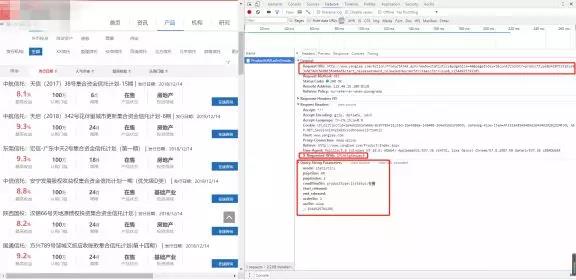
下图为第二层页面的内容和源码,可见只是一个简单的get请求,且网址很简单,就是一个http://www.某信托网.com/Product/Detail.aspx?加上一个id,而这个id又来自哪里呢,答案就在***层网页的响应数据中(见再下面一幅图的红色框)。
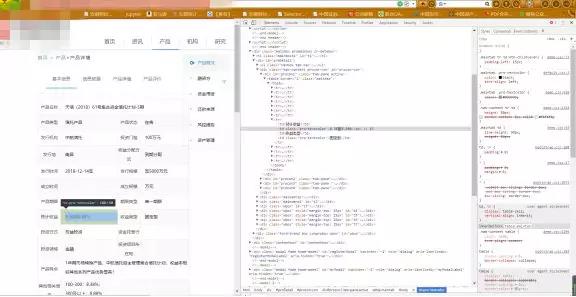
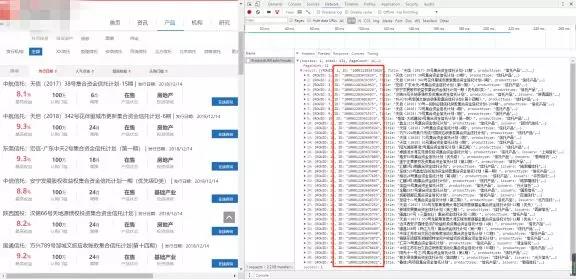
通过上面的分析,***层网页的请求url由一个固定的部分加上一些数据,第二层网页的url依赖于***层的数据,我们先在主函数中将url_1、url_2和一些可变的数据写入(见上面的主函数),然后定义一个函数用来拼接两层的url即可,因为***层网页url的固定部分长度为47,第二层的为43,这里使用一个长度条件来判断是拼接***层还是拼接第二层。
# 定义第1个分函数joint,用来拼接url def joint(url,size=None,page=None,type=None,id=None): if len(url) > 45: condition = 'producttype:' + type + '|status:在售' data = { 'mode': 'statistics', 'pageSize': size, 'pageIndex': str(page), 'conditionStr': condition, 'start_released': '', 'end_released': '', 'orderStr': '1', 'ascStr': 'ulup' } joint_str = urllib.parse.urlencode(data) url_new = url + joint_str else: data = { 'id':id } joint_str = urllib.parse.urlencode(data) url_new = url + joint_str return url_new③ 构建request + 获取response一条龙 —— ***层和第二层通用
获取url后,接下来就是构建request用来发送请求获取响应了,此处定义一个函数实现一条龙服务。
这里为了提防反爬,user_agent在多个里随机选,并使用了代理池(虽然不多),并且我电脑端也进行了局域网ip代理。
# 定义第2个函数que_res,用来构建request发送请求,并返回响应response def que_res(url): # 构建request的***步——构建头部:headers USER_AGENTS = [ "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)", "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)", ] user_agent = random.choice(USER_AGENTS) headers = { 'Accept-Language': 'zh-CN,zh;q=0.8', 'Connection': 'keep-alive', 'Host': 'www.某信托网.com', 'Referer': 'http://www.某信托网.com/Product/Index.aspx', 'User-Agent': user_agent, 'X-Requested-With': 'XMLHttpRequest' } # 构建request的第二步——构建request request = urllib.request.Request(url=url, headers=headers) # 发起请求的***步——构建代理池 proxy_list = [ {'http':'125.40.29.100:8118'}, {'http':'14.118.135.10:808'} ] proxy = random.choice(proxy_list) # 发起请求的第二步——创建handler和opener handler = urllib.request.ProxyHandler(proxy) opener = urllib.request.build_opener(handler) # 发起请求的第三步——发起请求,获取响应内容并解码 response = opener.open(request).read().decode() # 返回值 return response④ 解析***层网页的内容
获取响应之后就是解析并提取数据了,***层使用正则表达式的方法来进行。
获取的response如下如:

因此可写出如下正则,从左到右分配匹配出ID、产品名称、发行机构、发行时间、产品期限、投资行业、首页收益。
# 定义第3个函数parse_content_1,用来解析并匹配***层网页内容,此处使用正则表达式方法 def parse_content_1(response): # 写正则进行所需数据的匹配 re_1 = re.compile( r'{"ROWID".*?"ID":"(.*?)","Title":"(.*?)","producttype".*?"issuers":"(.*?)","released":"(.*?) 0:00:00","PeriodTo":(.*?),"StartPrice".*?"moneyinto":"(.*?)","EstimatedRatio1":(.*?),"status":.*?"}') contents = re_1.findall(response) return contents⑤ 解析第二层网页的内容并输出数据
第二层使用bs4中的select+选择器的方法来进行。除了***层所提取的数据外,还需要发行地、收益分配方式、发行规模、***收益、***收益和利率等级分布情况。
网页如下,可见,我们所需要的信息隐藏在一个又一个tr标签里,而这个tr标签处于id=“procon1”下的一个table标签里(此处有个坑,就是从网页来看,table下还有个tbody标签,而实际得到的响应里并没有)。
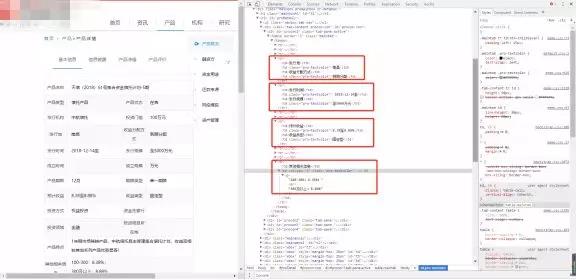
由于我们不是所有的信息都要,所以我们可以一个一个的提取,最终输出个数据。代码如下(这中间用到了前面提到的选择器知识和一些字符串处理方法):
# 定义第4个函数parse_content_2,用来解析并匹配第二层网页内容,并输出数据,此处使用BeautifulSoup方法 def parse_content_2(response,content): # 使用bs4进行爬取第二层信息 soup = BeautifulSoup(response) # 爬取发行地和收益分配方式,该信息位于id为procon1下的table下的第4个tr里 tr_3 = soup.select('#procon1 > table > tr')[3] address = tr_3.select('.pro-textcolor')[0].text r_style = tr_3.select('.pro-textcolor')[1].text # 爬取发行规模,该信息位于id为procon1下的table下的第5个tr里 tr_4 = soup.select('#procon1 > table > tr')[4] guimo = tr_4.select('.pro-textcolor')[1].text re_2 = re.compile(r'.*?(\d+).*?', re.S) scale = re_2.findall(guimo)[0] # 爬取收益率,该信息位于id为procon1下的table下的第8个tr里 tr_7 = soup.select('#procon1 > table > tr')[7] rate = tr_7.select('.pro-textcolor')[0].text[:(-1)] r = rate.split('至') r_min = r[0] r_max = r[1] # 提取利率等级 tr_11 = soup.select('#procon1 > table > tr')[11] r_grade = tr_11.select('p')[0].text # 保存数据到一个字典中 item = { '产品名称':content[1], '发行机构':content[2], '发行时间':content[3], '产品期限':content[4], '投资行业':content[5], '首页收益':content[6], '发行地': address, '收益分配方式': r_style, '发行规模': scale, '***收益': r_min, '***收益': r_max, '利率等级': r_grade } # 返回数据 return item⑥ 保存数据到本地(以dataframe格式保存到本地CSV格式)
# 保存数据为dataframe格式CSV文件 df = pd.DataFrame(items) df.to_csv('data.csv',index=False,sep=',',encoding='utf-8-sig') 好了,现在就大功告成了,***不要只让自己爽,也要让对方的服务器别太难过,在一些地方休眠几秒,完整代码如下。 import urllib.request import urllib.parse import re import random from bs4 import BeautifulSoup import pandas as pd import time # 定义第1个分函数joint,用来拼接url def joint(url,size=None,page=None,type=None,id=None): if len(url) > 45: condition = 'producttype:' + type + '|status:在售' data = { 'mode': 'statistics', 'pageSize': size, 'pageIndex': str(page), 'conditionStr': condition, 'start_released': '', 'end_released': '', 'orderStr': '1', 'ascStr': 'ulup' } joint_str = urllib.parse.urlencode(data) url_new = url + joint_str else: data = { 'id':id } joint_str = urllib.parse.urlencode(data) url_new = url + joint_str return url_new # 定义第2个函数que_res,用来构建request发送请求,并返回响应response def que_res(url): # 构建request的***步——构建头部:headers USER_AGENTS = [ "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)", "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)", ] user_agent = random.choice(USER_AGENTS) headers = { 'Accept-Language': 'zh-CN,zh;q=0.8', 'Connection': 'keep-alive', 'Host': 'www.某信托网.com', 'Referer': 'http://www.某信托网.com/Product/Index.aspx', 'User-Agent': user_agent, 'X-Requested-With': 'XMLHttpRequest' } # 构建request的第二步——构建request request = urllib.request.Request(url=url, headers=headers) # 发起请求的***步——构建代理池 proxy_list = [ {'http':'125.40.29.100:8118'}, {'http':'14.118.135.10:808'} ] proxy = random.choice(proxy_list) # 发起请求的第二步——创建handler和opener handler = urllib.request.ProxyHandler(proxy) opener = urllib.request.build_opener(handler) # 发起请求的第三步——发起请求,获取响应内容并解码 response = opener.open(request).read().decode() # 返回值 return response # 定义第3个函数parse_content_1,用来解析并匹配***层网页内容,此处使用正则表达式方法 def parse_content_1(response): # 写正则进行所需数据的匹配 re_1 = re.compile( r'{"ROWID".*?"ID":"(.*?)","Title":"(.*?)","producttype".*?"issuers":"(.*?)","released":"(.*?) 0:00:00","PeriodTo":(.*?),"StartPrice".*?"moneyinto":"(.*?)","EstimatedRatio1":(.*?),"status":.*?"}') contents = re_1.findall(response) return contents # 定义第4个函数parse_content_2,用来解析并匹配第二层网页内容,并输出数据,此处使用BeautifulSoup方法 def parse_content_2(response,content): # 使用bs4进行爬取第二层信息 soup = BeautifulSoup(response) # 爬取发行地和收益分配方式,该信息位于id为procon1下的table下的第4个tr里 tr_3 = soup.select('#procon1 > table > tr')[3] #select到第四个目标tr address = tr_3.select('.pro-textcolor')[0].text #select到该tr下的class为pro-textcolor的***个内容(发行地) r_style = tr_3.select('.pro-textcolor')[1].text #select到该tr下的class为pro-textcolor的第二个内容(收益分配方式) # 爬取发行规模,该信息位于id为procon1下的table下的第5个tr里 tr_4 = soup.select('#procon1 > table > tr')[4] #select到第五个目标tr guimo = tr_4.select('.pro-textcolor')[1].text #select到该tr下的class为pro-textcolor的第二个内容(发行规模:至***万) re_2 = re.compile(r'.*?(\d+).*?', re.S) #设立一个正则表达式,将纯数字提取出来 scale = re_2.findall(guimo)[0] #提取出纯数字的发行规模 # 爬取收益率,该信息位于id为procon1下的table下的第8个tr里 tr_7 = soup.select('#procon1 > table > tr')[7] #select到第八个目标tr rate = tr_7.select('.pro-textcolor')[0].text[:(-1)] #select到该tr下的class为pro-textcolor的***个内容(且通过下标[-1]将末尾的 % 去除) r = rate.split('至') #此处用来提取***收益和***收益 r_min = r[0] r_max = r[1] # 提取利率等级 tr_11 = soup.select('#procon1 > table > tr')[11] #select到第十二个目标tr r_grade = tr_11.select('p')[0].text #select到该tr下的p下的***个内容(即利率等级) # 保存数据到一个字典中 item = { '产品名称':content[1], '发行机构':content[2], '发行时间':content[3], '产品期限':content[4], '投资行业':content[5], '首页收益':content[6], '发行地': address, '收益分配方式': r_style, '发行规模': scale, '***收益': r_min, '***收益': r_max, '利率等级': r_grade } # 返回数据 return item # 定义一个主函数 def main(): # 写入相关数据 url_1 = 'http://www.某信托网.com/Action/ProductAJAX.ashx?' url_2 = 'http://www.某信托网.com/Product/Detail.aspx?' size = input('请输入每页显示数量:') start_page = int(input('请输入起始页码:')) end_page = int(input('请输入结束页码')) type = input('请输入产品类型(1代表信托,2代表资管):') items = [] # 定义一个空列表用来存储数据 # 写循环爬取每一页 for page in range(start_page, end_page + 1): # ***层网页的爬取流程 print('第{}页开始爬取'.format(page)) # 1、拼接url——可定义一个分函数1:joint url_new = joint(url_1,size=size,page=page,type=type) # 2、发起请求,获取响应——可定义一个分函数2:que_res response = que_res(url_new) # 3、解析内容,获取所需数据——可定义一个分函数3:parse_content_1 contents = parse_content_1(response) # 4、休眠2秒 time.sleep(2) # 第二层网页的爬取流程 for content in contents: print(' 第{}页{}开始下载'.format(page,content[0])) # 1、拼接url id = content[0] url_2_new = joint(url_2,id=id) # joint为前面定义的第1个函数 # 2、发起请求,获取响应 response_2 = que_res(url_2_new) # que_res为前面定义的第2个函数 # 3、解析内容,获取所需数据——可定义一个分函数4:parse_content_2,直接返回字典格式的数据 item = parse_content_2(response_2,content) # 存储数据 items.append(item) print(' 第{}页{}结束下载'.format(page,content[0])) # 休眠5秒 time.sleep(5) print('第{}页结束爬取'.format(page)) # 保存数据为dataframe格式CSV文件 df = pd.DataFrame(items) df.to_csv('data.csv',index=False,sep=',',encoding='utf-8-sig') print('*'*30) print('全部爬取结束') if __name__ == '__main__': main()3、爬取结果
运行代码,这里以每页显示4个产品,爬取前3页的信托在售为例,运行结果如下:
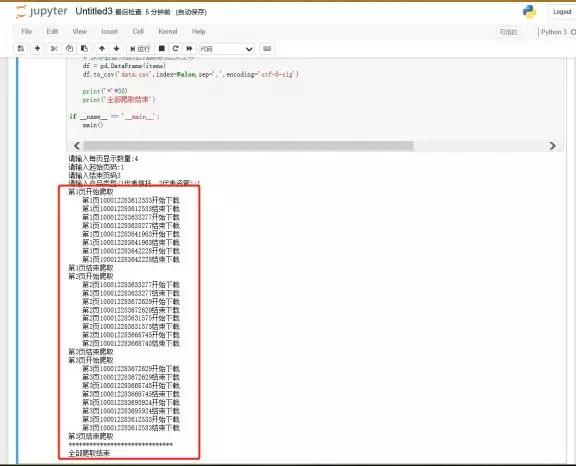
然后打开存到本地的CSV文件如下:结果是美好的。

上述就是小编为大家分享的Python中怎么爬取金融市场数据了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





