这期内容当中小编将会给大家带来有关Python中怎么爬取电影天堂数据,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
首先打开Pycharm点击File再点开setting。
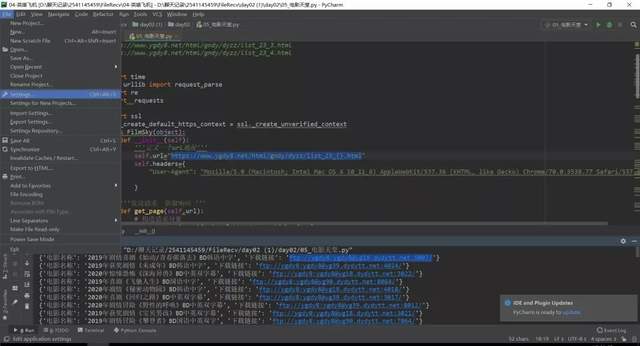
打开后会出现这个界面点击你的项目名字(project:(你的项目名字))project interpreter点击加号下载我们需要的库本项目需要(requests,requests,time,re模块),如下图所示。
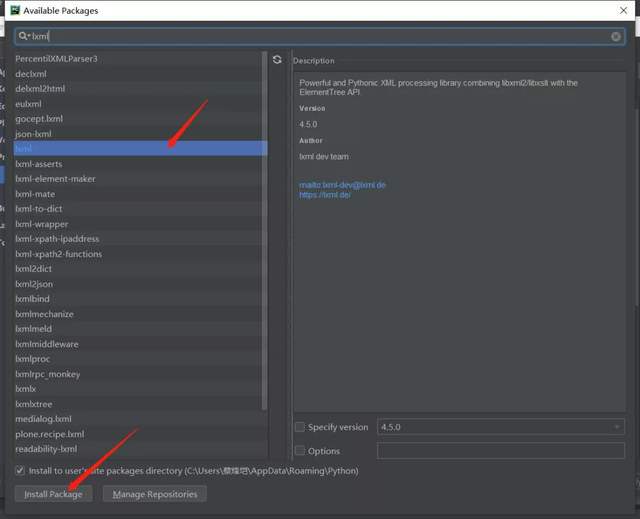
我们需要(requests,requests,time,re模块 ),如下图所示。
这个time是用于防止反爬,设置的时间延时。
首先我们来分析一下这个网址下一页得到特点。

在主方法main函数里边用for循环实现遍历网址。
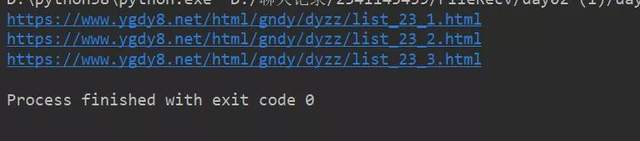
说明你已经成功一半了加油!!
现在我们需要对这些网址发生请求,为了更直观的看出来,我们用一个类写。
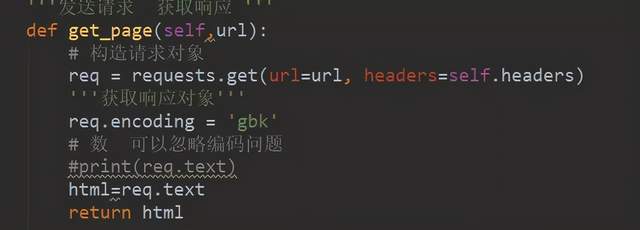
我们用requests发生请求 这个网站的编码是gbk (怎么看网站的编码?)。
打开一个网站右键检查在header的标签,以这个网站为例,可以看到charset=“gb312”。
这个gb2312就是编码 我们常见的编码方式有2种(utf_8, gbk)。
我们可以验证一下是不是真的请求到了。使用Print(html)看到这个结果(一个完整的html网页)说明请求成功。
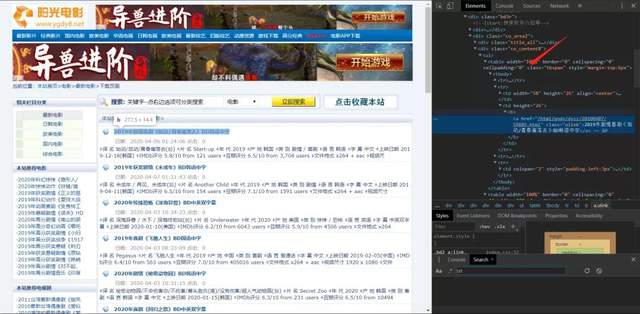
所以我们可以先找到table,一层一层的去找,可以参考一下下面的图。
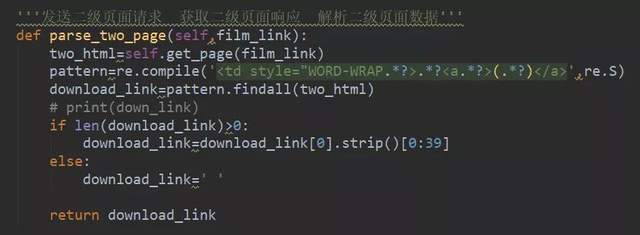
点开第二级页面如图右键点击下载链接,如下图所示:
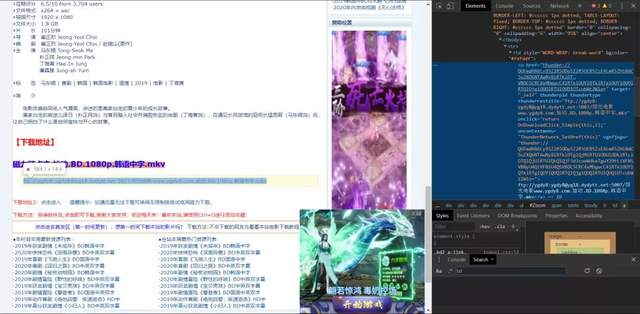
我们用正则表达式解析 得到我们下载链接地址,如下图所示:

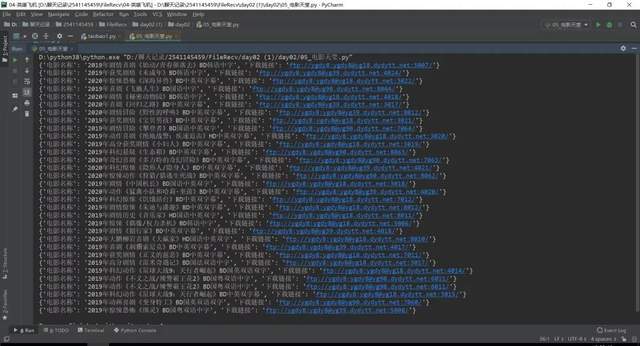
得到结果,如下图所示:
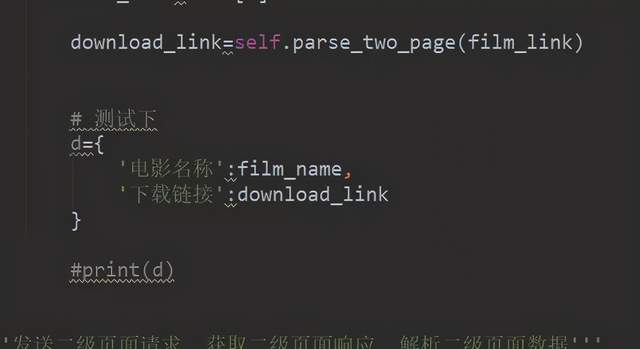
最后我们优化一下请求的代码有点重复 我们优化一下;
用一个值去保存说明请求头的内容以后请求我们只有调用这个方法进行请求就好,如下图所示:
上述就是小编为大家分享的Python中怎么爬取电影天堂数据了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4848094/blog/4745240



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



