本篇内容介绍了“使用Python小细节有哪些”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
01、只要一行代码的列表生成器
假如每次你想要生成个列表,都要写个循环,是不是很烦呢?好在 Python 已经有一个内建方法,只要一行代码就能搞定这个问题。如果你不熟悉这个语法,可能理解起来会有点难度,不过一旦你习惯这个技术之后,你一定会爱不释手的!
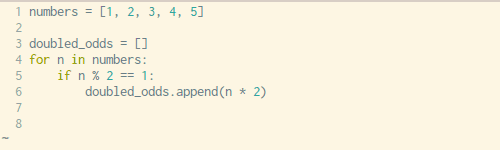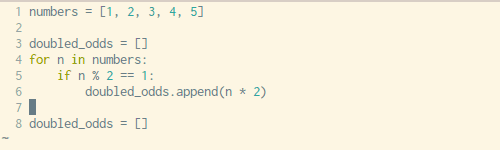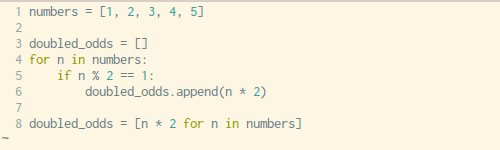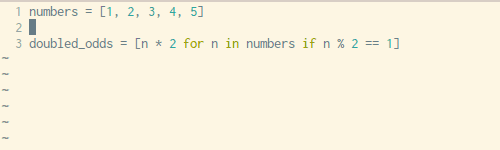
动图:如何将一个循环改成列表生成式(来源:Trey Hunner )
上面这个动图就是一个很好的例子,原来的代码就是采用 for 循环生成列表的方法,而图上一步一步将它改造成了一个只有一行代码的列表生成式,再也不用循环啦。是不是很简洁?
下面是另外一个对比范例:
使用循环:
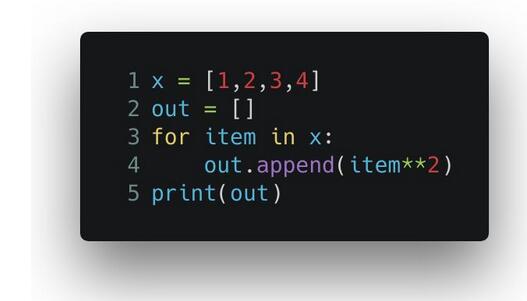
输出的结果是 [1, 4, 9, 16]
使用生成式:
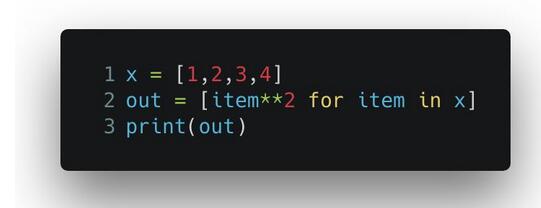
输出的结果也是 [1, 4, 9, 16]
02、Lambda 表达式
明明这个函数用不了几次,每次都要写一大串函数构建代码,是不是很累?别怕,Lambda 表达式来救你!Lambda 表达式能方便地创造简单、一次使用而且匿名的函数对象。基本上,它们让你无需费心构造一个函数,而是直接使用这个函数。
Lambda 表达式的基本语法是:

欧剃汉化,优达学城出品
要记住,Lambda 表达式创造的函数和普通的 def 构建的函数没什么不同,只不过函数体只有单独一个表达式而已。看看下面这个例子:

输出的结果是 10
03、Map 和 Filter 函数
一旦你掌握了 Lambda 表达式,将它们与 map 或 filter 函数一起使用,可谓是威力无比。
具体来说, map() 函数接收一个列表,和一个函数,它对列表里的每个元素调用一个函数进行处理,再将结果放进一个新列表里。下面这个例子中,map() 函数遍历 seq 中的每个元素,把它乘2,再把结果放入一个新列表,***返回这个列表。最外面一层 list() 函数是把 map() 返回的对象转换成列表格式。
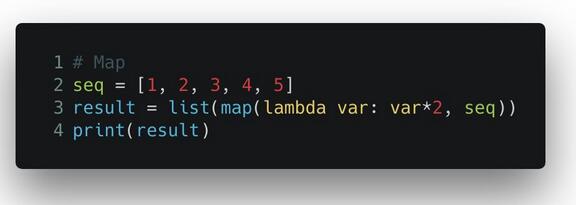
输出的结果是 [2, 4, 6, 8, 10]
而 filter() 函数略有不同,它接收一个列表,和一个规则函数,在对列表里的每个元素调用这个规则函数之后,它把所有返回值为假的元素从列表中剔除,然后返回这个过滤后的子列表。
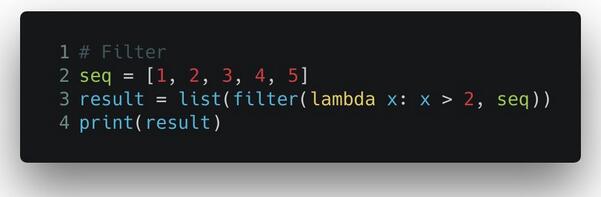
输出的结果是 [3, 4, 5]
04、Arange 和 Linspace 函数
为了快速方便地生成 numpy 的数组,你一定得熟悉 arange() 和 linspace() 这两个函数。这两个函数分别有自己的特定用法,不过对我们来说,它们都能很好地生成 numpy 数组(而不是用 range() ),这在数据科学的分析工作上可是相当好用的。
arange() 函数按照指定的步长返回一个等差数列。除开始和结束值之外,你还可以自定义步长和数据类型。请注意,给定的结束值参数是不会被包含在结果内的。
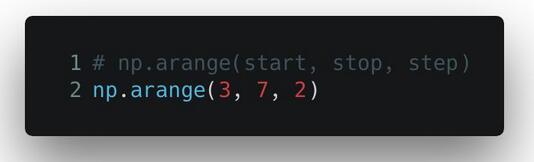
输出的是一个数组对象: array([3, 5])
linspace() 函数的用法也很类似,不过有一点小小的不同。 linspace() 返回的是将给定区间进行若干等分以后的等分点组成的数列。所以你传入的参数包括开始值、结束值,以及具体多少等分。linspace() 将这个区间进行等分后,把开始值、结束值和每个等分点都放进一个 NumPy 数组里。这在做数据可视化以及绘制坐标轴的时候都很有用。
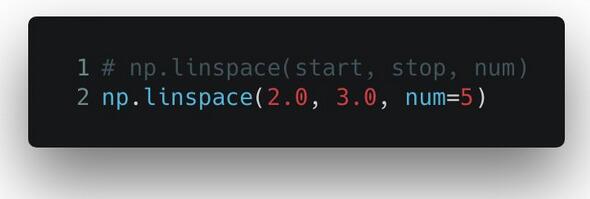
输出的是一个数组对象: array([ 2.0, 2.25, 2.5, 2.75, 3.0])
05、Pandas 中坐标轴(axis 参数)的意义
在 Pandas 里要筛掉某一列,或是在 NumPy 矩阵里要对数据求和的时候,你可能已经遇到过这个 axis 参数的问题。如果你还没见过,那提前了解一下也无妨。比如,对某个 Pandas 表这样处理:
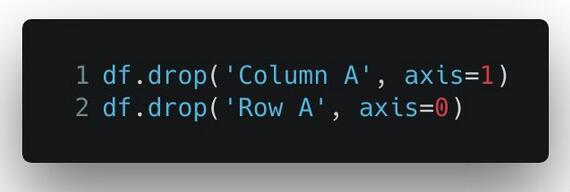
在我真正理解之前,我基本上每次要用到 drop 的时候,都得去重新查询一下哪个 axis 的值对应的是哪个,多到我自己都数不清了。正如上面这个示例,你大概已经看出,如果要处理列,axis 要设成 1,如果处理行,axis 要设成 0,对吧。但这是为什么呢?我最喜欢的一个解释(或者是我如何记住这一点的)是这样的:

获取 Pandas 数据表对象的 shape 属性,你将获得一个元组,元组的***个元素是数据表的行数,第二个元素是数据表的列数。想想 Python 里这两个元素的下标吧,前面一个是 0,后面一个是 1,对不对?所以对于 axis 参数,0 就是前面的行数,1 就是后面的列数,怎么样,好记吧?
06、用 Concat、Merge 和 Join 来合并数据表
如果你熟悉 SQL,这几个概念对你来说就是小菜一碟。不过不管怎样,这几个函数从本质上来说不过就是合并多个数据表的不同方式而已。当然,要时刻记着什么情况下该用哪个函数也不是一件容易的事,所以,让我们一起再回顾一下吧。
concat() 可以把一个或多个数据表按行(或列)的方向简单堆叠起来(看你传入的 axis 参数是 0 还是 1 咯)。
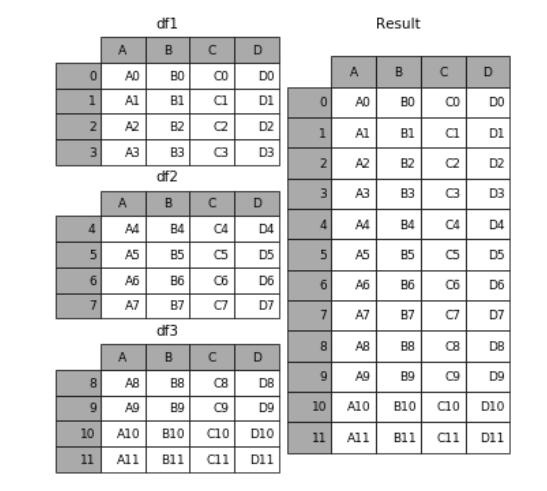
merge() 将会以用户指定的某个名字相同的列为主键进行对齐,把两个或多个数据表融合到一起。
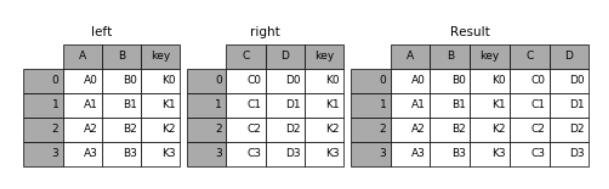
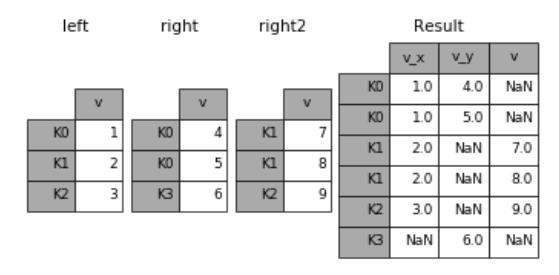
join()和 merge() 很相似,只不过 join() 是按数据表的索引进行对齐,而不是按某一个相同的列。当某个表缺少某个索引的时候,对应的值为空(NaN)。
有需要的话,你还可以查阅Pandas 官方文档 ,了解更详细的语法规则和应用实例,熟悉一些你可能会碰到的特殊情况。
07、Apply 函数
你可以把 apply() 当作是一个 map() 函数,只不过这个函数是专为 Pandas 的数据表和 series 对象打造的。对初学者来说,你可以把 series 对象想象成类似 NumPy 里的数组对象。它是一个一维带索引的数据表结构。
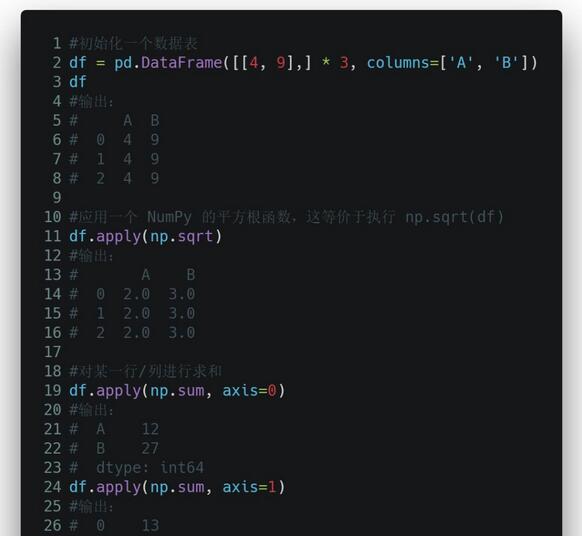
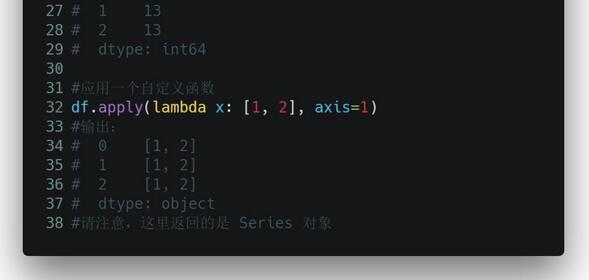
apply() 函数作用是,将一个函数应用到某个数据表中你指定的一行或一列中的每一个元素上。是不是很方便?特别是当你需要对某一列的所有元素都进行格式化或修改的时候,你就不用再一遍遍地循环啦!
这里就举几个简单的例子,让大家熟悉一下基本的语法规则:
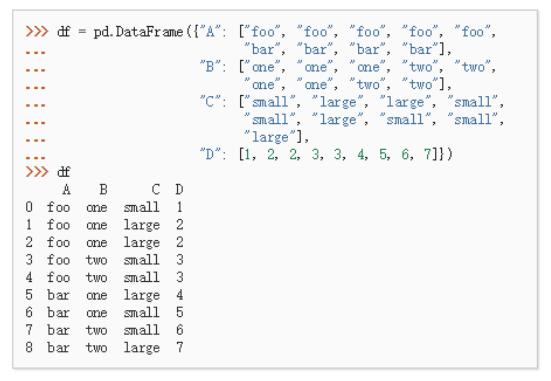
08、数据透视表(Pivot Tables)
***也最重要的是数据透视表。如果你对微软的 Excel 有一定了解的话,你大概也用过(或听过)Excel 里的“数据透视表”功能。Pandas 里内建的 pivot_table() 函数的功能也差不多,它能帮你对一个数据表进行格式化,并输出一个像 Excel 工作表一样的表格。实际使用中,透视表将根据一个或多个键对数据进行分组统计,将函数传入参数 aggfunc 中,数据将会按你指定的函数进行统计,并将结果分配到表格中。
下面是几个 pivot_table() 的应用例子:


“使用Python小细节有哪些”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





