这篇文章主要讲解了“集算器怎么协助Java处理结构化文本实现条件过滤”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“集算器怎么协助Java处理结构化文本实现条件过滤”吧!
直接用Java实现文本文件中数据按条件过滤会有如下的麻烦:
1、文件不是数据库,不能用SQL访问。当过滤条件变化时需要改写代码。如果要实现象SQL那样灵活的条件过滤,则需要自己实现动态表达式解析和求值,编程工作量非常大。
2、文件太大时不能一次性装入内存处理,而采用逐步读入方式在考虑到性能时又会涉及到文件缓冲区管理、拆行计算等复杂编程。
使用集算器来辅助Java编程,这些问题都不需要自己写代码解决。下面我们通过例子来看一下具体作法。
文本文件employee.txt中保存了员工数据。我们要读取员工信息,从中找出1981年1月1日(含)之后出生的女员工。
文本文件empolyee.txt的格式如下:
EID NAME SURNAME GENDER STATE BIRTHDAY HIREDATE DEPT SALARY
1 Rebecca Moore F California 1974-11-20 2005-03-11 R&D 7000
2 Ashley Wilson F New York 1980-07-19 2008-03-16 Finance 11000
3 Rachel Johnson F New Mexico 1970-12-17 2010-12-01 Sales 9000
4 Emily Smith F Texas 1985-03-07 2006-08-15 HR 7000
***shley Smith F Texas 1975-05-13 2004-07-30 R&D 16000
6 Matthew Johnson M California 1984-07-07 2005-07-07 Sales 11000
7 Alexis Smith F Illinois 1972-08-16 2002-08-16 Sales 9000
8 Megan Wilson F California 1979-04-19 1984-04-19 Marketing 11000
9 Victoria Davis F Texas 1983-12-07 2009-12-07 HR 3000
10 Ryan Johnson M Pennsylvania 1976-03-12 2006-03-12 R&D 13000
11 Jacob Moore M Texas 1974-12-16 2004-12-16 Sales 12000
12 Jessica Davis F New York 1980-09-11 2008-09-11 Sales 7000
13 Daniel Davis M Florida 1982-05-14 2010-05-14 Finance 10000
…
实现的思路是:用Java程序调用集算器脚本,读取和计算数据,之后将结果以ResultSet的方式返回给Java程序。由于集算器支持动态表达式解析和求值,使得Java程序可以像使用sql那样,灵活的过滤文本文件中的数据。
例如,我们需要查询1981年1月1日(含)之后出生的女员工,esProc程序可以从外部获得一个输入参数“where”作为条件,如下图:
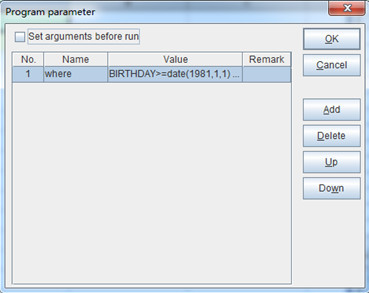
where是个字串,取值是:BIRTHDAY>=date(1981,1,1) && GENDER==”F”。
esProc代码如下:
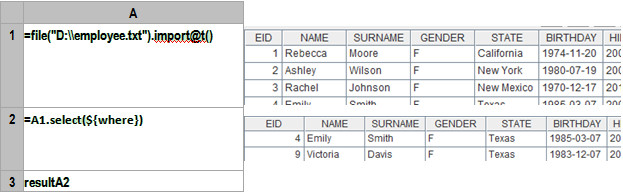
A1:定义一个file对象,读入数据,***行是标题,字段分隔符默认是tab。esProc的集成开发环境可以直观的显示出导入的数据,如上图右边部分。
A2:按照条件过滤。这里使用宏来实现动态解析表达式,其中的where就是传入参数。集算器先计算${…}里的表达式,将计算结果作为宏字符串值 替换${…}之后解释执行。这个例子中最终执行的是:=A1.select(BIRTHDAY>=date(1981,1,1) && GENDER==”F”)。
A3:向外部程序返回符合条件的结果集。
过滤条件发生变化时不用改变代码,只需改变where参数即可。例如,条件变为:查询1981年1月1日(含)之后出生的女员工,或者 NAME+SURNAME等于”RebeccaMoore”的员工。Where的参数值可以写 为:BIRTHDAY>=date(1981,1,1) && GENDER==”F” || NAME+SURNAME==”RebeccaMoore”。执行之后,A2中的结果集如下图:

在Java程序中使用esProc JDBC调用这段程序获得结果的代码如下:(将上述esProc程序保存为test.dfx):
//建立esProc jdbc连接
Class.forName(“com.esproc.jdbc.InternalDriver”);
con= DriverManager.getConnection(“jdbc:esproc:local://”);
//调用esProc 程序(存储过程),其中test是dfx的文件名
st =(com.esproc.jdbc.InternalCStatement)con.prepareCall(“call test(?)”);
//设置参数
st.setObject(1,” BIRTHDAY>=date(1981,1,1) && GENDER==\”F\” ||NAME+SURNAME==\”RebeccaMoore\”");//参数就是动态的过滤条件
//执行esProc存储过程
st.execute();
//获取结果集:符合条件的员工集合
ResultSet set = st.getResultSet();
对于代码较简单的脚本,还可以把代码直接写在调用集算器JDBC的Java程序中,而不必专门编写脚本文件(test.dfx):
st=(com. esproc.jdbc.InternalCStatement)con.createStatement();
ResultSet set= st.executeQuery(“=file(\”D:/employee.txt\”).import@t().select(BIRTHDAY>=date(1981,1,1)&&GENDER==\”F\” || NAME+SURNAME==\”RebeccaMoore\”)”);
这段Java代码直接调用了集算器的一句脚本:从文本文件中取得数据,并按照指定的条件过滤。结果集返回给ResultSet对象set。
上面方法中假定文件较小,可以全部读入内存。但实际上可能发生文件较大无法读入内容的情况,而且即使可以读入也没必要占太多内存,这时可以使用文件游标的方式来处理。集算器程序调整如下:
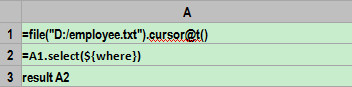
A1:定义一个file对象游标,***行是标题,字段分隔符默认是tab。
A2:按照条件过滤游标。这里使用宏来实现动态解析表达式,其中的where就是传入参数。集算器将先计算${…}里的表达式,将计算结果作为宏字 符串值替换${…}之后解释执行。这个例子中最终执行的是:=A1.select(BIRTHDAY>=date(1981,1,1) && GENDER==”F”)。
A3:返回游标。
虽然集算器给Java返回的是游标,但是Java调用的程序不用修改。在Java使用ResultSet遍历数据的时候集算器会自动取出游标对应的内容。
如果需要将过滤后的数据写入另一个文件而不是返回给主程序,只要将A3格的表达式改成:=file(“D:/employee_group.txt”).export@t(A2)即可,集算器将把游标数据写出成文件。
感谢各位的阅读,以上就是“集算器怎么协助Java处理结构化文本实现条件过滤”的内容了,经过本文的学习后,相信大家对集算器怎么协助Java处理结构化文本实现条件过滤这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





