python一直被病垢运行速度太慢,但是实际上python的执行效率并不慢,慢的是python用的解释器Cpython运行效率太差。
“一行代码让python的运行速度提高100倍”这绝不是哗众取宠的论调。
我们来看一下这个最简单的例子,从1一直累加到1亿。
最原始的代码:
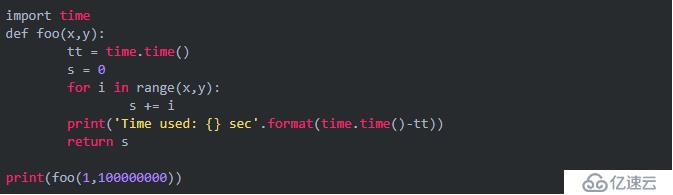
结果:
我们来加一行代码,再看看结果: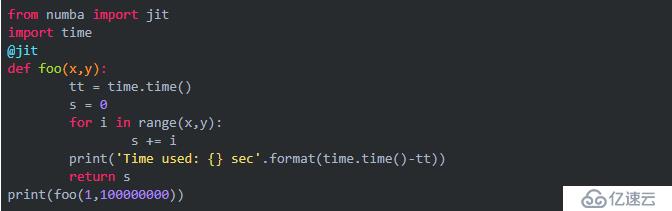
结果:
是不是快了100多倍呢?
那么下面就分享一下“为啥numba库的jit模块那么牛掰?”
NumPy的创始人Travis Oliphant在离开Enthought之后,创建了CONTINUUM,致力于将Python大数据处理方面的应用。最近推出的Numba项目能够将处理NumPy数组的Python函数JIT编译为机器码执行,从而上百倍的提高程序的运算速度。
Numba项目的主页上有Linux下的详细安装步骤。编译LLVM需要花一些时间。
Windows用户可以从Unofficial Windows Binaries for Python Extension Packages下载安装LLVMPy、meta和numba等几个扩展库。
下面我们看一个例子: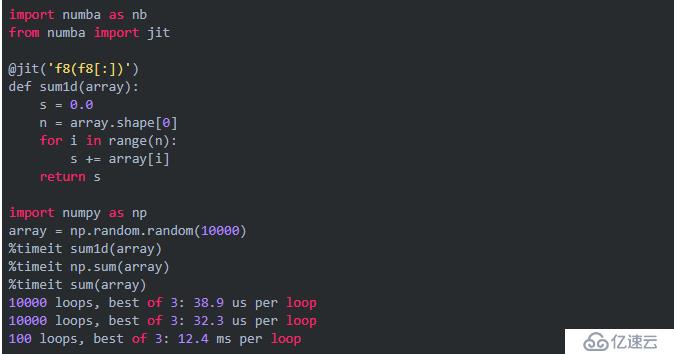
numba中提供了一些修饰器,它们可以将其修饰的函数JIT编译成机器码函数,并返回一个可在Python中调用机器码的包装对象。为了能将Python函数编译成能高速执行的机器码,我们需要告诉JIT编译器函数的各个参数和返回值的类型。我们可以通过多种方式指定类型信息,在上面的例子中,类型信息由一个字符串’f8(f8[:])’指定。其中’f8’表示8个字节双精度浮点数,括号前面的’f8’表示返回值类型,括号里的表示参数类型,’[:]’表示一维数组。因此整个类型字符串表示sum1d()是一个参数为双精度浮点数的一维数组,返回值是一个双精度浮点数。
需要注意的是,JIT所产生的函数只能对指定的类型的参数进行运算:
如果希望JIT能针对所有类型的参数进行运算,可以使用autojit: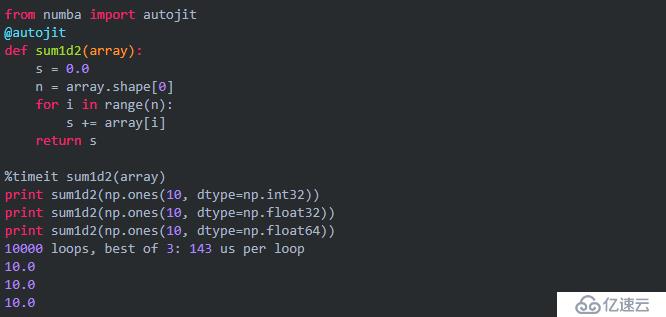
autoit虽然可以根据参数类型动态地产生机器码函数,但是由于它需要每次检查参数类型,因此计算速度也有所降低。numba的用法很简单,基本上就是用jit和autojit这两个修饰器,和一些类型对象。下面的程序列出numba所支持的所有类型:
工作原理
numba的通过meta模块解析Python函数的ast语法树,对各个变量添加相应的类型信息。然后调用llvmpy生成机器码,最后再生成机器码的Python调用接口。
meta模块
通过研究numba的工作原理,我们可以找到许多有用的工具。例如meta模块可在程序源码、ast语法树以及Python二进制码之间进行相互转换。下面看一个例子:
decompile_func能将函数的代码对象反编译成ast语法树,而str_ast能直观地显示ast语法树,使用这两个工具学习Python的ast语法树是很有帮助的。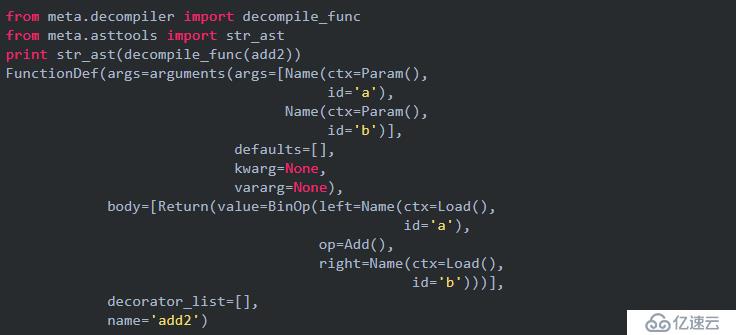
而python_source可以将ast语法树转换为Python源代码:
decompile_pyc将上述二者结合起来,它能将Python编译之后的pyc或者pyo文件反编译成源代码。下面我们先写一个tmp.py文件,然后通过py_compile将其编译成tmp.pyc。
下面调用decompile_pyc将tmp.pyc显示为源代码:
llvmpy模块
LLVM是一个动态编译器,llvmpy则可以通过Python调用LLVM动态地创建机器码。直接通过llvmpy创建机器码是比较繁琐的,例如下面的程序创建一个计算两个整数之和的函数,并调用它计算结果。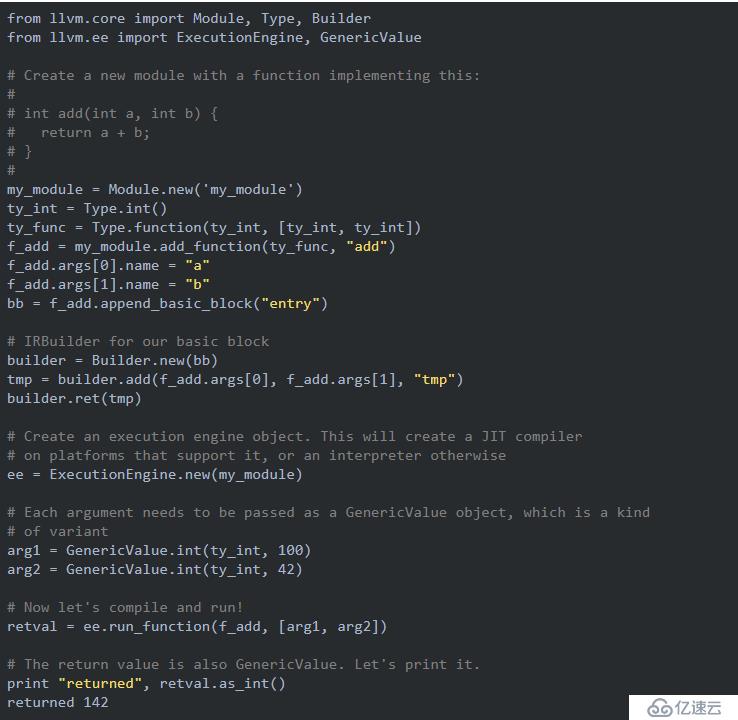
f_add就是一个动态生成的机器码函数,我们可以把它想象成C语言编译之后的函数。在上面的程序中,我们通过ee.run_function调用此函数,而实际上我们还可以获得它的地址,然后通过Python的ctypes模块调用它。
首先通过ee.get_pointer_to_function获得f_add函数的地址:
然后通过ctypes.PYFUNCTYPE创建一个函数类型:
最后通过f_type将函数的地址转换为可调用的Python函数,并调用它:
numba所完成的工作就是:
解析Python函数的ast语法树并加以改造,添加类型信息;
将带类型信息的ast语法树通过llvmpy动态地转换为机器码函数,然后再通过和ctypes类似的技术为机器码函数创建包装函数供Python调用。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





