打开操作
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True,
opener=None)
打开一个文件,返回一个文件对象(流对象)和文件描述符。打开文件失败,则返回异常
基本使用: 创建一个文件test,然后打开它,用完关闭
文件操作中,最常用的操作就是读和写。 文件访问的模式有两种:文本模式和二进制模式。不同模式下,操作函数
不尽相同,表现的结果也不一样。
open的参数
file
打开或者要创建的文件名。如果不指定路径,默认是当前路径
open默认是只读模式r打开已经存在的文件。
r 只读打开文件,如果使用write方法,会抛异常。 如果文件不存在,抛出FileNotFoundError异常
w 表示只写方式打开,如果读取则抛出异常 如果文件不存在,则直接创建文件 如果文件存在,则清空文件内容
x 文件不存在,创建文件,并只写方式打开。文件存在,抛出FileExistsError异常
a 文件存在,只写打开,追加内容 文件不存在,则创建后,只写打开,追加内容
r是只读,wxa都是只写。 wxa都可以产生新文件,w不管文件存在与否,都会生成全新内容的文件;a不管文件是
否存在,都能在打开的文件尾部追加;x必须要求文件事先不存在,自己造一个新文件
文本模式t 字符流,将文件的字节按照某种字符编码理解,按照字符操作。open的默认mode就是rt。
二进制模式b 字节流,将文件就按照字节理解,与字符编码无关。二进制模式操作时,字节操作使用bytes类型
+为r、w、a、x提供缺失的读或写功能,但是,获取文件对象依旧按照r、w、a、x自己的特征。 +不能单独使用,
可以认为它是为前面的模式字符做增强功能的。
文件指针
上面的例子中,已经说明了有一个指针。
文件指针,指向当前字节位置
mode=r,指针起始在0 mode=a,指针起始在EOF
tell() 显示指针当前位置
seek(offset[, whence]) 移动文件指针位置。offest偏移多少字节,whence从哪里开始。
文本模式下 whence 0 缺省值,表示从头开始,offest只能正整数 whence 1 表示从当前位置,offest只接受0
whence 2 表示从EOF开始,offest只接受0
buffering:缓冲区
-1 表示使用缺省大小的buffer。如果是二进制模式,使用io.DEFAULT_BUFFER_SIZE值,默认是4096或者8192。
如果是文本模式,如果是终端设备,是行缓存方式,如果不是,则使用二进制模式的策略。
0 只在二进制模式使用,表示关buffer
1 只在文本模式使用,表示使用行缓冲。意思就是见到换行符就flush
大于1 用于指定buffer的大小
buffer 缓冲区
缓冲区一个内存空间,一般来说是一个FIFO队列,到缓冲区满了或者达到阈值,数据才会flush到磁盘。
flush() 将缓冲区数据写入磁盘 close() 关闭前会调用flush()
1 文本模式,一般都用默认缓冲区大小
2 二进制模式,是一个个字节的操作,可以指定buffer的大小
3一般来说,默认缓冲区大小是个比较好的选择,除非明确知道,否则不调整它
一般编程中,明确知道需要写磁盘了,都会手动调用一次flush,而不是等到自动flush或者close的时候
read
read(size=-1)
size表示读取的多少个字符或字节;负数或者None表示读取到EOF
行读取
readline(size=-1)
一行行读取文件内容。size设置一次能读取行内几个字符或字节。
readlines(hint=-1)
读取所有行的列表。指定hint则返回指定的行数。
write
write(s),把字符串s写入到文件中并返回字符的个数 writelines(lines),将字符串列表写入文件。
close
flush并关闭文件对象。
文件已经关闭,再次关闭没有任何效果。
上下文管理
1 使用with ... as 关键字
2上下文管理的语句块并不会开启新的作用域
3with语句块执行完的时候,会自动关闭文件对象
StringIO
io模块中的类
from io import StringIO
内存中,开辟的一个文本模式的buffer,可以像文件对象一样操作它
当close方法被调用的时候,这个buffer会被释放
getvalue() 获取全部内容。跟文件指针没有关系
好处
一般来说,磁盘的操作比内存的操作要慢得多,内存足够的情况下,一般的优化思路是少落地,减少
磁盘IO的过程,可以大大提高程序的运行效率
BytesIO
io模块中的类
from io import BytesIO
内存中,开辟的一个二进制模式的buffer,可以像文件对象一样操作它
当close方法被调用的时候,这个buffer会被释放
file-like对象
类文件对象,可以像文件对象一样操作
socket对象、输入输出对象(stdin、stdout)都是类文件对象
路径操作
路径操作模块
3.4版本之前
os.path模块
3.4版本开始
建议使用pathlib模块,提供Path对象来操作。包括目录和文件。
pathlib模块
from pathlib import Path
路径拼接和分解
操作符/
Path对象 / Path对象
Path对象 / 字符串 或者 字符串 / Path对象
分解
parts属性,可以返回路径中的每一个部分
joinpath
joinpath(*other) 连接多个字符串到Path对象中
获取路径
str 获取路径字符串
bytes 获取路径字符串的bytes
父目录
parent 目录的逻辑父目录
parents 父目录序列,索引0是直接的父
目录组成部分
name、stem、suffix、suffixes、with_suffix(suffix)、with_name(name)
name 目录的最后一个部分
suffix 目录中最后一个部分的扩展名
stem 目录最后一个部分,没有后缀
suffixes 返回多个扩展名列表
with_suffix(suffix) 有扩展名则替换,无则补充扩展名
with_name(name) 替换目录最后一个部分并返回一个新的路径
全局方法
cwd() 返回当前工作目录
home() 返回当前家目录
判断方法
is_dir() 是否是目录,目录存在返回True
is_file() 是否是普通文件,文件存在返回True
is_symlink() 是否是软链接
is_socket() 是否是socket文件
is_block_device() 是否是块设备
is_char_device() 是否是字符设备
is_absolute() 是否是绝对路径
resolve() 返回一个新的路径,这个新路径就是当前Path对象的绝对路径,如果是软链接则直接被解析
absolute() 获取绝对路径
exists() 目录或文件是否存在
rmdir() 删除空目录。没有提供判断目录为空的方法
touch(mode=0o666, exist_ok=True) 创建一个文件
as_uri() 将路径返回成URI通配符
glob(pattern) 通配给定的模式
rglob(pattern) 通配给定的模式,递归目录
都返回一个生成器
匹配
match(pattern)
模式匹配,成功返回True
stat() 相当于stat命令
lstat() 同stat(),但如果是符号链接,则显示符号链接本身的文件信息
文件操作
Path.open(mode='r', buffering=-1, encoding=None, errors=None, newline=None)
使用方法类似内建函数open。返回一个文件对象
3.5增加的新函数
Path.read_bytes()
以'rb'读取路径对应文件,并返回二进制流。看源码
Path.read_text(encoding=None, errors=None)
以'rt'方式读取路径对应文件,返回文本。
Path.write_bytes(data)
以'wb'方式写入数据到路径对应文件。
Path.write_text(data, encoding=None, errors=None)
以'wt'方式写入字符串到路径对应文件。
序列化和反序列化
定义
serialization 序列化
将内存中对象存储下来,把它变成一个个字节。-> 二进制
deserialization 反序列化
将文件的一个个字节恢复成内存中对象。<- 二进制
序列化保存到文件就是持久化。
可以将数据序列化后持久化,或者网络传输;也可以将从文件中或者网络接收到的字节序列反序列化。
Python 提供了pickle 库。
pickle库
Python中的序列化、反序列化模块。
dumps 对象序列化为bytes对象
dump 对象序列化到文件对象,就是存入文件
loads 从bytes对象反序列化
load 对象反序列化,从文件读取数据
Json
JSON(JavaScript Object Notation, JS 对象标记) 是一种轻量级的数据交换格式。它基于 ECMAScript (w3c组织制定
的JS规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。
Json的数据类型
值
双引号引起来的字符串,数值,true和false,null,对象,数组,这些都是值
字符串
由双引号包围起来的任意字符的组合,可以有转义字符。
数值
有正负,有整数、浮点数。
对象
无序的键值对的集合
格式: {key1:value1, ... ,keyn:valulen}
key必须是一个字符串,需要双引号包围这个字符串。
value可以是任意合法的值。
数组
有序的值的集合
Python支持少量内建数据类型到Json类型的转换。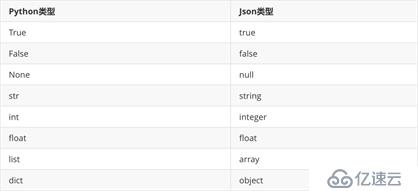
常用方法
python类型 json类型
dumps json编码
dump json编码并存入文件
loads json解码
load json解码并存入文件
一般json编码的数据很少落地,数据都是通过网络传输。传输的时候,要考虑压缩它。
本质上来说它就是个文本,就是个字符串。
json很简单,几乎语言编程都支持Json,所以应用范围十分广泛。
MessagePack
MessagePack是一个基于二进制高效的对象序列化类库,可用于跨语言通信。
它可以像JSON那样,在许多种语言之间交换结构对象。
但是它比JSON更快速也更轻巧。
支持Python、Ruby、Java、C/C++等众多语言。宣称比Google Protocol Buffers还要快4倍。
兼容 json和pickle。
常用方法
packb 序列化对象。提供了dumps来兼容pickle和json。
unpackb 反序列化对象。提供了loads来兼容。
pack 序列化对象保存到文件对象。提供了dump来兼容。
unpack 反序列化对象保存到文件对象。提供了load来兼容。
正则表达式
. 匹配除换行符外任意一个字符
[abc] 字符集合,只能表示一个字符位置。匹配所包含的任意一个字符
[^abc] 字符集合,只能表示一个字符位置。匹配除去集合内字符的任意一个字符
[a-z] 字符范围,一个集合,表示一个字符位置匹配所包含的任意一个字符
[^a-z] 字符范围,一个集合,表示一个字符位置匹配除去集合内字符的任意一个字符
\b 匹配单词的边界
\B 不匹配单词的边界
\d 等同[0-9] 匹配一位数字
\D 等同[^0-9] 匹配一位非数字
\s 匹配1位空白字符,包括换行符、制表符、空格等同[\f\r\n\t\v]
\S 匹配1位非空白字符
\w 等同[a-zA-Z0-9_] 包含中文
\W 匹配\w之外的字符
凡是在正则表达式中有特殊意义的符号,如果想使用它的本意,请使用\转义。
反斜杠自身,得使用\
\r、\n还是转义后代表回车、换行
重复
分组(捕获)断言
x y 匹配x或y
(pattern) 分组(捕获)后会自动分配组号从1开始可以改变优先级 \数字 匹配对应的分组(指的是前一个匹配上的分组的内容)
(?:pattern) 只改变优先级不分组
(?<name>exp)(?nameexp) 分组捕获 给组命名Python句法为(?P<name>exp)
(?=exp) 零宽度正预测先行断言断言exp一定在匹配的右边出现
(?<=exp) 零宽度正回顾后发断言断言exp一定出现在匹配的左边出现
(?!exp) 零宽度负预测先行断言断言exp一定不会出现在右侧
(?<!exp) 零宽度负回顾后发断言断言exp一定不会出现在左侧
(?#comment) 注释
贪婪与非贪婪
默认贪婪模式,尽可能多的匹配字符串
*? 匹配任意次,尽可能少重复
+? 匹配至少一次,尽可能少重复
?? 匹配0或1次,尽可能少重复
{n}? 匹配至少n次,尽可能少重复
{n,m}? 匹配至少n次,至多m次,尽可能少重复
引擎选项
IgnoreCase 匹配时忽略大小写 re.Ire.IGNORECASE
Singleline 单行模式,可穿透/n re.Sre.DOTALL
Multiline 多行模式 re.Mre.MULTILINE
IgnorePatternWhitespace 忽略表达式中空白字符,若要使用空白
单行模式:
. 可以匹配所有字符,包括换行符。
^ 表示整个字符串的开头,$整个字符串的结尾
多行模式:
. 可以匹配除了换行符之外的字符。
^ 表示行首,$行尾
^ 表示整个字符串的开始,$ 表示整个字符串的结尾。开始指的是\n后紧接着下一个字符,结束指的是/n前的字符
可以认为,单行模式就如同看穿了换行符,所有文本就是一个长长的只有一行的字符串,所以^就是这一行字符串的行
首,$就是这一行的行尾。
多行模式,无法穿透换行符,^和$还是行首行尾的意思,只不过限于每一行
注意:注意字符串中看不见的换行符,\r\n会影响e$的测试,e$只能匹配e\n
Python正则表达式
re模块
编译
re.compile(pattern, flags=0)
返回正则表达式对象regex
正则表达式编译的结果保存,下次使用同样的pattern时不需要重新编译
单次匹配
regex.match(string[, pos[, endpos]])
从字符串开头匹配,可指定开始与结束位置 返回match对象
regex.search(string[, pos[, endpos]])
从头搜索直到第一个匹配,可指定开始与结束位置 返回match对象
regex.fullmatch(string[, pos[, endpos]])
整个字符串与正则表达式匹配
全文搜索
regex.findall(string[, pos[, endpos]])
对整个字符串从左至右匹配,返回所有匹配项的列表
regex.finditer(string[, pos[, endpos]])
对整个字符串,从左至右匹配,返回所有匹配项的迭代器,每项都是match对象
匹配替换
regex.sub(replacement, string, count=0)
使用pattern对字符串string进行匹配,对匹配项用replacement替换
replacement可以是string、bytes、function
regex.subn(replacement, string, count=0)
功能类似sub 返回一个元组 (new_string, number_of_subs_made)
分割字符串
regex.split(string, maxsplit=0)
返回列表
分组
使用(pattern)捕获的数据放到组中
match类方法
group(N)
1-N时对应的分组 0但会整个匹配的字符串
如果使用了命名分组,可用group(name)方式取出
groups()
返回所有组的一个元组
groupdict()
返回所有命名分组的字典
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





