这篇文章主要介绍“OpenStack Cinder服务状态排错方法是什么”,在日常操作中,相信很多人在OpenStack Cinder服务状态排错方法是什么问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”OpenStack Cinder服务状态排错方法是什么”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
最近手动搭建了一个openstack环境,创建硬盘时失败,查看日志,提示无法进行调度,怀疑是cinder节点出现问题,去cinder节点查看服务 ,状态显示正常。
systemctl status openstack-cinder-volume.service然后在控制节点查看cinder服务,openstack volume service list
正常情况下显示:
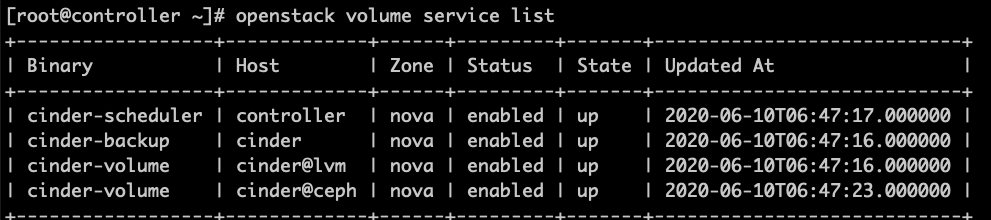
结果显示cinder-volume的state为down,查看日志发现没有任何错误信息,重启cinder的各种服务仍然没有效果,最后决定跟踪源码(说明:文中代码对应的是OpenStack Train版)。
找到openstack volume service list对应的实现代码。
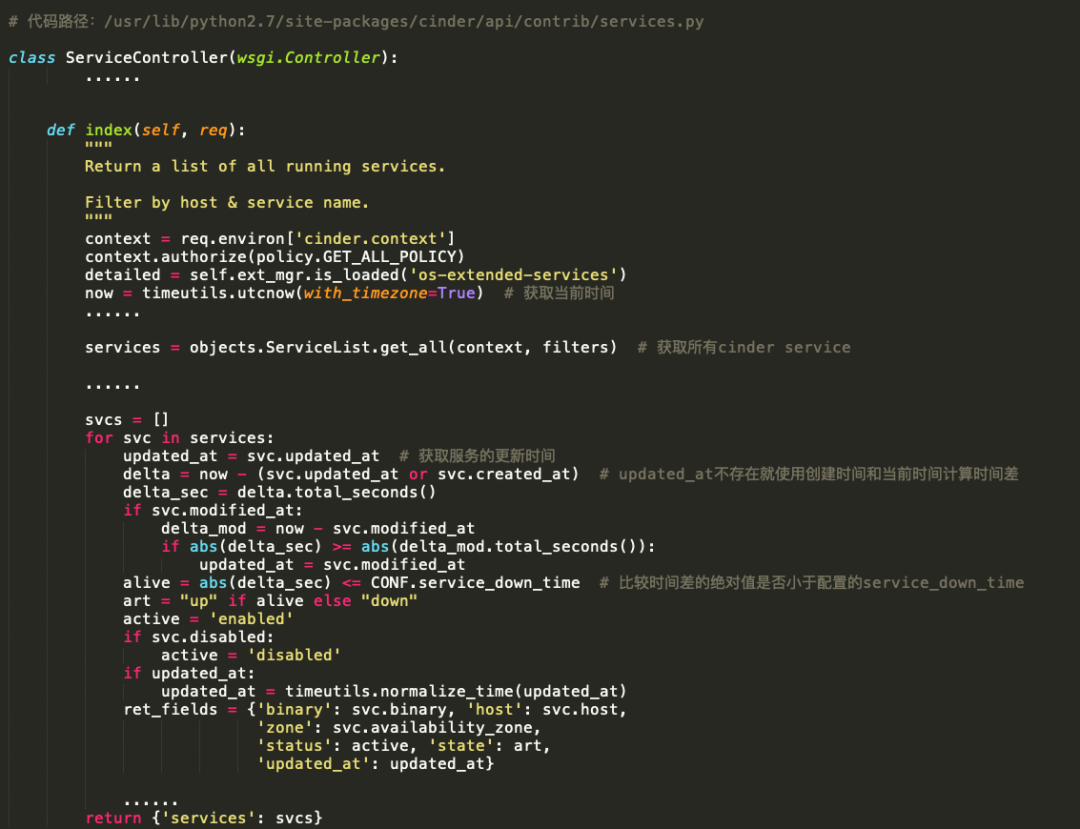
now = timeutils.utcnow(with_timezone=True)由于openstack-cinder-api.servic服务在controller节点启动,所以获取的是controller节点的当前时间。
services = objects.ServiceList.get_all(context, filters)最终会从cinder数据库的services表中获取所有服务数据。

alive = abs(delta_sec) <= CONF.service_down_time,比较时间差的绝对值是否小于配置的service_down_time,其中service_down_time默认时间是60s。
cfg.IntOpt('service_down_time', default=60, help='Maximum time since last check-in for a service to be ' 'considered up'),art = "up" if alive else "down" 差值小于60,则service 状态为 up,否则为down。由此可见cinder service的state值取决于cinder数据库中 service 表每行数据的 updated_at 列的值和当前 controller 节点的时间差是否在配置的范围之内。
解决问题
上面cinder-volume出现down的原因就是因为运行openstack-cinder-volume.service服务的存储节点时间与controller节点时间差值过大。为了保证状态为up,必须保证两节点的时间差在service_down_time - report_interval之内,默认情况下,差值为50秒。所以同步两台服务器时间之后,再次查看,发现cinder-volume的state变为up。
cinder服务更新机制
下面说下 Cinder Service 的更新机制。

report_interval默认时间是10s,
cfg.IntOpt('report_interval', default=10, help='Interval, in seconds, between nodes reporting state ' 'to datastore'),到此,关于“OpenStack Cinder服务状态排错方法是什么”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://mp.weixin.qq.com/s/1RHxhpVZ0Zf4K8S_O9LFsA



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



