жҖҺд№Ҳз”Ёе®һдҫӢи§ЈжһҗSpark Core
д»ҠеӨ©е°ұи·ҹеӨ§е®¶иҒҠиҒҠжңүе…іжҖҺд№Ҳз”Ёе®һдҫӢи§ЈжһҗSpark CoreпјҢеҸҜиғҪеҫҲеӨҡдәәйғҪдёҚеӨӘдәҶи§ЈпјҢдёәдәҶи®©еӨ§е®¶жӣҙеҠ дәҶи§ЈпјҢе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеёҢжңӣеӨ§е®¶ж №жҚ®иҝҷзҜҮж–Үз« еҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
е…ҲжқҘдёҖдёӘй—®йўҳпјҢд№ҹжҳҜйқўиҜ•дёӯеёёй—®зҡ„пјҡ
Sparkдёәд»Җд№ҲдјҡжөҒиЎҢпјҹ
еҺҹеӣ 1пјҡдјҳз§Җзҡ„ж•°жҚ®жЁЎеһӢе’Ңдё°еҜҢи®Ўз®—жҠҪиұЎ
Spark дә§з”ҹд№ӢеүҚпјҢе·Із»ҸжңүMapReduceиҝҷзұ»йқһеёёжҲҗзҶҹзҡ„и®Ўз®—зі»з»ҹеӯҳеңЁдәҶпјҢ并жҸҗдҫӣдәҶй«ҳеұӮж¬Ўзҡ„API(map/reduce)пјҢжҠҠи®Ўз®—иҝҗиЎҢеңЁйӣҶзҫӨдёӯ并жҸҗдҫӣе®№й”ҷиғҪеҠӣпјҢд»ҺиҖҢе®һзҺ°еҲҶеёғејҸи®Ўз®—гҖӮ
иҷҪ然MapReduceжҸҗдҫӣдәҶеҜ№ж•°жҚ®и®ҝй—®е’Ңи®Ўз®—зҡ„жҠҪиұЎпјҢдҪҶжҳҜеҜ№дәҺж•°жҚ®зҡ„еӨҚз”Ёе°ұжҳҜз®ҖеҚ•зҡ„е°Ҷдёӯй—ҙж•°жҚ®еҶҷеҲ°дёҖдёӘзЁіе®ҡзҡ„ж–Ү件系з»ҹдёӯ(дҫӢеҰӮHDFS)пјҢжүҖд»Ҙдјҡдә§з”ҹж•°жҚ®зҡ„еӨҚеҲ¶еӨҮд»ҪпјҢзЈҒзӣҳзҡ„I/Oд»ҘеҸҠж•°жҚ®зҡ„еәҸеҲ—еҢ–пјҢжүҖд»ҘеңЁйҒҮеҲ°йңҖиҰҒеңЁеӨҡдёӘи®Ўз®—д№Ӣй—ҙеӨҚз”Ёдёӯй—ҙз»“жһңзҡ„ж“ҚдҪңж—¶ж•ҲзҺҮе°ұдјҡйқһеёёзҡ„дҪҺгҖӮиҖҢиҝҷзұ»ж“ҚдҪңжҳҜйқһеёёеёёи§Ғзҡ„пјҢдҫӢеҰӮиҝӯд»ЈејҸи®Ўз®—пјҢдәӨдә’ејҸж•°жҚ®жҢ–жҺҳпјҢеӣҫи®Ўз®—зӯүгҖӮ
и®ӨиҜҶеҲ°иҝҷдёӘй—®йўҳеҗҺпјҢеӯҰжңҜз•Ңзҡ„ AMPLab жҸҗеҮәдәҶдёҖдёӘж–°зҡ„жЁЎеһӢпјҢеҸ«еҒҡ RDDгҖӮRDD жҳҜдёҖдёӘеҸҜд»Ҙе®№й”ҷ且并иЎҢзҡ„ж•°жҚ®з»“жһ„(е…¶е®һеҸҜд»ҘзҗҶи§ЈжҲҗеҲҶеёғејҸзҡ„йӣҶеҗҲпјҢж“ҚдҪңиө·жқҘе’Ңж“ҚдҪңжң¬ең°йӣҶеҗҲдёҖж ·з®ҖеҚ•)пјҢе®ғеҸҜд»Ҙи®©з”ЁжҲ·жҳҫејҸзҡ„е°Ҷдёӯй—ҙз»“жһңж•°жҚ®йӣҶдҝқеӯҳеңЁеҶ…еӯҳдёӯпјҢ并且йҖҡиҝҮжҺ§еҲ¶ж•°жҚ®йӣҶзҡ„еҲҶеҢәжқҘиҫҫеҲ°ж•°жҚ®еӯҳж”ҫеӨ„зҗҶжңҖдјҳеҢ–.еҗҢж—¶ RDDд№ҹжҸҗдҫӣдәҶдё°еҜҢзҡ„ API (mapгҖҒreduceгҖҒfilterгҖҒforeachгҖҒredeceByKey...)жқҘж“ҚдҪңж•°жҚ®йӣҶгҖӮеҗҺжқҘ RDDиў« AMPLab еңЁдёҖдёӘеҸ«еҒҡ Spark зҡ„жЎҶжһ¶дёӯжҸҗдҫӣ并ејҖжәҗгҖӮ
з®ҖиҖҢиЁҖд№ӢпјҢSpark еҖҹйүҙдәҶ MapReduce жҖқжғіеҸ‘еұ•иҖҢжқҘпјҢдҝқз•ҷдәҶе…¶еҲҶеёғејҸ并иЎҢи®Ўз®—зҡ„дјҳзӮ№е№¶ж”№иҝӣдәҶе…¶жҳҺжҳҫзҡ„зјәйҷ·гҖӮи®©дёӯй—ҙж•°жҚ®еӯҳеӮЁеңЁеҶ…еӯҳдёӯжҸҗй«ҳдәҶиҝҗиЎҢйҖҹеәҰгҖҒ并жҸҗдҫӣдё°еҜҢзҡ„ж“ҚдҪңж•°жҚ®зҡ„APIжҸҗй«ҳдәҶејҖеҸ‘йҖҹеәҰгҖӮ
еҺҹеӣ 2пјҡе®Ңе–„зҡ„з”ҹжҖҒеңҲ-fullstack
зӣ®еүҚпјҢSparkе·Із»ҸеҸ‘еұ•жҲҗдёәдёҖдёӘеҢ…еҗ«еӨҡдёӘеӯҗйЎ№зӣ®зҡ„йӣҶеҗҲпјҢе…¶дёӯеҢ…еҗ«SparkSQLгҖҒSpark StreamingгҖҒGraphXгҖҒMLlibзӯүеӯҗйЎ№зӣ®гҖӮ
Spark Coreпјҡе®һзҺ°дәҶ Spark зҡ„еҹәжң¬еҠҹиғҪпјҢеҢ…еҗ«RDDгҖҒд»»еҠЎи°ғеәҰгҖҒеҶ…еӯҳз®ЎзҗҶгҖҒй”ҷиҜҜжҒўеӨҚгҖҒдёҺеӯҳеӮЁзі»з»ҹдәӨдә’зӯүжЁЎеқ—гҖӮ
Spark SQLпјҡSpark з”ЁжқҘж“ҚдҪңз»“жһ„еҢ–ж•°жҚ®зҡ„зЁӢеәҸеҢ…гҖӮйҖҡиҝҮ Spark SQLпјҢжҲ‘们еҸҜд»ҘдҪҝз”Ё SQLж“ҚдҪңж•°жҚ®гҖӮ
Spark StreamingпјҡSpark жҸҗдҫӣзҡ„еҜ№е®һж—¶ж•°жҚ®иҝӣиЎҢжөҒејҸи®Ўз®—зҡ„组件гҖӮжҸҗдҫӣдәҶз”ЁжқҘж“ҚдҪңж•°жҚ®жөҒзҡ„ APIгҖӮ
Spark MLlibпјҡжҸҗдҫӣеёёи§Ғзҡ„жңәеҷЁеӯҰд№ (ML)еҠҹиғҪзҡ„зЁӢеәҸеә“гҖӮеҢ…жӢ¬еҲҶзұ»гҖҒеӣһеҪ’гҖҒиҒҡзұ»гҖҒеҚҸеҗҢиҝҮж»ӨзӯүпјҢиҝҳжҸҗдҫӣдәҶжЁЎеһӢиҜ„дј°гҖҒж•°жҚ®еҜје…ҘзӯүйўқеӨ–зҡ„ж”ҜжҢҒеҠҹиғҪгҖӮ
GraphX(еӣҫи®Ўз®—)пјҡSparkдёӯз”ЁдәҺеӣҫи®Ўз®—зҡ„APIпјҢжҖ§иғҪиүҜеҘҪпјҢжӢҘжңүдё°еҜҢзҡ„еҠҹиғҪе’Ңиҝҗз®—з¬ҰпјҢиғҪеңЁжө·йҮҸж•°жҚ®дёҠиҮӘеҰӮең°иҝҗиЎҢеӨҚжқӮзҡ„еӣҫз®—жі•гҖӮ
йӣҶзҫӨз®ЎзҗҶеҷЁпјҡSpark и®ҫи®ЎдёәеҸҜд»Ҙй«ҳж•Ҳең°еңЁдёҖдёӘи®Ўз®—иҠӮзӮ№еҲ°ж•°еҚғдёӘи®Ўз®—иҠӮзӮ№д№Ӣй—ҙдјёзј©и®Ўз®—гҖӮ
StructuredStreaming:еӨ„зҗҶз»“жһ„еҢ–жөҒ,з»ҹдёҖдәҶзҰ»зәҝе’Ңе®һж—¶зҡ„APIгҖӮ
Spark VS Hadoop
| Hadoop | Spark |
|---|
| зұ»еһӢ | еҹәзЎҖе№іеҸ°, еҢ…еҗ«и®Ўз®—, еӯҳеӮЁ, и°ғеәҰ | еҲҶеёғејҸи®Ўз®—е·Ҙе…· |
| еңәжҷҜ | еӨ§и§„жЁЎж•°жҚ®йӣҶдёҠзҡ„жү№еӨ„зҗҶ | иҝӯд»Ји®Ўз®—, дәӨдә’ејҸи®Ўз®—, жөҒи®Ўз®— |
| д»·ж ј | еҜ№жңәеҷЁиҰҒжұӮдҪҺ, дҫҝе®ң | еҜ№еҶ…еӯҳжңүиҰҒжұӮ, зӣёеҜ№иҫғиҙө |
| зј–зЁӢиҢғејҸ | Map+Reduce, API иҫғдёәеә•еұӮ, з®—жі•йҖӮеә”жҖ§е·® | RDDз»„жҲҗDAGжңүеҗ‘ж— зҺҜеӣҫ, API иҫғдёәйЎ¶еұӮ, ж–№дҫҝдҪҝз”Ё |
| ж•°жҚ®еӯҳеӮЁз»“жһ„ | MapReduceдёӯй—ҙи®Ўз®—з»“жһңеӯҳеңЁHDFSзЈҒзӣҳдёҠ, 延иҝҹеӨ§ | RDDдёӯй—ҙиҝҗз®—з»“жһңеӯҳеңЁеҶ…еӯҳдёӯ , 延иҝҹе°Ҹ |
| иҝҗиЎҢж–№ејҸ | Taskд»ҘиҝӣзЁӢж–№ејҸз»ҙжҠӨ, д»»еҠЎеҗҜеҠЁж…ў | Taskд»ҘзәҝзЁӢж–№ејҸз»ҙжҠӨ, д»»еҠЎеҗҜеҠЁеҝ« |
????жіЁж„Ҹпјҡ
е°Ҫз®ЎSparkзӣёеҜ№дәҺHadoopиҖҢиЁҖе…·жңүиҫғеӨ§дјҳеҠҝпјҢдҪҶSpark并дёҚиғҪе®Ңе…Ёжӣҝд»ЈHadoopпјҢSparkдё»иҰҒз”ЁдәҺжӣҝд»ЈHadoopдёӯзҡ„MapReduceи®Ўз®—жЁЎеһӢгҖӮеӯҳеӮЁдҫқ然еҸҜд»ҘдҪҝз”ЁHDFSпјҢдҪҶжҳҜдёӯй—ҙз»“жһңеҸҜд»Ҙеӯҳж”ҫеңЁеҶ…еӯҳдёӯпјӣи°ғеәҰеҸҜд»ҘдҪҝз”ЁSparkеҶ…зҪ®зҡ„пјҢд№ҹеҸҜд»ҘдҪҝз”ЁжӣҙжҲҗзҶҹзҡ„и°ғеәҰзі»з»ҹYARNзӯүгҖӮ
е®һйҷ…дёҠпјҢSparkе·Із»ҸеҫҲеҘҪең°иһҚе…ҘдәҶHadoopз”ҹжҖҒеңҲпјҢ并жҲҗдёәе…¶дёӯзҡ„йҮҚиҰҒдёҖе‘ҳпјҢе®ғеҸҜд»ҘеҖҹеҠ©дәҺYARNе®һзҺ°иө„жәҗи°ғеәҰз®ЎзҗҶпјҢеҖҹеҠ©дәҺHDFSе®һзҺ°еҲҶеёғејҸеӯҳеӮЁгҖӮ
жӯӨеӨ–пјҢHadoopеҸҜд»ҘдҪҝз”Ёе»үд»·зҡ„гҖҒејӮжһ„зҡ„жңәеҷЁжқҘеҒҡеҲҶеёғејҸеӯҳеӮЁдёҺи®Ўз®—пјҢдҪҶжҳҜпјҢSparkеҜ№зЎ¬д»¶зҡ„иҰҒжұӮзЁҚй«ҳдёҖдәӣпјҢеҜ№еҶ…еӯҳдёҺCPUжңүдёҖе®ҡзҡ„иҰҒжұӮгҖӮ
Spark Core
дёҖгҖҒRDDиҜҰи§Ј
1. дёәд»Җд№ҲиҰҒжңүRDD?
еңЁи®ёеӨҡиҝӯд»ЈејҸз®—жі•(жҜ”еҰӮжңәеҷЁеӯҰд№ гҖҒеӣҫз®—жі•зӯү)е’ҢдәӨдә’ејҸж•°жҚ®жҢ–жҺҳдёӯпјҢдёҚеҗҢи®Ўз®—йҳ¶ж®өд№Ӣй—ҙдјҡйҮҚз”Ёдёӯй—ҙз»“жһңпјҢеҚідёҖдёӘйҳ¶ж®өзҡ„иҫ“еҮәз»“жһңдјҡдҪңдёәдёӢдёҖдёӘйҳ¶ж®өзҡ„иҫ“е…ҘгҖӮдҪҶжҳҜпјҢд№ӢеүҚзҡ„MapReduceжЎҶжһ¶йҮҮз”ЁйқһеҫӘзҺҜејҸзҡ„ж•°жҚ®жөҒжЁЎеһӢпјҢжҠҠдёӯй—ҙз»“жһңеҶҷе…ҘеҲ°HDFSдёӯпјҢеёҰжқҘдәҶеӨ§йҮҸзҡ„ж•°жҚ®еӨҚеҲ¶гҖҒзЈҒзӣҳIOе’ҢеәҸеҲ—еҢ–ејҖй”ҖгҖӮдё”иҝҷдәӣжЎҶжһ¶еҸӘиғҪж”ҜжҢҒдёҖдәӣзү№е®ҡзҡ„и®Ўз®—жЁЎејҸ(map/reduce)пјҢ并没жңүжҸҗдҫӣдёҖз§ҚйҖҡз”Ёзҡ„ж•°жҚ®жҠҪиұЎгҖӮ
AMPе®һйӘҢе®ӨеҸ‘иЎЁзҡ„дёҖзҜҮе…ідәҺRDDзҡ„и®әж–Ү:гҖҠResilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster ComputingгҖӢе°ұжҳҜдёәдәҶи§ЈеҶіиҝҷдәӣй—®йўҳзҡ„гҖӮ
RDDжҸҗдҫӣдәҶдёҖдёӘжҠҪиұЎзҡ„ж•°жҚ®жЁЎеһӢпјҢи®©жҲ‘们дёҚеҝ…жӢ…еҝғеә•еұӮж•°жҚ®зҡ„еҲҶеёғејҸзү№жҖ§пјҢеҸӘйңҖе°Ҷе…·дҪ“зҡ„еә”з”ЁйҖ»иҫ‘иЎЁиҫҫдёәдёҖзі»еҲ—иҪ¬жҚўж“ҚдҪң(еҮҪж•°)пјҢдёҚеҗҢRDDд№Ӣй—ҙзҡ„иҪ¬жҚўж“ҚдҪңд№Ӣй—ҙиҝҳеҸҜд»ҘеҪўжҲҗдҫқиө–е…ізі»пјҢиҝӣиҖҢе®һзҺ°з®ЎйҒ“еҢ–пјҢд»ҺиҖҢйҒҝе…ҚдәҶдёӯй—ҙз»“жһңзҡ„еӯҳеӮЁпјҢеӨ§еӨ§йҷҚдҪҺдәҶж•°жҚ®еӨҚеҲ¶гҖҒзЈҒзӣҳIOе’ҢеәҸеҲ—еҢ–ејҖй”ҖпјҢ并且иҝҳжҸҗдҫӣдәҶжӣҙеӨҡзҡ„API(map/reduec/filter/groupBy...)гҖӮ
2. RDDжҳҜд»Җд№Ҳ?
RDD(Resilient Distributed Dataset)еҸ«еҒҡеј№жҖ§еҲҶеёғејҸж•°жҚ®йӣҶпјҢжҳҜSparkдёӯжңҖеҹәжң¬зҡ„ж•°жҚ®жҠҪиұЎпјҢд»ЈиЎЁдёҖдёӘдёҚеҸҜеҸҳгҖҒеҸҜеҲҶеҢәгҖҒйҮҢйқўзҡ„е…ғзҙ еҸҜ并иЎҢи®Ўз®—зҡ„йӣҶеҗҲгҖӮ еҚ•иҜҚжӢҶи§Јпјҡ
Resilient пјҡе®ғжҳҜеј№жҖ§зҡ„пјҢRDDйҮҢйқўзҡ„дёӯзҡ„ж•°жҚ®еҸҜд»ҘдҝқеӯҳеңЁеҶ…еӯҳдёӯжҲ–иҖ…зЈҒзӣҳйҮҢйқў
Distributed пјҡе®ғйҮҢйқўзҡ„е…ғзҙ жҳҜеҲҶеёғејҸеӯҳеӮЁзҡ„пјҢеҸҜд»Ҙз”ЁдәҺеҲҶеёғејҸи®Ўз®—
Dataset: е®ғжҳҜдёҖдёӘйӣҶеҗҲпјҢеҸҜд»Ҙеӯҳж”ҫеҫҲеӨҡе…ғзҙ
3. RDDдё»иҰҒеұһжҖ§
иҝӣе…ҘRDDзҡ„жәҗз ҒдёӯзңӢдёӢпјҡ
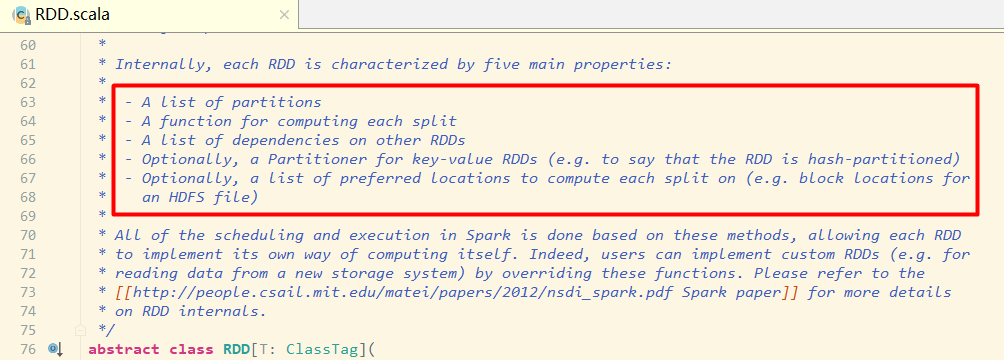
еңЁжәҗз ҒдёӯеҸҜд»ҘзңӢеҲ°жңүеҜ№RDDд»Ӣз»Қзҡ„жіЁйҮҠпјҢжҲ‘们жқҘзҝ»иҜ‘дёӢпјҡ
A list of partitions пјҡ дёҖз»„еҲҶзүҮ(Partition)/дёҖдёӘеҲҶеҢә(Partition)еҲ—иЎЁпјҢеҚіж•°жҚ®йӣҶзҡ„еҹәжң¬з»„жҲҗеҚ•дҪҚгҖӮ еҜ№дәҺRDDжқҘиҜҙпјҢжҜҸдёӘеҲҶзүҮйғҪдјҡиў«дёҖдёӘи®Ўз®—д»»еҠЎеӨ„зҗҶпјҢеҲҶзүҮж•°еҶіе®ҡ并иЎҢеәҰгҖӮ з”ЁжҲ·еҸҜд»ҘеңЁеҲӣе»әRDDж—¶жҢҮе®ҡRDDзҡ„еҲҶзүҮдёӘж•°пјҢеҰӮжһңжІЎжңүжҢҮе®ҡпјҢйӮЈд№Ҳе°ұдјҡйҮҮз”Ёй»ҳи®ӨеҖјгҖӮ
A function for computing each split пјҡ дёҖдёӘеҮҪж•°дјҡиў«дҪңз”ЁеңЁжҜҸдёҖдёӘеҲҶеҢәгҖӮ SparkдёӯRDDзҡ„и®Ўз®—жҳҜд»ҘеҲҶзүҮдёәеҚ•дҪҚзҡ„пјҢcomputeеҮҪж•°дјҡиў«дҪңз”ЁеҲ°жҜҸдёӘеҲҶеҢәдёҠгҖӮ
A list of dependencies on other RDDs пјҡ дёҖдёӘRDDдјҡдҫқиө–дәҺе…¶д»–еӨҡдёӘRDDгҖӮ RDDзҡ„жҜҸж¬ЎиҪ¬жҚўйғҪдјҡз”ҹжҲҗдёҖдёӘж–°зҡ„RDDпјҢжүҖд»ҘRDDд№Ӣй—ҙе°ұдјҡеҪўжҲҗзұ»дјјдәҺжөҒж°ҙзәҝдёҖж ·зҡ„еүҚеҗҺдҫқиө–е…ізі»гҖӮеңЁйғЁеҲҶеҲҶеҢәж•°жҚ®дёўеӨұж—¶пјҢSparkеҸҜд»ҘйҖҡиҝҮиҝҷдёӘдҫқиө–е…ізі»йҮҚж–°и®Ўз®—дёўеӨұзҡ„еҲҶеҢәж•°жҚ®пјҢиҖҢдёҚжҳҜеҜ№RDDзҡ„жүҖжңүеҲҶеҢәиҝӣиЎҢйҮҚж–°и®Ўз®—гҖӮ(Sparkзҡ„е®№й”ҷжңәеҲ¶)
Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)пјҡ еҸҜйҖүйЎ№пјҢеҜ№дәҺKVзұ»еһӢзҡ„RDDдјҡжңүдёҖдёӘPartitionerпјҢеҚіRDDзҡ„еҲҶеҢәеҮҪж•°пјҢй»ҳи®ӨдёәHashPartitionerгҖӮ
Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)пјҡ еҸҜйҖүйЎ№,дёҖдёӘеҲ—иЎЁпјҢеӯҳеӮЁеӯҳеҸ–жҜҸдёӘPartitionзҡ„дјҳе…ҲдҪҚзҪ®(preferred location)гҖӮ еҜ№дәҺдёҖдёӘHDFSж–Ү件жқҘиҜҙпјҢиҝҷдёӘеҲ—иЎЁдҝқеӯҳзҡ„е°ұжҳҜжҜҸдёӘPartitionжүҖеңЁзҡ„еқ—зҡ„дҪҚзҪ®гҖӮжҢүз…§"移еҠЁж•°жҚ®дёҚеҰӮ移еҠЁи®Ўз®—"зҡ„зҗҶеҝөпјҢSparkеңЁиҝӣиЎҢд»»еҠЎи°ғеәҰзҡ„ж—¶еҖҷпјҢдјҡе°ҪеҸҜиғҪйҖүжӢ©йӮЈдәӣеӯҳжңүж•°жҚ®зҡ„workerиҠӮзӮ№жқҘиҝӣиЎҢд»»еҠЎи®Ўз®—гҖӮ
RDD жҳҜдёҖдёӘж•°жҚ®йӣҶзҡ„иЎЁзӨәпјҢдёҚд»…иЎЁзӨәдәҶж•°жҚ®йӣҶпјҢиҝҳиЎЁзӨәдәҶиҝҷдёӘж•°жҚ®йӣҶд»Һе“ӘжқҘпјҢеҰӮдҪ•и®Ўз®—пјҢдё»иҰҒеұһжҖ§еҢ…жӢ¬пјҡ
еҲҶеҢәеҲ—иЎЁ
и®Ўз®—еҮҪж•°
дҫқиө–е…ізі»
еҲҶеҢәеҮҪж•°(й»ҳи®ӨжҳҜhash)
жңҖдҪідҪҚзҪ®
еҲҶеҢәеҲ—иЎЁгҖҒеҲҶеҢәеҮҪж•°гҖҒжңҖдҪідҪҚзҪ®пјҢиҝҷдёүдёӘеұһжҖ§е…¶е®һиҜҙзҡ„е°ұжҳҜж•°жҚ®йӣҶеңЁе“ӘпјҢеңЁе“Әи®Ўз®—жӣҙеҗҲйҖӮпјҢеҰӮдҪ•еҲҶеҢәпјӣ
и®Ўз®—еҮҪж•°гҖҒдҫқиө–е…ізі»пјҢиҝҷдёӨдёӘеұһжҖ§е…¶е®һиҜҙзҡ„жҳҜж•°жҚ®йӣҶжҖҺд№ҲжқҘзҡ„гҖӮ
дәҢгҖҒRDD-API
1. RDDзҡ„еҲӣе»әж–№ејҸ
з”ұеӨ–йғЁеӯҳеӮЁзі»з»ҹзҡ„ж•°жҚ®йӣҶеҲӣе»әпјҢеҢ…жӢ¬жң¬ең°зҡ„ж–Ү件系з»ҹпјҢиҝҳжңүжүҖжңүHadoopж”ҜжҢҒзҡ„ж•°жҚ®йӣҶпјҢжҜ”еҰӮHDFSгҖҒCassandraгҖҒHBaseзӯүпјҡ
val rdd1 = sc.textFile("hdfs://node1:8020/wordcount/input/words.txt")
йҖҡиҝҮе·Іжңүзҡ„RDDз»ҸиҝҮз®—еӯҗиҪ¬жҚўз”ҹжҲҗж–°зҡ„RDDпјҡ
val rdd2=rdd1.flatMap(_.split(" "))
з”ұдёҖдёӘе·Із»ҸеӯҳеңЁзҡ„ScalaйӣҶеҗҲеҲӣе»әпјҡ
val rdd3 = sc.parallelize(Array(1,2,3,4,5,6,7,8)) жҲ–иҖ…
val rdd4 = sc.makeRDD(List(1,2,3,4,5,6,7,8))
makeRDDж–№жі•еә•еұӮи°ғз”ЁдәҶparallelizeж–№жі•пјҡ

2. RDDзҡ„з®—еӯҗеҲҶзұ»
RDDзҡ„з®—еӯҗеҲҶдёәдёӨзұ»:
TransformationиҪ¬жҚўж“ҚдҪң:иҝ”еӣһдёҖдёӘж–°зҡ„RDD
ActionеҠЁдҪңж“ҚдҪң:иҝ”еӣһеҖјдёҚжҳҜRDD(ж— иҝ”еӣһеҖјжҲ–иҝ”еӣһе…¶д»–зҡ„)
вқЈпёҸжіЁж„Ҹ:
1гҖҒRDDдёҚе®һйҷ…еӯҳеӮЁзңҹжӯЈиҰҒи®Ўз®—зҡ„ж•°жҚ®пјҢиҖҢжҳҜи®°еҪ•дәҶж•°жҚ®зҡ„дҪҚзҪ®еңЁе“ӘйҮҢпјҢж•°жҚ®зҡ„иҪ¬жҚўе…ізі»(и°ғз”ЁдәҶд»Җд№Ҳж–№жі•пјҢдј е…Ҙд»Җд№ҲеҮҪж•°)гҖӮ
2гҖҒRDDдёӯзҡ„жүҖжңүиҪ¬жҚўйғҪжҳҜжғ°жҖ§жұӮеҖј/延иҝҹжү§иЎҢзҡ„пјҢд№ҹе°ұжҳҜиҜҙ并дёҚдјҡзӣҙжҺҘи®Ўз®—гҖӮеҸӘжңүеҪ“еҸ‘з”ҹдёҖдёӘиҰҒжұӮиҝ”еӣһз»“жһңз»ҷDriverзҡ„ActionеҠЁдҪңж—¶пјҢиҝҷдәӣиҪ¬жҚўжүҚдјҡзңҹжӯЈиҝҗиЎҢгҖӮ
3гҖҒд№ӢжүҖд»ҘдҪҝз”Ёжғ°жҖ§жұӮеҖј/延иҝҹжү§иЎҢпјҢжҳҜеӣ дёәиҝҷж ·еҸҜд»ҘеңЁActionж—¶еҜ№RDDж“ҚдҪңеҪўжҲҗDAGжңүеҗ‘ж— зҺҜеӣҫиҝӣиЎҢStageзҡ„еҲ’еҲҶе’Ң并иЎҢдјҳеҢ–пјҢиҝҷз§Қи®ҫи®Ўи®©SparkжӣҙеҠ жңүж•ҲзҺҮең°иҝҗиЎҢгҖӮ
3. TransformationиҪ¬жҚўз®—еӯҗ
| иҪ¬жҚўз®—еӯҗ | еҗ«д№ү |
|---|
| map(func) | иҝ”еӣһдёҖдёӘж–°зҡ„RDDпјҢиҜҘRDDз”ұжҜҸдёҖдёӘиҫ“е…Ҙе…ғзҙ з»ҸиҝҮfuncеҮҪж•°иҪ¬жҚўеҗҺз»„жҲҗ |
| filter(func) | иҝ”еӣһдёҖдёӘж–°зҡ„RDDпјҢиҜҘRDDз”ұз»ҸиҝҮfuncеҮҪж•°и®Ўз®—еҗҺиҝ”еӣһеҖјдёәtrueзҡ„иҫ“е…Ҙе…ғзҙ з»„жҲҗ |
| flatMap(func) | зұ»дјјдәҺmapпјҢдҪҶжҳҜжҜҸдёҖдёӘиҫ“е…Ҙе…ғзҙ еҸҜд»Ҙиў«жҳ е°„дёә0жҲ–еӨҡдёӘиҫ“еҮәе…ғзҙ (жүҖд»Ҙfuncеә”иҜҘиҝ”еӣһдёҖдёӘеәҸеҲ—пјҢиҖҢдёҚжҳҜеҚ•дёҖе…ғзҙ ) |
| mapPartitions(func) | зұ»дјјдәҺmapпјҢдҪҶзӢ¬з«Ӣең°еңЁRDDзҡ„жҜҸдёҖдёӘеҲҶзүҮдёҠиҝҗиЎҢпјҢеӣ жӯӨеңЁзұ»еһӢдёәTзҡ„RDDдёҠиҝҗиЎҢж—¶пјҢfuncзҡ„еҮҪж•°зұ»еһӢеҝ…йЎ»жҳҜIterator[T] => Iterator[U] |
| mapPartitionsWithIndex(func) | зұ»дјјдәҺmapPartitionsпјҢдҪҶfuncеёҰжңүдёҖдёӘж•ҙж•°еҸӮж•°иЎЁзӨәеҲҶзүҮзҡ„зҙўеј•еҖјпјҢеӣ жӯӨеңЁзұ»еһӢдёәTзҡ„RDDдёҠиҝҗиЎҢж—¶пјҢfuncзҡ„еҮҪж•°зұ»еһӢеҝ…йЎ»жҳҜ(Int, Interator[T]) => Iterator[U] |
| sample(withReplacement, fraction, seed) | ж №жҚ®fractionжҢҮе®ҡзҡ„жҜ”дҫӢеҜ№ж•°жҚ®иҝӣиЎҢйҮҮж ·пјҢеҸҜд»ҘйҖүжӢ©жҳҜеҗҰдҪҝз”ЁйҡҸжңәж•°иҝӣиЎҢжӣҝжҚўпјҢseedз”ЁдәҺжҢҮе®ҡйҡҸжңәж•°з”ҹжҲҗеҷЁз§Қеӯҗ |
| union(otherDataset) | еҜ№жәҗRDDе’ҢеҸӮж•°RDDжұӮ并йӣҶеҗҺиҝ”еӣһдёҖдёӘж–°зҡ„RDD |
| intersection(otherDataset) | еҜ№жәҗRDDе’ҢеҸӮж•°RDDжұӮдәӨйӣҶеҗҺиҝ”еӣһдёҖдёӘж–°зҡ„RDD |
| distinct([numTasks])) | еҜ№жәҗRDDиҝӣиЎҢеҺ»йҮҚеҗҺиҝ”еӣһдёҖдёӘж–°зҡ„RDD |
| groupByKey([numTasks]) | еңЁдёҖдёӘ(K,V)зҡ„RDDдёҠи°ғз”ЁпјҢиҝ”еӣһдёҖдёӘ(K, Iterator[V])зҡ„RDD |
| reduceByKey(func, [numTasks]) | еңЁдёҖдёӘ(K,V)зҡ„RDDдёҠи°ғз”ЁпјҢиҝ”еӣһдёҖдёӘ(K,V)зҡ„RDDпјҢдҪҝз”ЁжҢҮе®ҡзҡ„reduceеҮҪж•°пјҢе°ҶзӣёеҗҢkeyзҡ„еҖјиҒҡеҗҲеҲ°дёҖиө·пјҢдёҺgroupByKeyзұ»дјјпјҢreduceд»»еҠЎзҡ„дёӘж•°еҸҜд»ҘйҖҡиҝҮ第дәҢдёӘеҸҜйҖүзҡ„еҸӮж•°жқҘи®ҫзҪ® |
| aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) | еҜ№PairRDDдёӯзӣёеҗҢзҡ„KeyеҖјиҝӣиЎҢиҒҡеҗҲж“ҚдҪңпјҢеңЁиҒҡеҗҲиҝҮзЁӢдёӯеҗҢж ·дҪҝз”ЁдәҶдёҖдёӘдёӯз«Ӣзҡ„еҲқе§ӢеҖјгҖӮе’ҢaggregateеҮҪж•°зұ»дјјпјҢaggregateByKeyиҝ”еӣһеҖјзҡ„зұ»еһӢдёҚйңҖиҰҒе’ҢRDDдёӯvalueзҡ„зұ»еһӢдёҖиҮҙ |
| sortByKey([ascending], [numTasks]) | еңЁдёҖдёӘ(K,V)зҡ„RDDдёҠи°ғз”ЁпјҢKеҝ…йЎ»е®һзҺ°OrderedжҺҘеҸЈпјҢиҝ”еӣһдёҖдёӘжҢүз…§keyиҝӣиЎҢжҺ’еәҸзҡ„(K,V)зҡ„RDD |
| sortBy(func,[ascending], [numTasks]) | дёҺsortByKeyзұ»дјјпјҢдҪҶжҳҜжӣҙзҒөжҙ» |
| join(otherDataset, [numTasks]) | еңЁзұ»еһӢдёә(K,V)е’Ң(K,W)зҡ„RDDдёҠи°ғз”ЁпјҢиҝ”еӣһдёҖдёӘзӣёеҗҢkeyеҜ№еә”зҡ„жүҖжңүе…ғзҙ еҜ№еңЁдёҖиө·зҡ„(K,(V,W))зҡ„RDD |
| cogroup(otherDataset, [numTasks]) | еңЁзұ»еһӢдёә(K,V)е’Ң(K,W)зҡ„RDDдёҠи°ғз”ЁпјҢиҝ”еӣһдёҖдёӘ(K,(Iterable<V>,Iterable<W>))зұ»еһӢзҡ„RDD |
| cartesian(otherDataset) | з¬ӣеҚЎе°”з§Ҝ |
| pipe(command, [envVars]) | еҜ№rddиҝӣиЎҢз®ЎйҒ“ж“ҚдҪң |
| coalesce(numPartitions) | еҮҸе°‘ RDD зҡ„еҲҶеҢәж•°еҲ°жҢҮе®ҡеҖјгҖӮеңЁиҝҮж»ӨеӨ§йҮҸж•°жҚ®д№ӢеҗҺпјҢеҸҜд»Ҙжү§иЎҢжӯӨж“ҚдҪң |
| repartition(numPartitions) | йҮҚж–°з»ҷ RDD еҲҶеҢә |
4. ActionеҠЁдҪңз®—еӯҗ
| еҠЁдҪңз®—еӯҗ | еҗ«д№ү |
|---|
| reduce(func) | йҖҡиҝҮfuncеҮҪж•°иҒҡйӣҶRDDдёӯзҡ„жүҖжңүе…ғзҙ пјҢиҝҷдёӘеҠҹиғҪеҝ…йЎ»жҳҜеҸҜдәӨжҚўдё”еҸҜ并иҒ”зҡ„ |
| collect() | еңЁй©ұеҠЁзЁӢеәҸдёӯпјҢд»Ҙж•°з»„зҡ„еҪўејҸиҝ”еӣһж•°жҚ®йӣҶзҡ„жүҖжңүе…ғзҙ |
| count() | иҝ”еӣһRDDзҡ„е…ғзҙ дёӘж•° |
| first() | иҝ”еӣһRDDзҡ„第дёҖдёӘе…ғзҙ (зұ»дјјдәҺtake(1)) |
| take(n) | иҝ”еӣһдёҖдёӘз”ұж•°жҚ®йӣҶзҡ„еүҚnдёӘе…ғзҙ з»„жҲҗзҡ„ж•°з»„ |
| takeSample(withReplacement,num, [seed]) | иҝ”еӣһдёҖдёӘж•°з»„пјҢиҜҘж•°з»„з”ұд»Һж•°жҚ®йӣҶдёӯйҡҸжңәйҮҮж ·зҡ„numдёӘе…ғзҙ з»„жҲҗпјҢеҸҜд»ҘйҖүжӢ©жҳҜеҗҰз”ЁйҡҸжңәж•°жӣҝжҚўдёҚи¶ізҡ„йғЁеҲҶпјҢseedз”ЁдәҺжҢҮе®ҡйҡҸжңәж•°з”ҹжҲҗеҷЁз§Қеӯҗ |
| takeOrdered(n, [ordering]) | иҝ”еӣһиҮӘ然йЎәеәҸжҲ–иҖ…иҮӘе®ҡд№үйЎәеәҸзҡ„еүҚ n дёӘе…ғзҙ |
| saveAsTextFile(path) | е°Ҷж•°жҚ®йӣҶзҡ„е…ғзҙ д»Ҙtextfileзҡ„еҪўејҸдҝқеӯҳеҲ°HDFSж–Ү件系з»ҹжҲ–иҖ…е…¶д»–ж”ҜжҢҒзҡ„ж–Ү件系з»ҹпјҢеҜ№дәҺжҜҸдёӘе…ғзҙ пјҢSparkе°Ҷдјҡи°ғз”ЁtoStringж–№жі•пјҢе°Ҷе®ғиЈ…жҚўдёәж–Ү件дёӯзҡ„ж–Үжң¬ |
| saveAsSequenceFile(path) | е°Ҷж•°жҚ®йӣҶдёӯзҡ„е…ғзҙ д»ҘHadoop sequencefileзҡ„ж јејҸдҝқеӯҳеҲ°жҢҮе®ҡзҡ„зӣ®еҪ•дёӢпјҢеҸҜд»ҘдҪҝHDFSжҲ–иҖ…е…¶д»–Hadoopж”ҜжҢҒзҡ„ж–Ү件系з»ҹ |
| saveAsObjectFile(path) | е°Ҷж•°жҚ®йӣҶзҡ„е…ғзҙ пјҢд»Ҙ Java еәҸеҲ—еҢ–зҡ„ж–№ејҸдҝқеӯҳеҲ°жҢҮе®ҡзҡ„зӣ®еҪ•дёӢ |
| countByKey() | й’ҲеҜ№(K,V)зұ»еһӢзҡ„RDDпјҢиҝ”еӣһдёҖдёӘ(K,Int)зҡ„mapпјҢиЎЁзӨәжҜҸдёҖдёӘkeyеҜ№еә”зҡ„е…ғзҙ дёӘж•° |
| foreach(func) | еңЁж•°жҚ®йӣҶзҡ„жҜҸдёҖдёӘе…ғзҙ дёҠпјҢиҝҗиЎҢеҮҪж•°funcиҝӣиЎҢжӣҙж–° |
| foreachPartition(func) | еңЁж•°жҚ®йӣҶзҡ„жҜҸдёҖдёӘеҲҶеҢәдёҠпјҢиҝҗиЎҢеҮҪж•°func |
з»ҹи®Ўж“ҚдҪңпјҡ
| з®—еӯҗ | еҗ«д№ү |
|---|
| count | дёӘж•° |
| mean | еқҮеҖј |
| sum | жұӮе’Ң |
| max | жңҖеӨ§еҖј |
| min | жңҖе°ҸеҖј |
| variance | ж–№е·® |
| sampleVariance | д»ҺйҮҮж ·дёӯи®Ўз®—ж–№е·® |
| stdev | ж ҮеҮҶе·®:иЎЎйҮҸж•°жҚ®зҡ„зҰ»ж•ЈзЁӢеәҰ |
| sampleStdev | йҮҮж ·зҡ„ж ҮеҮҶе·® |
| stats | жҹҘзңӢз»ҹи®Ўз»“жһң |
дёүгҖҒRDDзҡ„жҢҒд№…еҢ–/зј“еӯҳ
еңЁе®һйҷ…ејҖеҸ‘дёӯжҹҗдәӣRDDзҡ„и®Ўз®—жҲ–иҪ¬жҚўеҸҜиғҪдјҡжҜ”иҫғиҖ—иҙ№ж—¶й—ҙпјҢеҰӮжһңиҝҷдәӣRDDеҗҺз»ӯиҝҳдјҡйў‘з№Ғзҡ„иў«дҪҝз”ЁеҲ°пјҢйӮЈд№ҲеҸҜд»Ҙе°ҶиҝҷдәӣRDDиҝӣиЎҢжҢҒд№…еҢ–/зј“еӯҳпјҢиҝҷж ·дёӢж¬ЎеҶҚдҪҝз”ЁеҲ°зҡ„ж—¶еҖҷе°ұдёҚз”ЁеҶҚйҮҚж–°и®Ўз®—дәҶпјҢжҸҗй«ҳдәҶзЁӢеәҸиҝҗиЎҢзҡ„ж•ҲзҺҮгҖӮ
val rdd1 = sc.textFile("hdfs://node01:8020/words.txt")
val rdd2 = rdd1.flatMap(x=>x.split(" ")).map((_,1)).reduceByKey(_+_)
rdd2.cache //зј“еӯҳ/жҢҒд№…еҢ–
rdd2.sortBy(_._2,false).collect//и§ҰеҸ‘action,дјҡеҺ»иҜ»еҸ–HDFSзҡ„ж–Ү件,rdd2дјҡзңҹжӯЈжү§иЎҢжҢҒд№…еҢ–
rdd2.sortBy(_._2,false).collect//и§ҰеҸ‘action,дјҡеҺ»иҜ»зј“еӯҳдёӯзҡ„ж•°жҚ®,жү§иЎҢйҖҹеәҰдјҡжҜ”д№ӢеүҚеҝ«,еӣ дёәrdd2е·Із»ҸжҢҒд№…еҢ–еҲ°еҶ…еӯҳдёӯдәҶжҢҒд№…еҢ–/зј“еӯҳAPIиҜҰи§Ј
RDDйҖҡиҝҮpersistжҲ–cacheж–№жі•еҸҜд»Ҙе°ҶеүҚйқўзҡ„и®Ўз®—з»“жһңзј“еӯҳпјҢдҪҶжҳҜ并дёҚжҳҜиҝҷдёӨдёӘж–№жі•иў«и°ғз”Ёж—¶з«ӢеҚізј“еӯҳпјҢиҖҢжҳҜи§ҰеҸ‘еҗҺйқўзҡ„actionж—¶пјҢиҜҘRDDе°Ҷдјҡиў«зј“еӯҳеңЁи®Ўз®—иҠӮзӮ№зҡ„еҶ…еӯҳдёӯпјҢ并дҫӣеҗҺйқўйҮҚз”ЁгҖӮ
йҖҡиҝҮжҹҘзңӢRDDзҡ„жәҗз ҒеҸ‘зҺ°cacheжңҖз»Ҳд№ҹжҳҜи°ғз”ЁдәҶpersistж— еҸӮж–№жі•(й»ҳи®ӨеӯҳеӮЁеҸӘеӯҳеңЁеҶ…еӯҳдёӯ)пјҡ

й»ҳи®Өзҡ„еӯҳеӮЁзә§еҲ«йғҪжҳҜд»…еңЁеҶ…еӯҳеӯҳеӮЁдёҖд»ҪпјҢSparkзҡ„еӯҳеӮЁзә§еҲ«иҝҳжңүеҘҪеӨҡз§ҚпјҢеӯҳеӮЁзә§еҲ«еңЁobject StorageLevelдёӯе®ҡд№үзҡ„гҖӮ
| жҢҒд№…еҢ–зә§еҲ« | иҜҙжҳҺ |
|---|
| MORY_ONLY(й»ҳи®Ө) | е°ҶRDDд»ҘйқһеәҸеҲ—еҢ–зҡ„JavaеҜ№иұЎеӯҳеӮЁеңЁJVMдёӯгҖӮ еҰӮжһңжІЎжңүи¶іеӨҹзҡ„еҶ…еӯҳеӯҳеӮЁRDDпјҢеҲҷжҹҗдәӣеҲҶеҢәе°ҶдёҚдјҡиў«зј“еӯҳпјҢжҜҸж¬ЎйңҖиҰҒж—¶йғҪдјҡйҮҚж–°и®Ўз®—гҖӮ иҝҷжҳҜй»ҳи®Өзә§еҲ« |
| MORY_AND_DISK(ејҖеҸ‘дёӯеҸҜд»ҘдҪҝз”ЁиҝҷдёӘ) | е°ҶRDDд»ҘйқһеәҸеҲ—еҢ–зҡ„JavaеҜ№иұЎеӯҳеӮЁеңЁJVMдёӯгҖӮеҰӮжһңж•°жҚ®еңЁеҶ…еӯҳдёӯж”ҫдёҚдёӢпјҢеҲҷжәўеҶҷеҲ°зЈҒзӣҳдёҠпјҺйңҖиҰҒж—¶еҲҷдјҡд»ҺзЈҒзӣҳдёҠиҜ»еҸ– |
| MEMORY_ONLY_SER (Java and Scala) | е°ҶRDDд»ҘеәҸеҲ—еҢ–зҡ„JavaеҜ№иұЎ(жҜҸдёӘеҲҶеҢәдёҖдёӘеӯ—иҠӮж•°з»„)зҡ„ж–№ејҸеӯҳеӮЁпјҺиҝҷйҖҡеёёжҜ”йқһеәҸеҲ—еҢ–еҜ№иұЎ(deserialized objects)жӣҙе…·з©әй—ҙж•ҲзҺҮпјҢзү№еҲ«жҳҜеңЁдҪҝз”Ёеҝ«йҖҹеәҸеҲ—еҢ–зҡ„жғ…еҶөдёӢпјҢдҪҶжҳҜиҝҷз§Қж–№ејҸиҜ»еҸ–ж•°жҚ®дјҡж¶ҲиҖ—жӣҙеӨҡзҡ„CPU |
| MEMORY_AND_DISK_SER (Java and Scala) | дёҺMEMORY_ONLY_SERзұ»дјјпјҢдҪҶеҰӮжһңж•°жҚ®еңЁеҶ…еӯҳдёӯж”ҫдёҚдёӢпјҢеҲҷжәўеҶҷеҲ°зЈҒзӣҳдёҠпјҢиҖҢдёҚжҳҜжҜҸж¬ЎйңҖиҰҒйҮҚж–°и®Ўз®—е®ғ们 |
| DISK_ONLY | е°ҶRDDеҲҶеҢәеӯҳеӮЁеңЁзЈҒзӣҳдёҠ |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2зӯү | дёҺдёҠйқўзҡ„еӮЁеӯҳзә§еҲ«зӣёеҗҢпјҢеҸӘдёҚиҝҮе°ҶжҢҒд№…еҢ–ж•°жҚ®еӯҳдёәдёӨд»ҪпјҢеӨҮд»ҪжҜҸдёӘеҲҶеҢәеӯҳеӮЁеңЁдёӨдёӘйӣҶзҫӨиҠӮзӮ№дёҠ |
| OFF_HEAP(е®һйӘҢдёӯ) | дёҺMEMORY_ONLY_SERзұ»дјјпјҢдҪҶе°Ҷж•°жҚ®еӯҳеӮЁеңЁе ҶеӨ–еҶ…еӯҳдёӯгҖӮ (еҚідёҚжҳҜзӣҙжҺҘеӯҳеӮЁеңЁJVMеҶ…еӯҳдёӯ) |
жҖ»з»“пјҡ
RDDжҢҒд№…еҢ–/зј“еӯҳзҡ„зӣ®зҡ„жҳҜдёәдәҶжҸҗй«ҳеҗҺз»ӯж“ҚдҪңзҡ„йҖҹеәҰ
зј“еӯҳзҡ„зә§еҲ«жңүеҫҲеӨҡпјҢй»ҳи®ӨеҸӘеӯҳеңЁеҶ…еӯҳдёӯ,ејҖеҸ‘дёӯдҪҝз”Ёmemory_and_disk
еҸӘжңүжү§иЎҢactionж“ҚдҪңзҡ„ж—¶еҖҷжүҚдјҡзңҹжӯЈе°ҶRDDж•°жҚ®иҝӣиЎҢжҢҒд№…еҢ–/зј“еӯҳ
е®һйҷ…ејҖеҸ‘дёӯеҰӮжһңжҹҗдёҖдёӘRDDеҗҺз»ӯдјҡиў«йў‘з№Ғзҡ„дҪҝз”ЁпјҢеҸҜд»Ҙе°ҶиҜҘRDDиҝӣиЎҢжҢҒд№…еҢ–/зј“еӯҳ
еӣӣгҖҒRDDе®№й”ҷжңәеҲ¶Checkpoint
жҢҒд№…еҢ–/зј“еӯҳеҸҜд»ҘжҠҠж•°жҚ®ж”ҫеңЁеҶ…еӯҳдёӯпјҢиҷҪ然жҳҜеҝ«йҖҹзҡ„пјҢдҪҶжҳҜд№ҹжҳҜжңҖдёҚеҸҜйқ зҡ„пјӣд№ҹеҸҜд»ҘжҠҠж•°жҚ®ж”ҫеңЁзЈҒзӣҳдёҠпјҢд№ҹдёҚжҳҜе®Ңе…ЁеҸҜйқ зҡ„пјҒдҫӢеҰӮзЈҒзӣҳдјҡжҚҹеқҸзӯүгҖӮ
Checkpointзҡ„дә§з”ҹе°ұжҳҜдёәдәҶжӣҙеҠ еҸҜйқ зҡ„ж•°жҚ®жҢҒд№…еҢ–пјҢеңЁCheckpointзҡ„ж—¶еҖҷдёҖиҲ¬жҠҠж•°жҚ®ж”ҫеңЁеңЁHDFSдёҠпјҢиҝҷе°ұеӨ©з„¶зҡ„еҖҹеҠ©дәҶHDFSеӨ©з”ҹзҡ„й«ҳе®№й”ҷгҖҒй«ҳеҸҜйқ жқҘе®һзҺ°ж•°жҚ®жңҖеӨ§зЁӢеәҰдёҠзҡ„е®үе…ЁпјҢе®һзҺ°дәҶRDDзҡ„е®№й”ҷе’Ңй«ҳеҸҜз”ЁгҖӮ
з”Ёжі•пјҡ
SparkContext.setCheckpointDir("зӣ®еҪ•") //HDFSзҡ„зӣ®еҪ•
RDD.checkpointжҖ»з»“пјҡ
дҪҚзҪ®пјҡ Persist е’Ң Cache еҸӘиғҪдҝқеӯҳеңЁжң¬ең°зҡ„зЈҒзӣҳе’ҢеҶ…еӯҳдёӯ(жҲ–иҖ…е ҶеӨ–еҶ…еӯҳ--е®һйӘҢдёӯ) Checkpoint еҸҜд»Ҙдҝқеӯҳж•°жҚ®еҲ° HDFS иҝҷзұ»еҸҜйқ зҡ„еӯҳеӮЁдёҠгҖӮ
з”ҹе‘Ҫе‘Ёжңҹпјҡ Cacheе’ҢPersistзҡ„RDDдјҡеңЁзЁӢеәҸз»“жқҹеҗҺдјҡиў«жё…йҷӨжҲ–иҖ…жүӢеҠЁи°ғз”Ёunpersistж–№жі• Checkpointзҡ„RDDеңЁзЁӢеәҸз»“жқҹеҗҺдҫқ然еӯҳеңЁпјҢдёҚдјҡиў«еҲ йҷӨгҖӮ
дә”гҖҒRDDдҫқиө–е…ізі»
1. е®ҪзӘ„дҫқиө–

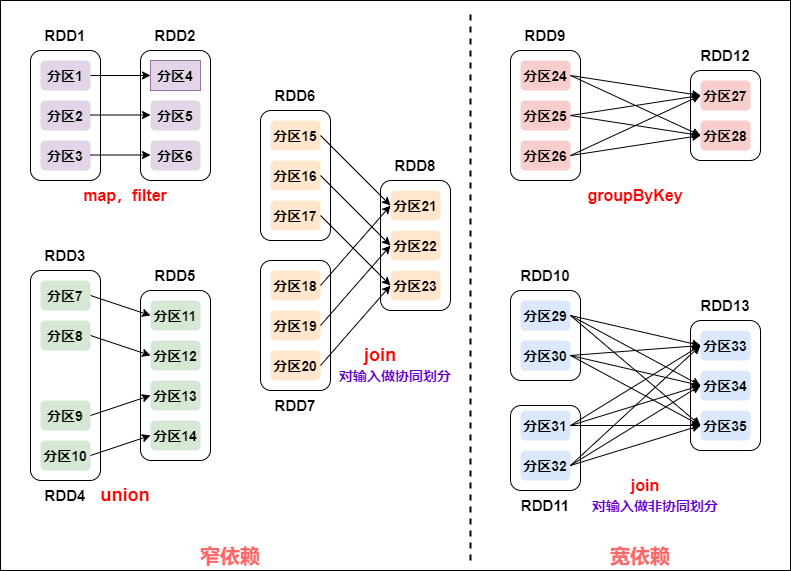
зӘ„дҫқиө–:зҲ¶RDDзҡ„дёҖдёӘеҲҶеҢәеҸӘдјҡиў«еӯҗRDDзҡ„дёҖдёӘеҲҶеҢәдҫқиө–пјӣ
е®Ҫдҫқиө–:зҲ¶RDDзҡ„дёҖдёӘеҲҶеҢәдјҡиў«еӯҗRDDзҡ„еӨҡдёӘеҲҶеҢәдҫқиө–(ж¶үеҸҠеҲ°shuffle)гҖӮ
2. дёәд»Җд№ҲиҰҒи®ҫи®Ўе®ҪзӘ„дҫқиө–
еҜ№дәҺзӘ„дҫқиө–пјҡ
зӘ„дҫқиө–зҡ„еӨҡдёӘеҲҶеҢәеҸҜд»Ҙ并иЎҢи®Ўз®—пјӣ
зӘ„дҫқиө–зҡ„дёҖдёӘеҲҶеҢәзҡ„ж•°жҚ®еҰӮжһңдёўеӨұеҸӘйңҖиҰҒйҮҚж–°и®Ўз®—еҜ№еә”зҡ„еҲҶеҢәзҡ„ж•°жҚ®е°ұеҸҜд»ҘдәҶгҖӮ
еҜ№дәҺе®Ҫдҫқиө–пјҡ
еҲ’еҲҶStage(йҳ¶ж®ө)зҡ„дҫқжҚ®:еҜ№дәҺе®Ҫдҫқиө–,еҝ…йЎ»зӯүеҲ°дёҠдёҖйҳ¶ж®өи®Ўз®—е®ҢжҲҗжүҚиғҪи®Ўз®—дёӢдёҖйҳ¶ж®өгҖӮ
е…ӯгҖҒDAGзҡ„з”ҹжҲҗе’ҢеҲ’еҲҶStage
1. DAGд»Ӣз»Қ
DAG(Directed Acyclic Graphжңүеҗ‘ж— зҺҜеӣҫ)жҢҮзҡ„жҳҜж•°жҚ®иҪ¬жҚўжү§иЎҢзҡ„иҝҮзЁӢпјҢжңүж–№еҗ‘пјҢж— й—ӯзҺҜ(е…¶е®һе°ұжҳҜRDDжү§иЎҢзҡ„жөҒзЁӢ)пјӣ
еҺҹе§Ӣзҡ„RDDйҖҡиҝҮдёҖзі»еҲ—зҡ„иҪ¬жҚўж“ҚдҪңе°ұеҪўжҲҗдәҶDAGжңүеҗ‘ж— зҺҜеӣҫпјҢд»»еҠЎжү§иЎҢж—¶пјҢеҸҜд»ҘжҢүз…§DAGзҡ„жҸҸиҝ°пјҢжү§иЎҢзңҹжӯЈзҡ„и®Ўз®—(ж•°жҚ®иў«ж“ҚдҪңзҡ„дёҖдёӘиҝҮзЁӢ)гҖӮ
ејҖе§Ӣ:йҖҡиҝҮSparkContextеҲӣе»әзҡ„RDDпјӣ
з»“жқҹ:и§ҰеҸ‘ActionпјҢдёҖж—Ұи§ҰеҸ‘Actionе°ұеҪўжҲҗдәҶдёҖдёӘе®Ңж•ҙзҡ„DAGгҖӮ
2.DAGеҲ’еҲҶStage
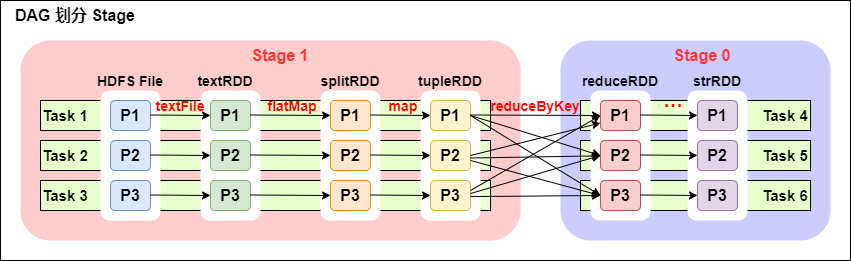
дёҖдёӘSparkзЁӢеәҸеҸҜд»ҘжңүеӨҡдёӘDAG(жңүеҮ дёӘActionпјҢе°ұжңүеҮ дёӘDAGпјҢдёҠеӣҫжңҖеҗҺеҸӘжңүдёҖдёӘActionпјҲеӣҫдёӯжңӘиЎЁзҺ°пјү,йӮЈд№Ҳе°ұжҳҜдёҖдёӘDAG)гҖӮ
дёҖдёӘDAGеҸҜд»ҘжңүеӨҡдёӘStage(ж №жҚ®е®Ҫдҫқиө–/shuffleиҝӣиЎҢеҲ’еҲҶ)гҖӮ
еҗҢдёҖдёӘStageеҸҜд»ҘжңүеӨҡдёӘTask并иЎҢжү§иЎҢ(taskж•°=еҲҶеҢәж•°пјҢеҰӮдёҠеӣҫпјҢStage1 дёӯжңүдёүдёӘеҲҶеҢәP1гҖҒP2гҖҒP3пјҢеҜ№еә”зҡ„д№ҹжңүдёүдёӘ Task)гҖӮ
еҸҜд»ҘзңӢеҲ°иҝҷдёӘDAGдёӯеҸӘreduceByKeyж“ҚдҪңжҳҜдёҖдёӘе®Ҫдҫқиө–пјҢSparkеҶ…ж ёдјҡд»ҘжӯӨдёәиҫ№з•Ңе°Ҷе…¶еүҚеҗҺеҲ’еҲҶжҲҗдёҚеҗҢзҡ„StageгҖӮ
еҗҢж—¶жҲ‘们еҸҜд»ҘжіЁж„ҸеҲ°пјҢеңЁеӣҫдёӯStage1дёӯпјҢд»ҺtextFileеҲ°flatMapеҲ°mapйғҪжҳҜзӘ„дҫқиө–пјҢиҝҷеҮ жӯҘж“ҚдҪңеҸҜд»ҘеҪўжҲҗдёҖдёӘжөҒж°ҙзәҝж“ҚдҪңпјҢйҖҡиҝҮflatMapж“ҚдҪңз”ҹжҲҗзҡ„partitionеҸҜд»ҘдёҚз”Ёзӯүеҫ…ж•ҙдёӘRDDи®Ўз®—з»“жқҹпјҢиҖҢжҳҜ继з»ӯиҝӣиЎҢmapж“ҚдҪңпјҢиҝҷж ·еӨ§еӨ§жҸҗй«ҳдәҶи®Ўз®—зҡ„ж•ҲзҺҮгҖӮ
дёҖдёӘеӨҚжқӮзҡ„дёҡеҠЎйҖ»иҫ‘еҰӮжһңжңүshuffleпјҢйӮЈд№Ҳе°ұж„Ҹе‘ізқҖеүҚйқўйҳ¶ж®өдә§з”ҹз»“жһңеҗҺпјҢжүҚиғҪжү§иЎҢдёӢдёҖдёӘйҳ¶ж®өпјҢеҚідёӢдёҖдёӘйҳ¶ж®өзҡ„и®Ўз®—иҰҒдҫқиө–дёҠдёҖдёӘйҳ¶ж®өзҡ„ж•°жҚ®гҖӮйӮЈд№ҲжҲ‘们жҢүз…§shuffleиҝӣиЎҢеҲ’еҲҶ(д№ҹе°ұжҳҜжҢүз…§е®Ҫдҫқиө–е°ұиЎҢеҲ’еҲҶ)пјҢе°ұеҸҜд»Ҙе°ҶдёҖдёӘDAGеҲ’еҲҶжҲҗеӨҡдёӘStage/йҳ¶ж®өпјҢеңЁеҗҢдёҖдёӘStageдёӯпјҢдјҡжңүеӨҡдёӘз®—еӯҗж“ҚдҪңпјҢеҸҜд»ҘеҪўжҲҗдёҖдёӘpipelineжөҒж°ҙзәҝпјҢжөҒж°ҙзәҝеҶ…зҡ„еӨҡдёӘе№іиЎҢзҡ„еҲҶеҢәеҸҜд»Ҙ并иЎҢжү§иЎҢгҖӮ
еҜ№дәҺзӘ„дҫқиө–пјҢpartitionзҡ„иҪ¬жҚўеӨ„зҗҶеңЁstageдёӯе®ҢжҲҗи®Ўз®—пјҢдёҚеҲ’еҲҶ(е°ҶзӘ„дҫқиө–е°ҪйҮҸж”ҫеңЁеңЁеҗҢдёҖдёӘstageдёӯпјҢеҸҜд»Ҙе®һзҺ°жөҒж°ҙзәҝи®Ўз®—)гҖӮ
еҜ№дәҺе®Ҫдҫқиө–пјҢз”ұдәҺжңүshuffleзҡ„еӯҳеңЁпјҢеҸӘиғҪеңЁзҲ¶RDDеӨ„зҗҶе®ҢжҲҗеҗҺпјҢжүҚиғҪејҖе§ӢжҺҘдёӢжқҘзҡ„и®Ўз®—пјҢд№ҹе°ұжҳҜиҜҙйңҖиҰҒиҰҒеҲ’еҲҶstageгҖӮ
Sparkдјҡж №жҚ®shuffle/е®Ҫдҫқиө–дҪҝз”ЁеӣһжәҜз®—жі•жқҘеҜ№DAGиҝӣиЎҢStageеҲ’еҲҶпјҢд»ҺеҗҺеҫҖеүҚпјҢйҒҮеҲ°е®Ҫдҫқиө–е°ұж–ӯејҖпјҢйҒҮеҲ°зӘ„дҫқиө–е°ұжҠҠеҪ“еүҚзҡ„RDDеҠ е…ҘеҲ°еҪ“еүҚзҡ„stage/йҳ¶ж®өдёӯгҖӮ
зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们еҜ№жҖҺд№Ҳз”Ёе®һдҫӢи§ЈжһҗSpark CoreжңүиҝӣдёҖжӯҘзҡ„дәҶи§Јеҗ—пјҹеҰӮжһңиҝҳжғідәҶи§ЈжӣҙеӨҡзҹҘиҜҶжҲ–иҖ…зӣёе…іеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеӨ§е®¶зҡ„ж”ҜжҢҒгҖӮ





