еҹәдәҺKubeSphere еңЁз”ҹдә§зҺҜеўғзҡ„ејҖеҸ‘дёҺйғЁзҪІе®һи·өжҳҜжҖҺж ·зҡ„
еҹәдәҺKubeSphere еңЁз”ҹдә§зҺҜеўғзҡ„ејҖеҸ‘дёҺйғЁзҪІе®һи·өжҳҜжҖҺж ·зҡ„пјҢй’ҲеҜ№иҝҷдёӘй—®йўҳпјҢиҝҷзҜҮж–Үз« иҜҰз»Ҷд»Ӣз»ҚдәҶзӣёеҜ№еә”зҡ„еҲҶжһҗе’Ңи§Јзӯ”пјҢеёҢжңӣеҸҜд»Ҙеё®еҠ©жӣҙеӨҡжғіи§ЈеҶіиҝҷдёӘй—®йўҳзҡ„е°ҸдјҷдјҙжүҫеҲ°жӣҙз®ҖеҚ•жҳ“иЎҢзҡ„ж–№жі•гҖӮ
иғҢжҷҜ
дёӯйҖҡзү©жөҒжҳҜеӣҪеҶ…дёҡеҠЎи§„жЁЎиҫғеӨ§пјҢ第дёҖж–№йҳөдёӯеҸ‘еұ•иҫғеҝ«зҡ„еҝ«йҖ’дјҒдёҡгҖӮ2019е№ҙпјҢдёӯйҖҡеҗ„зұ»зі»з»ҹдә§з”ҹзҡ„ж•°жҚ®жөҒд»Ҙдәҝи®ЎпјҢеҗ„зұ»зү©зҗҶжңәе’ҢиҷҡжӢҹжңәжҲҗеҚғдёҠдёҮпјҢеңЁзәҝеҫ®жңҚеҠЎжӣҙжҳҜж•°дёҚиғңж•°гҖӮеҰӮжӯӨеәһеӨ§зҡ„з®ЎзҗҶпјҢдҪҝеҫ—дёӯйҖҡдёҡеҠЎеҸ‘еұ•дёҚеҸҜжҢҒз»ӯпјҢеӣ жӯӨзқҖжүӢдә‘еҢ–ж”№йҖ гҖӮеңЁж”№йҖ иҝҮзЁӢдёӯпјҢдёӯйҖҡйҖүжӢ©дәҶ KubeSphere жқҘдҪңдёәдёӯйҖҡе®№еҷЁз®ЎзҗҶе№іеҸ° ZKE зҡ„е»әи®ҫж–№жЎҲгҖӮ
дёҡеҠЎзҺ°зҠ¶е’Ңдә”еӨ§йҡҫзӮ№
йҰ–е…ҲпјҢжҲ‘д»Ӣз»ҚдёҖдёӢжҲ‘们дёӯйҖҡзҡ„дёҡеҠЎзҺ°зҠ¶гҖӮ
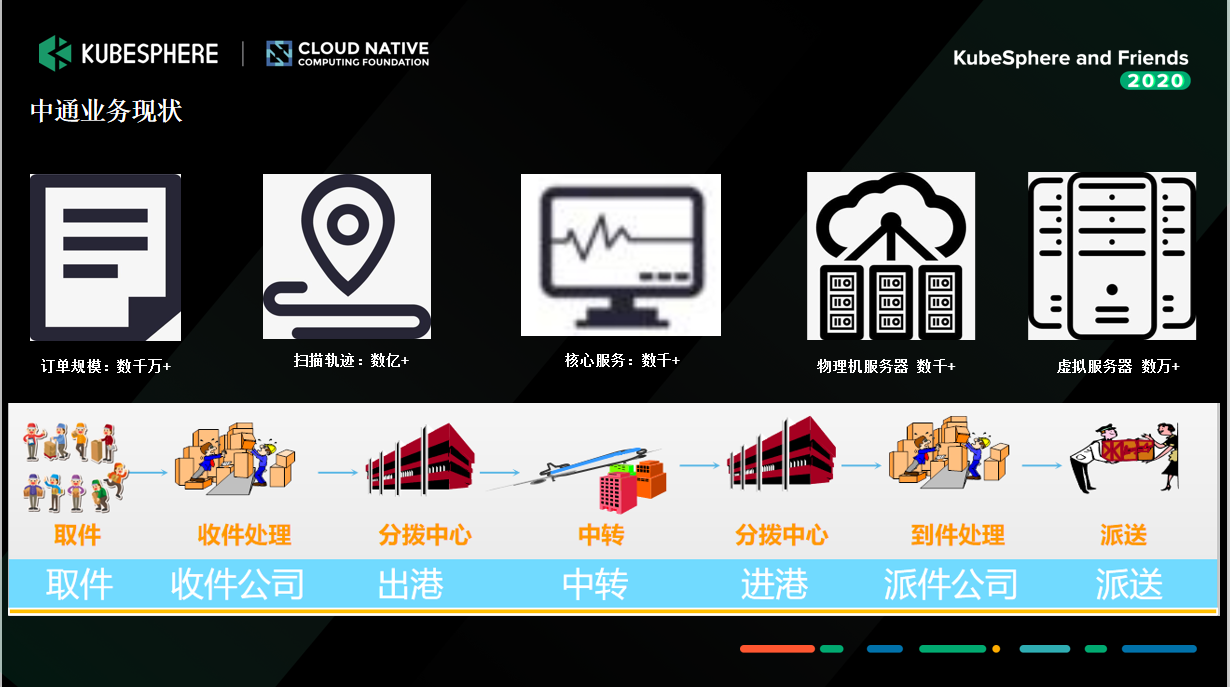
дёҠеӣҫжҳҜжҲ‘们 2019 е№ҙзҡ„ж•°жҚ®жғ…еҶөпјҢеҪ“жҲ‘们ејҖе§Ӣж”№йҖ ж—¶пјҢеҗ„зұ»зі»з»ҹдә§з”ҹзҡ„ж•°жҚ®жөҒд»Ҙдәҝи®ЎпјҢеҗ„зұ»зү©зҗҶжңәе’ҢиҷҡжӢҹжңәжӣҙжҳҜжҲҗеҚғдёҠдёҮпјҢеңЁзәҝеҫ®жңҚеҠЎжӣҙжҳҜж•°дёҚиғңж•°гҖӮжҲӘжӯўеҲ° 2020 е№ҙ第дёүеӯЈеәҰпјҢдёӯйҖҡеҝ«йҖ’зҡ„еёӮеңәд»Ҫйўқе·Іжү©еӨ§иҮі 20.8%пјҢеҹәжң¬дёҠжҳҜиЎҢдёҡйўҶе…ҲгҖӮиҝҷд№ҲеәһеӨ§зҡ„з®ЎзҗҶпјҢйҡҸзқҖдёӯйҖҡдёҡеҠЎзҡ„еҸ‘еұ•еҹәжң¬дёҠжҳҜдёҚеҸҜжҢҒз»ӯдәҶпјҢжүҖд»ҘжҲ‘们дәҹйңҖж”№йҖ гҖӮ
2019 е№ҙжҲ‘们йқўдёҙзҡ„еӣ°йҡҫеӨ§иҮҙжңүд»ҘдёӢдә”зӮ№пјҡ
1.еҗҢйЎ№зӣ®еӨҡзүҲжң¬еӨҡзҺҜеўғйңҖжұӮ
жҲ‘们项зӣ®еңЁиҝӯд»Јж—¶пјҢеңЁеҗҢдёҖдёӘйЎ№зӣ®е®ғе·Із»Ҹжңү N еӨҡдёӘзүҲжң¬еңЁжҺЁиҝӣгҖӮеҰӮжһңд»Қд»Ҙиҷҡжңәзҡ„ж–№ејҸжқҘе“Қеә”иө„жәҗпјҢе·Із»Ҹи·ҹдёҚдёҠйңҖжұӮдәҶгҖӮ
2.йЎ№зӣ®иҝӯд»ЈйҖҹеәҰиҰҒжұӮеҝ«йҖҹеҲқе§ӢеҢ–зҺҜеўғйңҖжұӮ
жҲ‘们зҡ„зүҲжң¬иҝӯд»ЈйҖҹеәҰйқһеёёеҝ«пјҢеҝ«еҲ°з”ҡиҮіжҳҜдёҖе‘ЁдёҖиҝӯд»ЈгҖӮ
3.иө„жәҗз”іиҜ·йә»зғҰпјҢзҺҜеўғеҲқе§ӢеҢ–еӨҚжқӮ
2019 е№ҙж—¶пјҢжҲ‘们申иҜ·иө„жәҗзҡ„ж–№ејҸиҝҳжҜ”иҫғдј з»ҹпјҢиө°е·ҘеҚ•пјҢжҗһзҺҜеўғеҲқе§ӢеҢ–зҡ„дәӨд»ҳгҖӮжүҖд»ҘжөӢиҜ•дәәе‘ҳеңЁжөӢиҜ•ж—¶йқһеёёз—ӣиӢҰпјҢиҰҒе…Ҳз”іиҜ·иө„жәҗпјҢжөӢиҜ•е®ҢеҗҺиҝҳиҰҒйҮҠж”ҫгҖӮ
4.зҺ°жңүиҷҡжңәиө„жәҗеҲ©з”ЁзҺҮдҪҺпјҢеғөе°ёжңәеӨҡ
жңүзҡ„иө„жәҗйҡҸзқҖдәәе‘ҳзҡ„еҸҳеҠЁжҲ–иҖ…еІ—дҪҚзҡ„еҸҳеҠЁпјҢеҸҳжҲҗдәҶеғөе°ёжңәпјҢж•°йҮҸйқһеёёеӨҡпјҢе°Өе…¶жҳҜеңЁејҖеҸ‘жөӢиҜ•зҺҜеўғгҖӮ
5.жЁӘеҗ‘жү©еұ•е·®
жҲ‘们еңЁвҖң618вҖқжҲ–иҖ…вҖңеҸҢ11вҖқзҡ„ж—¶еҖҷпјҢиө„жәҗжҳҜйқһеёёзЁҖзјәзҡ„пјҢзү№еҲ«жҳҜе…ій”®ж ёеҝғзҡ„жңҚеҠЎпјҢд№ӢеүҚзҡ„еҒҡжі•жҳҜжҸҗеүҚеҮҶеӨҮеҘҪиө„жәҗпјҢвҖң618вҖқжҲ–иҖ…вҖңеҸҢ11вҖқз»“жқҹд№ӢеҗҺпјҢжҲ‘们еҶҚжҠҠиө„жәҗеӣһ收гҖӮиҝҷе…¶е®һжҳҜдёҖдёӘйқһеёёиҗҪеҗҺзҡ„ж–№ејҸгҖӮ
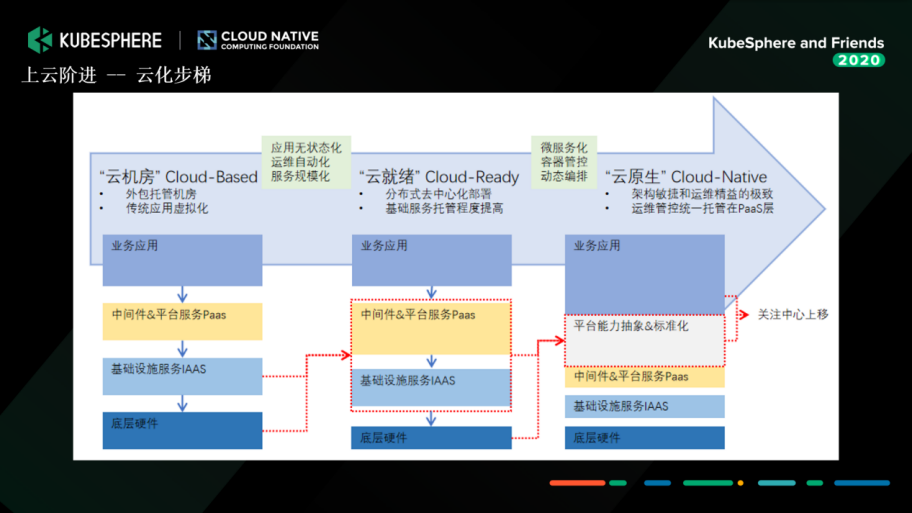
еҰӮдҪ•иҝӣиЎҢдә‘еҢ–ж”№йҖ пјҹ
йҖҡиҝҮи°ғжҹҘпјҢжҲ‘们и®Өдёәдә‘еҢ–ж”№йҖ еҸҜд»ҘеҲҶдёәдёүжӯҘпјҡдә‘жңәжҲҝгҖҒдә‘е°ұз»Әе’Ңдә‘еҺҹз”ҹгҖӮ
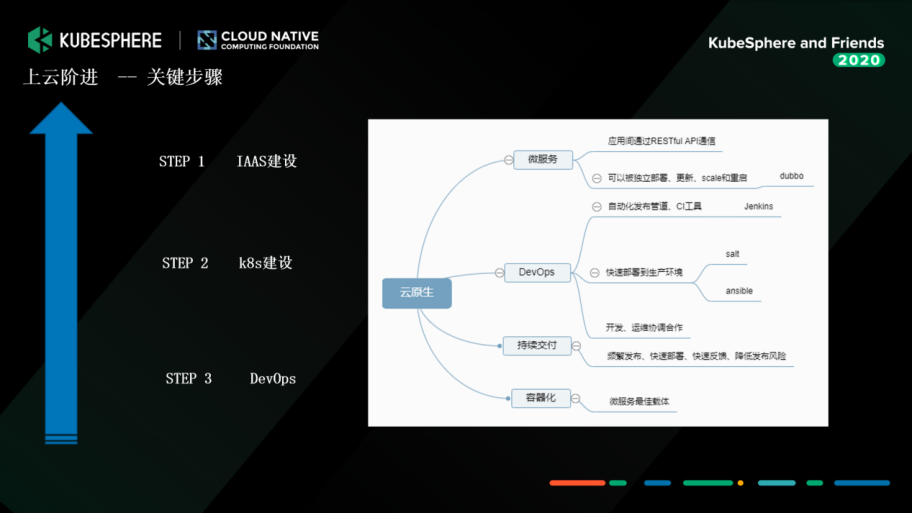
еҪ“ж—¶жҲ‘们зҡ„еҫ®жңҚеҠЎеҒҡзҡ„жҜ”иҫғйқ еүҚпјҢз”ЁдәҶ Dubbo жЎҶжһ¶пјҢеҫ®жңҚеҠЎж”№йҖ е·Із»Ҹе®ҢжҲҗпјҢдҪҶж–№ејҸйқһеёёдј з»ҹпјҢжҳҜйҖҡиҝҮиҷҡжңәзҡ„ж–№ејҸеҸ‘еҠЁгҖӮиҖҢ Salt еңЁеӨ§йҮҸ并еҸ‘зҡ„ж—¶еҖҷжңүеҫҲеӨҡй—®йўҳгҖӮжүҖд»ҘйҖҡиҝҮиҜ„дј°пјҢжҲ‘们дәҹйңҖеҜ№ IaaS е’Ңе®№еҷЁиҝӣиЎҢж”№йҖ гҖӮ
еӣ дёәжҲ‘们д»Ӣе…Ҙзҡ„ж—¶еҖҷпјҢдёӯйҖҡж•ҙдёӘдёҡеҠЎзҡ„ејҖеҸ‘е·Із»ҸйқһеёёеӨҡгҖҒйқһеёёеәһеӨ§дәҶгҖӮжҲ‘们жңүдёҖдёӘйқһеёёжҲҗзҶҹзҡ„ DevOps еӣўйҳҹпјҢжҠҠеҸ‘еёғзҡ„ CI/CD зҡ„йңҖжұӮеҒҡеҫ—йқһеёёе®Ңе–„гҖӮжүҖд»ҘжҲ‘们д»Ӣе…Ҙзҡ„иҜқеҸӘиғҪеҒҡ IaaS е’Ң Kubernetes зҡ„е»әи®ҫгҖӮ
KubeSphere ејҖеҸ‘йғЁзҪІе®һи·ө
дёәдҪ•йҖүжӢ© KubeSphere
еңЁйҖүеһӢзҡ„ж—¶еҖҷпјҢжҲ‘们йҰ–е…ҲжҺҘи§Ұзҡ„е°ұжҳҜ KubeSphereгҖӮеҪ“ж—¶жҲ‘йҖҡиҝҮжЈҖзҙўеҸ‘зҺ°дәҶ KubeSphereпјҢ然еҗҺиҝӣиЎҢиҜ•з”ЁпјҢеҸ‘зҺ°з•Ңйқўе’ҢдҪ“йӘҢзӯүж–№йқўйғҪйқһеёёжЈ’гҖӮиҜ•з”ЁдёҖе‘Ёд№ӢеҗҺпјҢжҲ‘们е°ұеҶіе®ҡпјҢдҪҝз”Ё KubeSphere дҪңдёәдёӯйҖҡе®№еҷЁз®ЎзҗҶе№іеҸ° ZKE зҡ„е»әи®ҫж–№жЎҲгҖӮжҲ‘еҚ°иұЎдёӯжҲ‘们еҪ“ж—¶д»Һ KubeSphere 2.0 зүҲжң¬е°ұејҖе§ӢйҮҮз”ЁдәҶгҖӮеҗҢж—¶пјҢеңЁ KubeSphere зҡ„еҪұе“Қд№ӢдёӢпјҢжҲ‘们еҫҲеҝ«е°ұи·ҹйқ’дә‘иҫҫжҲҗеҗҲдҪңеҚҸи®®пјҢзӣҙжҺҘдҪҝз”Ёйқ’дә‘зҡ„з§Ғжңүдә‘дә§е“ҒжқҘе»әи®ҫдёӯйҖҡзү©жөҒзҡ„ IaaSпјҢиҖҢ KubeSphere дҪңдёәдёҠеұӮзҡ„е®№еҷЁ PaaS е№іеҸ°жүҝиҪҪеҫ®жңҚеҠЎиҝҗиЎҢгҖӮ
е»әи®ҫж–№еҗ‘
еҹәдәҺеҪ“ж—¶зҡ„зҺ°зҠ¶пјҢжҲ‘们梳зҗҶдәҶж•ҙдёӘе»әи®ҫзҡ„ж–№еҗ‘гҖӮеҰӮдёӢеӣҫжүҖзӨәпјҢжҲ‘们дјҡд»Ҙе®№еҷЁз®ЎзҗҶе№іеҸ° KubeSphere дёәеҹәзЎҖжқҘиҝҗиЎҢж— зҠ¶жҖҒжңҚеҠЎпјҢд»ҘеҸҠеҸҜи§ҶеҢ–з®ЎзҗҶ Kubernetes е’ҢеҹәзЎҖи®ҫж–Ҫиө„жәҗгҖӮиҖҢ IaaS иҝҷдёҖеқ—дјҡжҸҗдҫӣдёҖдәӣжңүзҠ¶жҖҒзҡ„жңҚеҠЎпјҢжҜ”еҰӮдёӯй—ҙ件гҖӮ
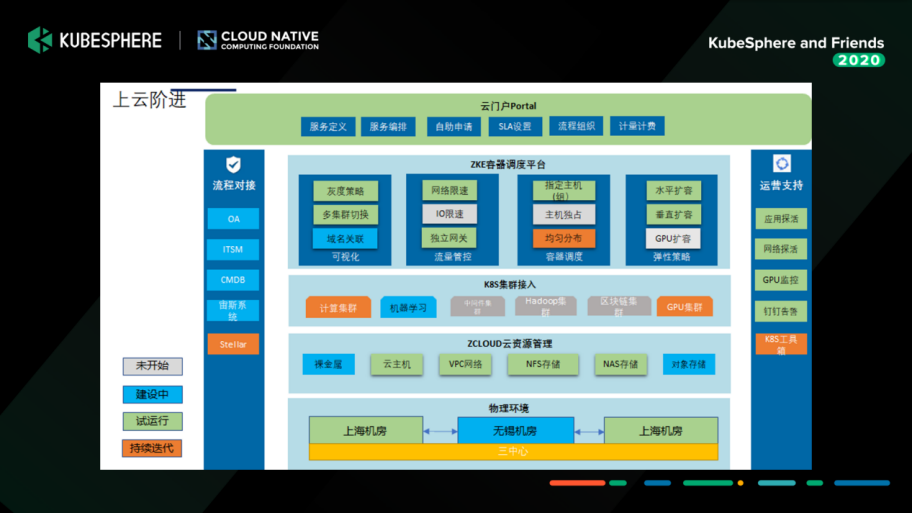
дёӢйқўиҝҷеј еӣҫзӣёдҝЎеӨ§е®¶йқһеёёзҶҹжӮүгҖӮеүҚйқўдёүйғЁеҲҶжҲ‘们еә”з”Ёзҡ„ж•ҲжһңйғҪйқһеёёжЈ’пјҢжҡӮж—¶дёҚдҪңиҝҮеӨҡд»Ӣз»ҚпјҢжҲ‘иҝҳжҳҜзқҖйҮҚи®ІдёҖдёӢеҫ®жңҚеҠЎиҝҷйғЁеҲҶгҖӮжҲ‘们еҪ“ж—¶иҜ•з”ЁдәҶ IstioпјҢеҸ‘зҺ°жҜ”иҫғйҮҚпјҢиҖҢдё”ж”№йҖ зҡ„д»Јд»·жҜ”иҫғеӨ§гҖӮеӣ дёәжҲ‘们зҡ„еҫ®жңҚеҠЎжң¬иә«еҒҡзҡ„е°ұжҜ”иҫғйқ еүҚдәҶпјҢжүҖд»Ҙиҝҷеқ—жҲ‘们жҡӮж—¶жІЎжңүеә”з”ЁпјҢеҗҺз»ӯеҸҜиғҪдјҡеңЁ Java зҡ„йЎ№зӣ®дёҠе°қиҜ•дёҖдёӢгҖӮ
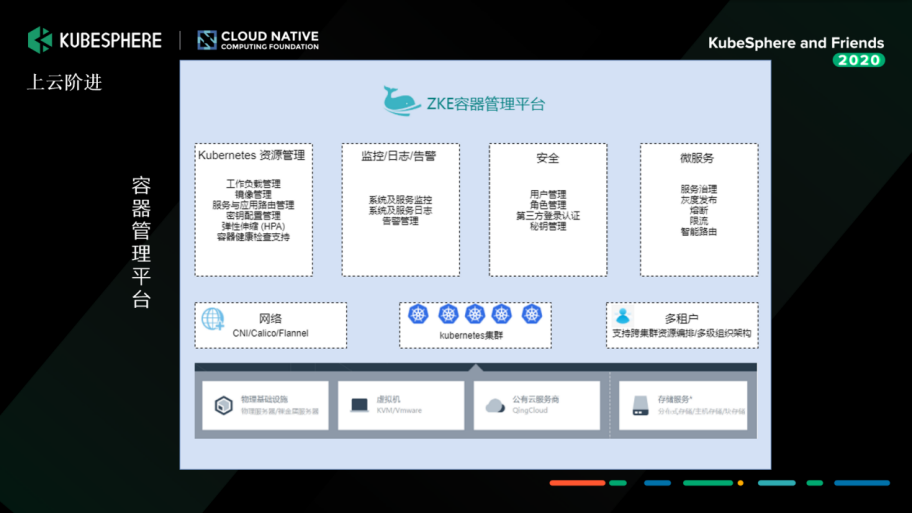
еӨҡз§ҹжҲ·еӨ§йӣҶзҫӨ or еҚ•з§ҹжҲ·е°ҸйӣҶзҫӨпјҹ
йҖүеһӢе®ҢжҲҗеҗҺпјҢжҲ‘们ејҖе§Ӣе»әи®ҫгҖӮйқўдёҙзҡ„第дёҖдёӘй—®йўҳе°ұйқһеёёжЈҳжүӢпјҡжҲ‘们еҲ°еә•жҳҜе»әдёҖдёӘеӨҡз§ҹжҲ·еӨ§йӣҶзҫӨпјҢиҝҳжҳҜе»әеӨҡдёӘеҚ•з§ҹжҲ·зҡ„е°ҸйӣҶзҫӨпјҢжҠҠе®ғеҲҮеҲҶејҖжқҘгҖӮ
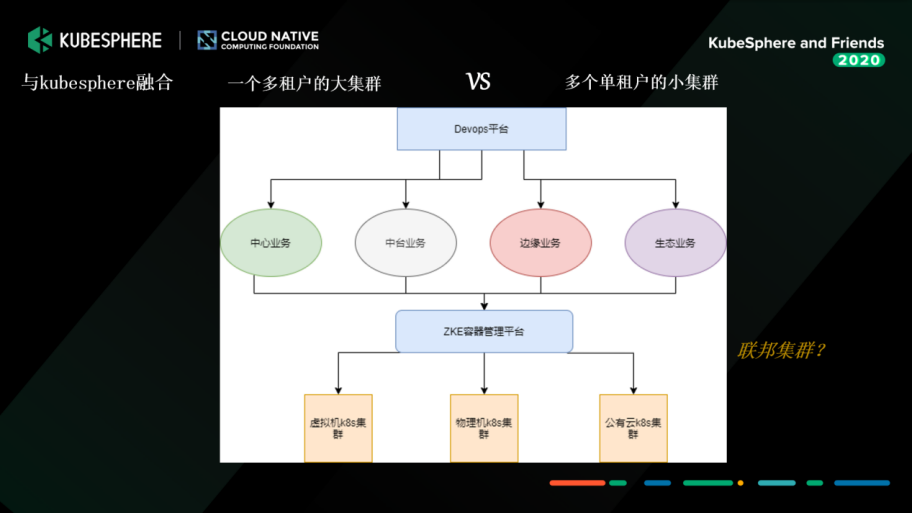
дёҺ KubeSphere еӣўйҳҹжІҹйҖҡеҚҸдҪңпјҢ并充еҲҶиҜ„дј°дәҶжҲ‘们公еҸёзҡ„йңҖжұӮд№ӢеҗҺпјҢеҶіе®ҡжҡӮж—¶йҮҮеҸ–еӨҡдёӘе°ҸйӣҶзҫӨзҡ„ж–№ејҸпјҢд»ҘдёҡеҠЎеңәжҷҜпјҲжҜ”еҰӮдёӯеҸ°дёҡеҠЎгҖҒжү«жҸҸдёҡеҠЎпјүжҲ–иҖ…иө„жәҗеә”з”ЁпјҲжҜ”еҰӮеӨ§ж•°жҚ®гҖҒиҫ№зјҳзҡ„пјүжқҘиҝӣиЎҢеҲҮеҲҶгҖӮжҲ‘们дјҡеҲҮжҲҗеӨҡдёӘе°ҸйӣҶзҫӨпјҢд»ҘдёҠйқўзҡ„ DevOps е№іеҸ°еҒҡ CI/CDгҖӮKubeSphere зҡ„е®№еҷЁз®ЎзҗҶе№іеҸ°дё»иҰҒжҳҜеҒҡдёҖдёӘе®№еҷЁзҡ„ж”Ҝж’‘пјҢеңЁз»Ҳз«Ҝе°ұиғҪеҫҲеҘҪең°и®©з”ЁжҲ·жҹҘзңӢж—Ҙеҝ—гҖҒйғЁзҪІгҖҒйҮҚжһ„зӯүзӯүгҖӮ
еҪ“ж—¶жҲ‘们еҹәдәҺеӨҡйӣҶзҫӨи®ҫи®ЎпјҢд»Ҙ KubeSphere 2.0 дёәи“қеӣҫдҪңж”№йҖ гҖӮеңЁејҖеҸ‘гҖҒжөӢиҜ•е’Ңз”ҹдә§иҖ…дёүдёӘзҺҜеўғдёӯеҲҮпјҢжҲ‘们еңЁжҜҸдёҖдёӘйӣҶзҫӨйҮҢйғҪйғЁзҪІдёҖеҘ— KubeSphereпјҢеҪ“然жңүдёҖдәӣе…¬е…ұзҡ„组件жҲ‘们дјҡжӢҶеҮәжқҘпјҢжҜ”еҰӮзӣ‘жҺ§гҖҒж—Ҙеҝ—иҝҷдәӣгҖӮ
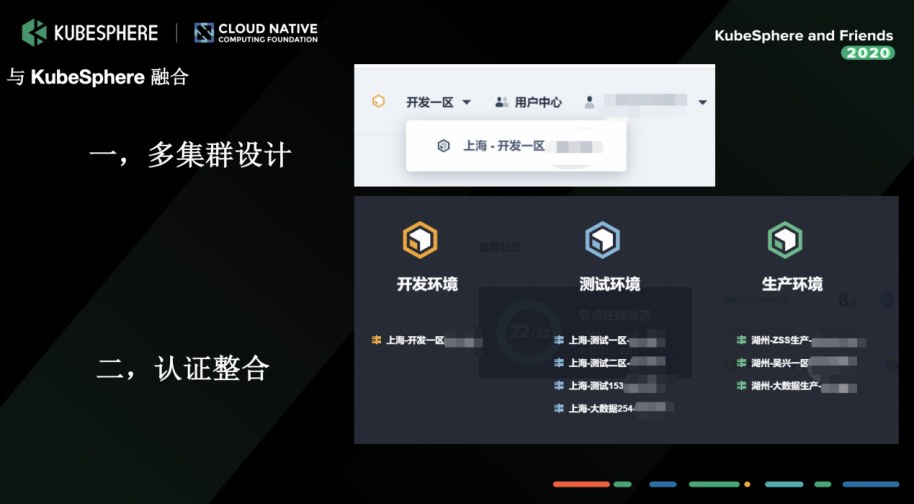
жҲ‘们ж•ҙеҗҲзҡ„ж—¶еҖҷпјҢKubeSphere еӣўйҳҹз»ҷдәҶжҲ‘们йқһеёёеӨҡзҡ„её®еҠ©пјҢз”ұдәҺ KubeSphere 2.0 зүҲжң¬еҸӘж”ҜжҢҒ LDAP еҜ№жҺҘзҡ„ж–№ејҸпјҢиҖҢеҜ№жҺҘ OAuth зҡ„и®ЎеҲ’ж”ҫеңЁ 3.0 зүҲжң¬йҮҢпјҢеҗҺжқҘ KubeSphere еӣўйҳҹеё®жҲ‘们ж•ҙеҗҲеҲ° 2.0пјҢеҚ•зӢ¬жү“дәҶдёҖдёӘеҲҶж”ҜгҖӮеӣ дёәжҲ‘们公еҸёеҶ…йғЁзҡ„ OAuth и®ӨиҜҒиҝҳжңүиҮӘе®ҡд№үзҡ„еҸӮж•°пјҢжҲ‘们ејҖеҸ‘ж”№йҖ еҗҺпјҢйҖҡиҝҮжү«з Ғи®ӨиҜҒзҡ„ж–№ејҸеҫҲеҝ«е°ұж•ҙеҗҲиҝӣжқҘдәҶгҖӮ
еҹәдәҺ KubeSphere дәҢж¬ЎејҖеҸ‘е®һи·ө
дёӢйқўд»Ӣз»ҚдёҖдёӢжҲ‘们еңЁ 2019 е№ҙеӨҸеӨ©еҲ° 2020 е№ҙ 10 жңҲпјҢжҲ‘д»¬ж №жҚ®иҮӘиә«зҡ„дёҡеҠЎеңәжҷҜдёҺ KubeSphere иһҚеҗҲжүҖеҒҡзҡ„е®ҡеҲ¶еҢ–ејҖеҸ‘гҖӮ
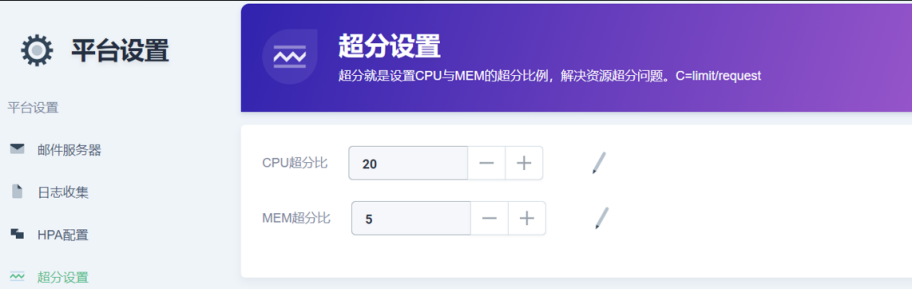
1.и¶…еҲҶи®ҫзҪ®
жҲ‘们йҖҡиҝҮи¶…еҲҶжҜ”зҡ„ж–№ејҸпјҢеҸӘиҰҒдҪ и®ҫзҪ®еҘҪ LimitпјҢжҲ‘们еҫҲеҝ«е°ұиғҪжҠҠдҪ зҡ„ Requset з®—еҘҪпјҢз»ҷдҪ ж•ҙеҗҲиҝӣжқҘгҖӮзӣ®еүҚз”ҹдә§зҡ„иҜқпјҢCPUжҳҜ 10пјҢеҶ…еӯҳеӨ§жҰӮжҳҜ 1.5гҖӮ
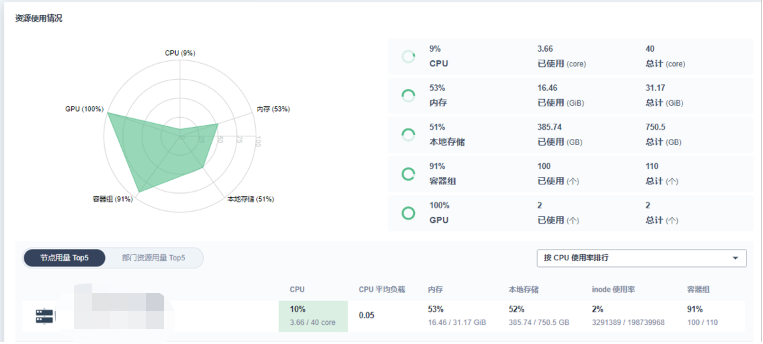
2.GPU йӣҶзҫӨзӣ‘жҺ§
зӣ®еүҚжҲ‘们зҡ„дҪҝз”ЁиҝҳжҳҜжҜ”иҫғеҲқзә§пјҢеҸӘжҳҜжҠҠдҪҝз”Ёжғ…еҶөжөӢеҮәжқҘпјҢеҒҡ GPU йӣҶзҫӨеҚ•зӢ¬зҡ„зӣ‘жҺ§ж•°жҚ®зҡ„еұ•зӨәгҖӮ
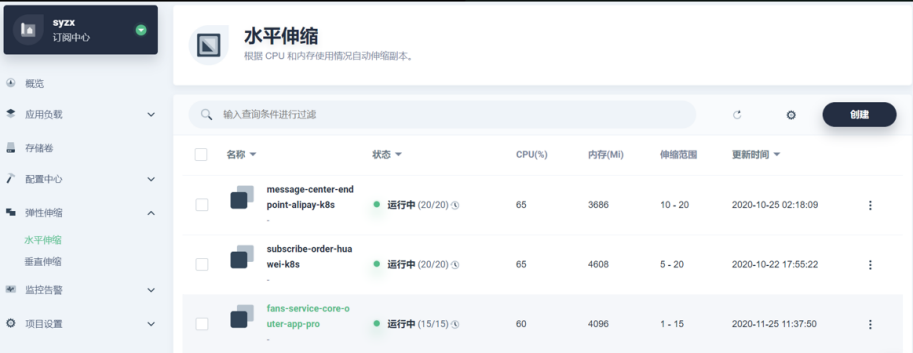
3.HPAпјҲж°ҙе№ідјёзј©пјү
жҲ‘们дҪҝз”Ё KubeSphereпјҢе…¶е®һеҜ№ж°ҙе№ідјёзј©зҡ„жңҹжңӣжҳҜйқһеёёй«ҳзҡ„гҖӮKubeSphere зҡ„иө„жәҗй…ҚзҪ®йҮҢжңүж°ҙе№ідјёзј©пјҢжүҖд»ҘжҲ‘们жҠҠж°ҙе№ідјёзј©иҝҷдёҖеқ—еҚ•зӢ¬жҠҪеҮәжқҘи®ҫзҪ®гҖӮж°ҙе№ідјёзј©зҡ„и®ҫзҪ®й…ҚеҗҲи¶…еҲҶи®ҫзҪ®пјҢе°ұеҸҜд»ҘеҫҲеҘҪең°жҠҠи¶…еҲҶжҜ”жөӢеҮәжқҘгҖӮ
еҫҲеӨҡж ёеҝғдёҡеҠЎе·Із»ҸйҖҡиҝҮ HPA зҡ„ж–№ејҸпјҢйҖҡиҝҮ KubeSphere зҡ„з•Ңйқўи®ҫзҪ®пјҢжңҖз»Ҳд№ҹиҺ·еҫ—дәҶеҫҲеҘҪзҡ„ж•ҲжһңпјҢзҺ°еңЁеҹәжң¬дёҚйңҖиҰҒиҝҗз»ҙе№Ійў„дәҶгҖӮзү№еҲ«жҳҜжңүеә”жҖҘеңәжҷҜзҡ„йңҖжұӮпјҢжҜ”еҰӮдёҠжёё MQ ж¶Ҳиҙ№з§ҜеҺӢдәҶпјҢйңҖиҰҒжҲ‘们з«Ӣ马жү©еүҜжң¬пјҢиҝҷж ·жҲ‘们еҸҜд»Ҙйқһеёёеҝ«ең°е“Қеә”гҖӮ
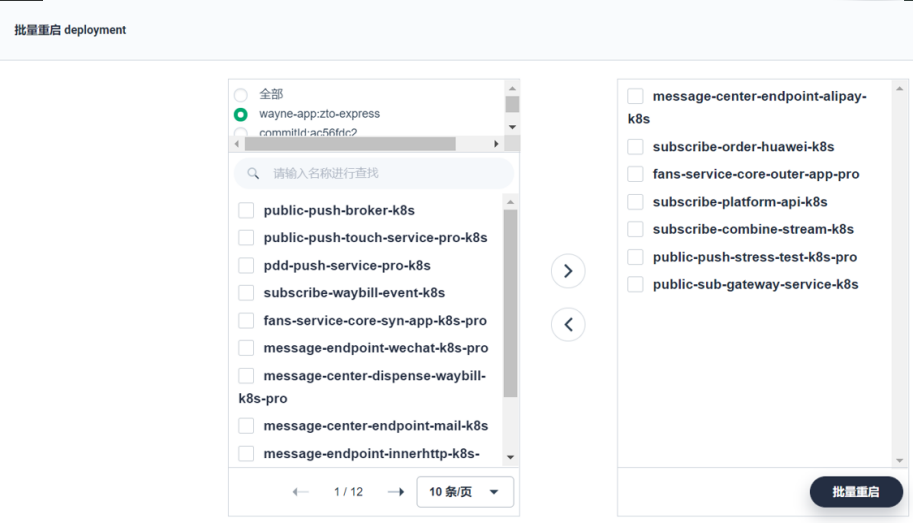
4.жү№йҮҸйҮҚеҗҜ
еңЁжһҒз«Ҝжғ…еҶөдёӢеҸҜиғҪиҰҒжү№йҮҸйҮҚеҗҜеӨ§йҮҸ DeploymentsпјҢжҲ‘们еҚ•зӢ¬жҠҠиҝҷдёӘжҠҪеҮәжқҘеҒҡдәҶдёҖдёӘе°ҸжЁЎеқ—пјҢйҖҡиҝҮ KubeSphere е№іеҸ°дёҖй”®и®ҫзҪ®пјҢжҹҗдёӘйЎ№зӣ®пјҲNameSpaceпјүдёӢзҡ„ Deployment жҲ–иҖ…жҳҜйӣҶзҫӨ马дёҠеҸҜд»ҘйҮҚеҗҜпјҢеҸҜд»Ҙеҫ—еҲ°еҫҲеҝ«зҡ„е“Қеә”гҖӮ
5.е®№еҷЁдәІе’ҢжҖ§
еңЁе®№еҷЁдәІе’ҢжҖ§иҝҷдёҖеқ—пјҢжҲ‘们主иҰҒеҒҡдәҶиҪҜжҖ§зҡ„еҸҚдәІе’ҢгҖӮеӣ дёәжҲ‘们жңүдәӣеә”з”Ёе®ғзҡ„иө„жәҗдҪҝз”ЁеҸҜиғҪжҳҜзӣёж–Ҙзҡ„пјҢжҜ”еҰӮйғҪжҳҜ CPU иө„жәҗдҪҝз”ЁеһӢзҡ„пјҢжҲ‘们з®ҖеҚ•ж”№йҖ дәҶдёҖдёӢпјҢеҠ дәҶдёҖдәӣдәІе’ҢжҖ§зҡ„и®ҫзҪ®гҖӮ
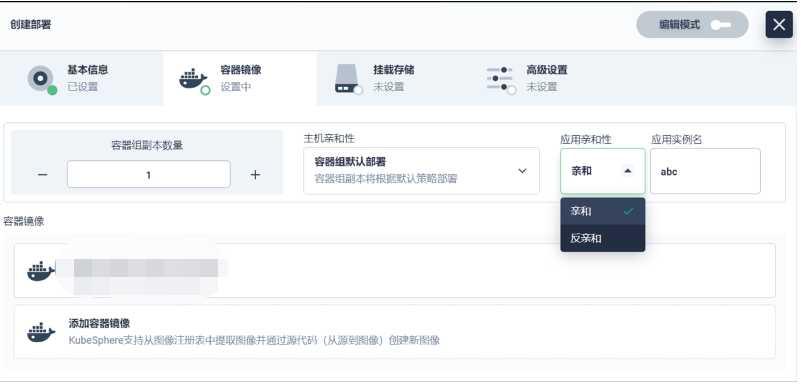
6.и°ғеәҰзӯ–з•Ҙ
еңЁи°ғеәҰзӯ–з•Ҙж–№йқўпјҢеӣ дёәж¶үеҸҠеҲ°жҜ”иҫғж•Ҹж„ҹзҡ„еҗҺеҸ°ж•°жҚ®пјҢжҲ‘们жң¬жқҘжү“з®—йҖҡиҝҮYamlзҡ„ж–№ејҸжқҘеҒҡгҖӮдҪҶжҳҜеҗҺйқўиҝҳжҳҜеҶіе®ҡйҖҡиҝҮ KubeSphere зҡ„й«ҳзә§и®ҫзҪ®йЎөйқўжқҘе®һзҺ°гҖӮжҲ‘们з®ҖеҚ•еҠ дәҶдёҖдәӣйЎөйқўзҡ„е…ғзҙ пјҢжҠҠжҢҮе®ҡдё»жңәгҖҒжҢҮе®ҡдё»жңәз»„гҖҒзӢ¬еҚ дё»жңәзҡ„еҠҹиғҪпјҢйҖҡиҝҮиЎЁиЎҢзҡ„еҪўејҸеҺ»й…ҚзҪ®гҖӮжҲ‘们зҺ°еңЁз”Ёеҫ—зү№еҲ«еҘҪзҡ„жҳҜжҢҮе®ҡдё»жңәз»„е’ҢзӢ¬еҚ дё»жңәиҝҷдёӨдёӘеҠҹиғҪгҖӮ
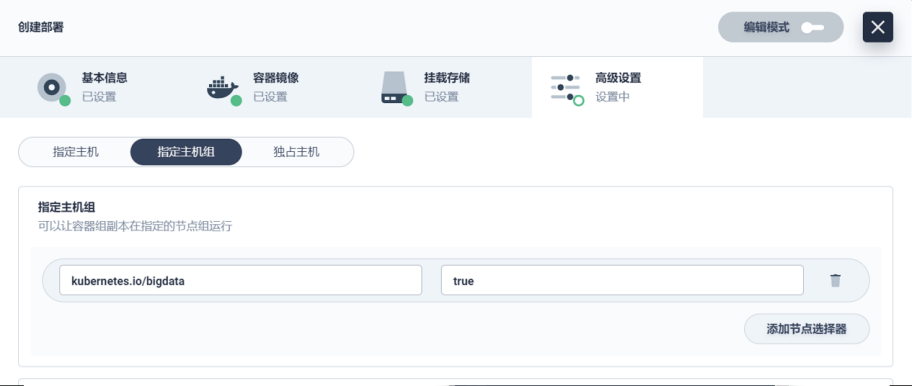
з®ҖеҚ•д»Ӣз»ҚдёӢзӢ¬еҚ дё»жңәзҡ„еә”з”ЁгҖӮжҲ‘们зҡ„ж ёеҝғдёҡеҠЎеңЁжҷҡдёҠеҲ°еҮҢжҷЁе…ӯзӮ№е·ҰеҸіпјҢз”ұдәҺиҝҷдёӘж—¶й—ҙж®өжңҚеҠЎжҳҜжҜ”иҫғз©әй—Ізҡ„пјҢжүҖд»Ҙз”ЁжқҘи·‘еӨ§ж•°жҚ®еә”з”ЁйқһеёёеҗҲйҖӮгҖӮжҲ‘们йҖҡиҝҮзӢ¬еҚ дё»жңәзҡ„ж–№ејҸжҠҠе®ғз©әеҮәжқҘпјҢйҳІжӯўе®ғи·‘ж»Ўж•ҙдёӘйӣҶзҫӨпјҢжүҖд»ҘеҸӘжҳҜжҢӮдәҶжҹҗдәӣзӮ№гҖӮ
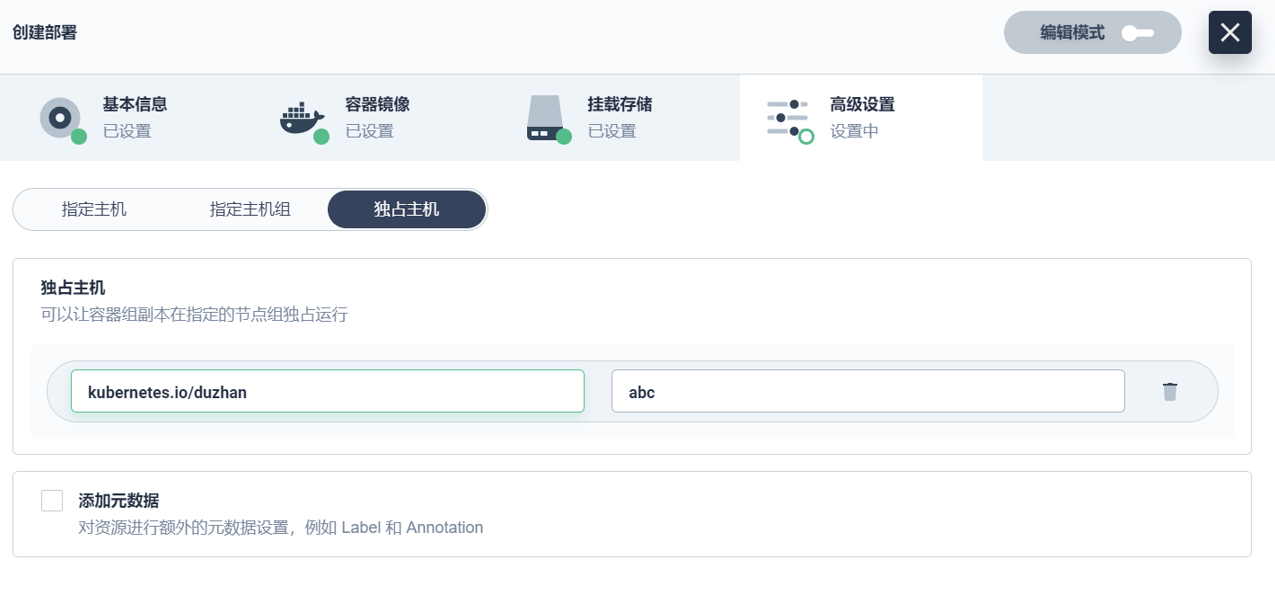
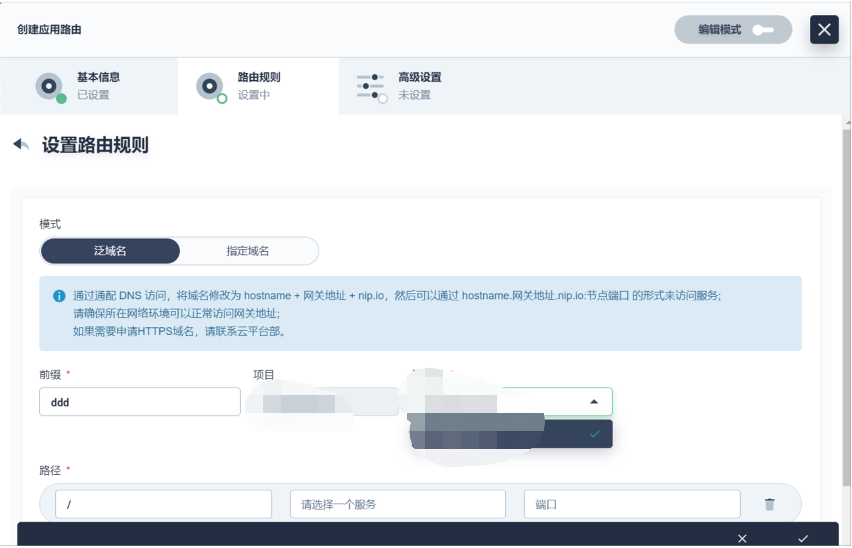
7.зҪ‘е…і
KubeSphere жҳҜжңүзӢ¬з«ӢзҪ‘е…ізҡ„жҰӮеҝөзҡ„пјҢжҜҸдёҖдёӘйЎ№зӣ®дёӢйғҪжңүдёҖдёӘеҚ•зӢ¬зҡ„зҪ‘е…ігҖӮзӢ¬з«ӢзҪ‘е…іж»Ўи¶ідәҶжҲ‘们зҡ„з”ҹдә§йңҖжұӮпјҲеӣ дёәеёҢжңӣз”ҹдә§иө°зӢ¬з«ӢзҪ‘е…ізҡ„ж–№ејҸпјүпјҢдҪҶеңЁејҖеҸ‘жөӢиҜ•жңүдёҖдёӘжіӣзҪ‘е…ізҡ„йңҖжұӮпјҢеӣ дёәжҲ‘们еёҢжңӣжӣҙеҝ«е“Қеә”жңҚеҠЎгҖӮжүҖд»ҘжҲ‘们еҒҡдәҶдёҖдёӘжіӣзҪ‘е…іпјҢиө·дәҶдёҖдёӘзӢ¬з«ӢзҪ‘е…іпјҢжүҖжңүејҖеҸ‘гҖҒжөӢиҜ•гҖҒеҹҹеҗҚйҖҡиҝҮжіӣеҹҹеҗҚзҡ„ж–№ејҸзӣҙжҺҘиҝӣжқҘгҖӮиҝҷдёҖеқ—й…ҚзҪ®еҘҪпјҢйҖҡиҝҮ KubeSphere з•Ңйқўз®ҖеҚ•зј–жҺ’дёҖдёӢпјҢеҹәжң¬дёҠжҲ‘们зҡ„жңҚеҠЎе°ұзӣҙжҺҘеҸҜд»Ҙи®ҝй—®гҖӮ
8.ж—Ҙеҝ—收йӣҶ
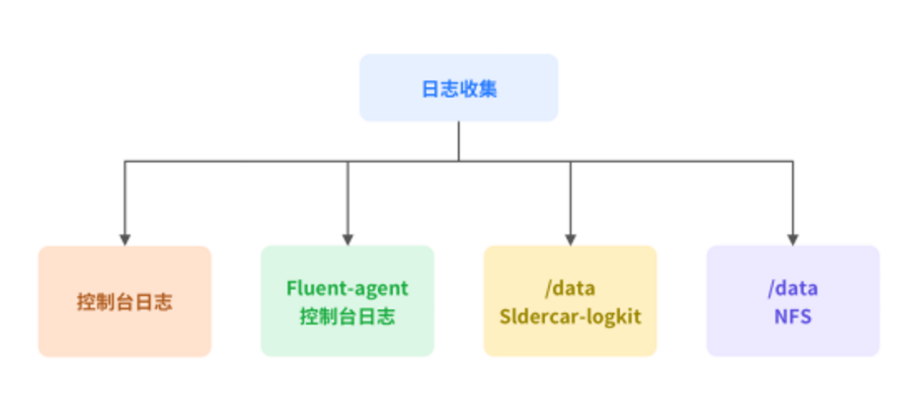
жҲ‘们дёҖејҖе§ӢжҳҜйҮҮз”Ёе®ҳж–№зҡ„ж–№ејҸпјҢд№ҹе°ұжҳҜйҖҡиҝҮ Fluent-Bit зҡ„ж–№ејҸ收йӣҶж—Ҙеҝ—гҖӮдҪҶеҗҺжқҘеҸ‘зҺ°йҡҸзқҖдёҡеҠЎйҮҸдёҠзәҝи¶ҠжқҘи¶ҠеӨҡпјҢFluent-Bit д№ҹдјҡз»ҸеёёжҢӮжҺүгҖӮеҮәзҺ°иҝҷз§Қжғ…еҶөзҡ„еҺҹеӣ пјҢеҸҜиғҪжҳҜжҲ‘们еңЁиө„жәҗдјҳеҢ–ж–№йқўжңүзјәйҷ·пјҢд№ҹеҸҜиғҪжҳҜж•ҙдёӘеҸӮж•°жІЎжңүи°ғеҘҪгҖӮжүҖд»ҘжҲ‘们еҶіе®ҡеҗҜз”Ё Sidecar зҡ„ж–№ејҸжқҘиҝӣиЎҢж—Ҙеҝ—收йӣҶгҖӮJava зҡ„жңҚеҠЎйғҪдјҡеҚ•зӢ¬иө·дёҖдёӘ SidecarпјҢйҖҡиҝҮ Logkit иҝҷз§Қе°Ҹзҡ„ AgentпјҢжҠҠе®ғзҡ„ж—Ҙеҝ—жҺЁеҲ° ElasticSearch иҝҷз§ҚдёӯеҝғгҖӮеңЁејҖеҸ‘жөӢиҜ•зҺҜеўғпјҢжҲ‘们иҝҳдјҡз”Ё Fluen-agent зҡ„ж–№ејҸжқҘ收йӣҶж—Ҙеҝ—гҖӮеҸҰеӨ–жңүдёҖдәӣз”ҹдә§еңәжҷҜпјҢдёҖе®ҡиҰҒдҝқиҜҒж—Ҙеҝ—зҡ„е®Ңж•ҙжҖ§пјҢжүҖд»ҘжҲ‘们дјҡе°Ҷж—Ҙеҝ—иҝӣдёҖжӯҘиҝӣиЎҢзЈҒзӣҳзҡ„жҢҒд№…еҢ–гҖӮйҖҡиҝҮеҰӮдёӢеӣҫдёӯжүҖзӨәзҡ„еӣӣдёӘж–№ејҸпјҢжқҘ收йӣҶе…ЁйғЁзҡ„е®№еҷЁж—Ҙеҝ—гҖӮ
9.дәӢ件и·ҹиёӘ
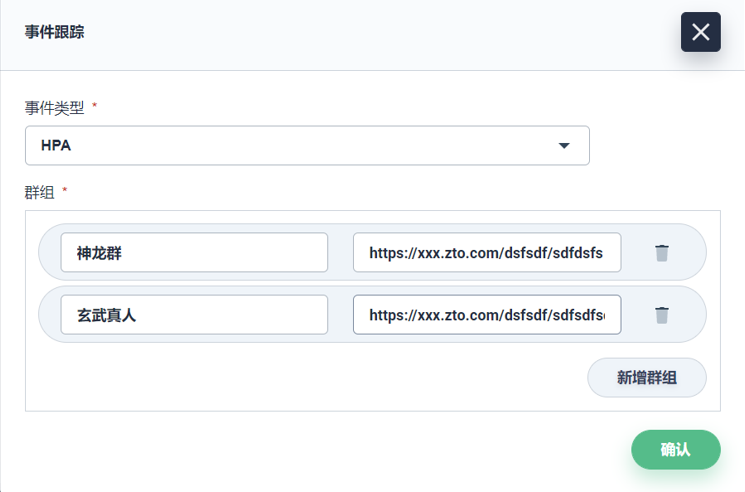
жҲ‘们зӣҙжҺҘжӢҝдәҶйҳҝйҮҢдә‘ејҖжәҗзҡ„ Kube-eventer иҝӣиЎҢж”№йҖ гҖӮKubeSphere иҝҷдёҖеқ—жҲ‘们еҠ дәҶдәӢ件и·ҹиёӘеҸҜд»Ҙй…ҚзҪ®пјҢеҸҜд»ҘеҸ‘еҲ°жҲ‘们зҡ„й’үй’үзҫӨгҖӮе°Өе…¶еңЁз”ҹдә§дёҠжҳҜжҜ”иҫғе…іжіЁдёҡеҠЎзҡ„еҸҳеҠЁзҡ„пјҢйғҪеҸҜд»ҘйҖҡиҝҮе®ҡеҲ¶еҢ–й…ҚеҲ°й’үй’үзҫӨйҮҢйқўгҖӮ
жңӘжқҘ规еҲ’
жҺҘдёӢжқҘжҲ‘们еҸҜиғҪжү№йҮҸжҺЁз”ҹдә§пјҢжҲ‘们д№ҹжҸҗдәҶдёҖдәӣжғіжі•пјҢжғіи·ҹзӨҫеҢәдәӨжөҒдёҖдёӢгҖӮ
1.жңҚеҠЎеӨ§зӣҳ
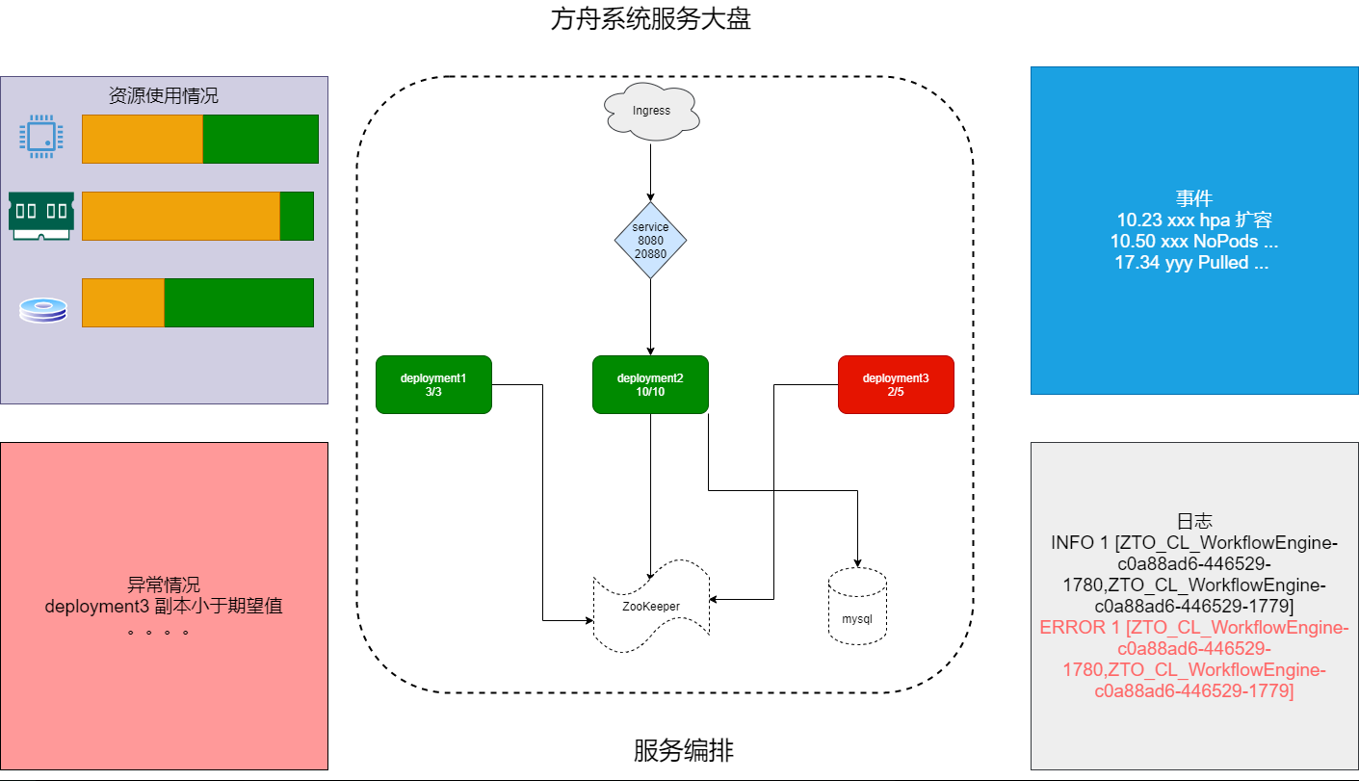
еңЁ KubeSphere жҺ§еҲ¶еҸ°з•ҢйқўжҳҜд»ҘиЎЁиЎҢзҡ„еҪўејҸеҺ»зңӢжҲ‘们зҡ„еҫ®жңҚеҠЎзӯүпјҢдҪҶжҲ‘们дёҚзҹҘйҒ“е®ғ们д№Ӣй—ҙзҡ„е…ізі»пјҢеёҢжңӣйҖҡиҝҮиҝҷз§ҚеӣҫеҪўеҢ–зҡ„ж–№ејҸжҠҠе®ғеұ•зҺ°еҮәжқҘпјҢжҠҠе®ғе…ій”®зҡ„жҢҮж ҮвҖ”вҖ”дәӢ件гҖҒж—Ҙеҝ—гҖҒејӮеёёжғ…еҶөзӯүзӣҙи§Ӯең°е‘ҲзҺ°еҮәжқҘпјҢд»ҘдҫҝдәҺжҲ‘们еҸҜи§ҶеҢ–зҡ„иҝҗиҗҘгҖӮзӣ®еүҚжҲ‘们жӯЈеңЁи§„еҲ’пјҢжҳҺе№ҙеә”иҜҘдјҡеҚ•зӢ¬еҒҡгҖӮ
жҲ‘们жғіиЎЁиҫҫзҡ„жҳҜпјҢж— и®әд»»дҪ•дәәпјҢеҢ…жӢ¬иҝҗз»ҙгҖҒејҖеҸ‘пјҢеҸӘиҰҒжӢҝеҲ°иҝҷеј еӣҫе°ұиғҪзҹҘйҒ“жҲ‘们жңҚеҠЎзҡ„жһ¶жһ„жҳҜд»Җд№Ҳж ·зҡ„пјҢзӣ®еүҚдҫқиө–дәҺе“Әдәӣдёӯй—ҙ件гҖҒе“Әдәӣж•°жҚ®еә“пјҢд»ҘеҸҠжңҚеҠЎзӣ®еүҚзҡ„зҠ¶еҶөпјҢжҜ”еҰӮе“ӘдәӣжңҚеҠЎе®•дәҶпјҢжҲ–иҖ…е“ӘдәӣжңҚеҠЎзӣ®еүҚдјҡжңүйҡҗи—ҸжҖ§зҡ„й—®йўҳгҖӮ
2.е…ЁеҹҹPODS
第дәҢеј еӣҫжҲ‘们иө·зҡ„еҗҚеӯ—еҸ«е…Ёеҹҹ PODSгҖӮеңЁ KubeSphere е®ҳж–№иҝҷиҫ№еә”иҜҘеҸ«зғӯеҠӣеӣҫгҖӮжҲ‘们еёҢжңӣд»Һж•ҙдёӘйӣҶзҫӨзҡ„и§Ҷи§’дёҠпјҢиғҪеӨҹзңӢеҲ°зӣ®еүҚжүҖжңүзҡ„ PODS зҺ°зҠ¶пјҢеҢ…жӢ¬е®ғзҡ„йўңиүІеҸҳеҢ–е’Ңиө„жәҗзҠ¶жҖҒгҖӮ

3.иҫ№зјҳи®Ўз®—
иҫ№зјҳи®Ўз®—иҝҷйғЁеҲҶзҡ„规еҲ’пјҢз”ұжҲ‘зҡ„еҗҢдәӢзҺӢж–ҮиҷҺдёәеӨ§е®¶еҲҶдә«гҖӮ
й’ҲеҜ№иҫ№зјҳи®Ўз®—дёҺе®№еҷЁзҡ„з»“еҗҲпјҢжҲ‘们йҖҡиҝҮи°ғз ”пјҢжңҖз»ҲйҖүжӢ©дәҶ KubeEdgeпјҢдёӯйҖҡйҖӮеҗҲиҫ№зјҳи®Ўз®—иҗҪең°зҡ„еңәжҷҜеҢ…жӢ¬пјҡ
дёӯиҪ¬еҝ«д»¶жү«жҸҸж•°жҚ®дёҠдј гҖӮеҗ„дёӘдёӯиҪ¬дёӯеҝғеҝ«д»¶ж•°жҚ®жү«жҸҸеҗҺпјҢйҰ–е…Ҳз»ҸиҝҮеҗ„дёӯиҪ¬дёӯеҝғйғЁзҪІзҡ„жңҚеҠЎиҝӣиЎҢ第дёҖж¬ЎеӨ„зҗҶпјҢ然еҗҺжҠҠеӨ„зҗҶиҝҮзҡ„ж•°жҚ®дёҠдј еҲ°ж•°жҚ®дёӯеҝғгҖӮеҗ„дёӘдёӯиҪ¬дёӯеҝғйғЁзҪІзҡ„жңҚеҠЎзҺ°еңЁжҳҜйҖҡиҝҮиҮӘеҠЁеҢ–и„ҡжң¬иҝңзЁӢеҸ‘еёғпјҢзӣ®еүҚдёӯйҖҡжүҖжңүдёӯиҪ¬дёӯеҝғе°Ҷиҝ‘ 100 дёӘпјҢжҜҸж¬ЎеҸ‘еёғйңҖиҰҒ 5 дёӘдәә/еӨ©гҖӮеҰӮжһңйҖҡиҝҮиҫ№зјҳз®ЎзҗҶж–№жЎҲпјҢеҸҜд»ҘеӨ§е№…еәҰеҮҸе°‘дәәеҠӣеҸ‘еёғе’Ңиҝҗз»ҙжҲҗжң¬пјҢеҸҰеӨ–еҸҜд»Ҙз»“еҗҲ Kubernetes зӨҫеҢәжҺЁиҚҗзҡ„ Operator ејҖеҸ‘жЁЎејҸжқҘзҒөжҙ»е®ҡеҲ¶еҸ‘еёғзӯ–з•ҘгҖӮ
ж“ҚдҪңе·ҘжҡҙеҠӣеҲҶжӢЈиҮӘеҠЁиҜҶеҲ«гҖӮдёӯйҖҡдёәдәҶйҷҚдҪҺеҝ«д»¶з ҙжҚҹзҺҮпјҢеңЁеҗ„дёӯиҪ¬дёӯеҝғеҸҠе…¶зҪ‘зӮ№жөҒж°ҙзәҝе®үзҪ®ж‘„еғҸеӨҙжү«жҸҸж“ҚдҪңе·Ҙж—Ҙеёёж“ҚдҪңпјҢжү«жҸҸеҲ°зҡ„ж•°жҚ®дјҡдј еҲ°жң¬ең°зҡ„ GPU зӣ’еӯҗиҝӣиЎҢеӣҫзүҮеӨ„зҗҶпјҢеӨ„зҗҶе®Ңзҡ„ж•°жҚ®дј еҲ°ж•°жҚ®дёӯеҝғгҖӮеҪ“еүҚ GPU зӣ’еӯҗеҶ…зҡ„еә”з”ЁеҸ‘еёғдёәжүӢеҠЁзҷ»еҪ•еҸ‘еёғпјҢж•ҲзҺҮйқһеёёдҪҺпјӣзӣ’еӯҗз»ҸеёёиҝҳдјҡеҮәзҺ°еӨұиҒ”пјҢеҸ‘зҺ°иҜҘй—®йўҳж—¶еҸҜиғҪе·Із»ҸиҝҮдәҶеҫҲй•ҝж—¶й—ҙгҖӮйҖҡиҝҮ KubeEdge иҫ№зјҳж–№жЎҲд№ҹеҸҜд»Ҙи§ЈеҶіеҪ“еүҚеҸ‘еёғдёҺиҠӮзӮ№зӣ‘жҺ§й—®йўҳгҖӮ
еҗ„дёӯеҝғжҷәж…§еӣӯеҢәйЎ№зӣ®иҗҪең°гҖӮиҜҘйЎ№зӣ®д№ҹжӯЈеңЁе…¬еҸёиҗҪең°пјҢеҗҺз»ӯд№ҹдјҡжңүеҫҲеӨҡиҫ№зјҳеңәжҷҜеҸҜд»ҘеҖҹеҠ©е®№еҷЁжҠҖжңҜи§ЈеҶіеҪ“еүҚз—ӣзӮ№гҖӮ
е…ідәҺеҹәдәҺKubeSphere еңЁз”ҹдә§зҺҜеўғзҡ„ејҖеҸ‘дёҺйғЁзҪІе®һи·өжҳҜжҖҺж ·зҡ„й—®йўҳзҡ„и§Јзӯ”е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҰӮжһңдҪ иҝҳжңүеҫҲеӨҡз–‘жғ‘жІЎжңүи§ЈејҖпјҢеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“дәҶи§ЈжӣҙеӨҡзӣёе…ізҹҘиҜҶгҖӮ





