д»Җд№ҲжҳҜAntlr4
жң¬зҜҮеҶ…е®№дё»иҰҒи®Іи§ЈвҖңд»Җд№ҲжҳҜAntlr4вҖқпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢдёҚеҰЁжқҘзңӢзңӢгҖӮжң¬ж–Үд»Ӣз»Қзҡ„ж–№жі•ж“ҚдҪңз®ҖеҚ•еҝ«жҚ·пјҢе®һз”ЁжҖ§ејәгҖӮдёӢйқўе°ұи®©е°Ҹзј–жқҘеёҰеӨ§е®¶еӯҰд№ вҖңд»Җд№ҲжҳҜAntlr4вҖқеҗ§!
1. Antlr4з®ҖеҚ•д»Ӣз»Қ
Antlr4пјҲAnother Tool for Language RecognitionпјүжҳҜдёҖж¬ҫеҹәдәҺJavaејҖеҸ‘зҡ„ејҖжәҗзҡ„иҜӯжі•еҲҶжһҗеҷЁз”ҹжҲҗе·Ҙе…·пјҢиғҪеӨҹж №жҚ®иҜӯ法规еҲҷж–Ү件з”ҹжҲҗеҜ№еә”зҡ„иҜӯжі•еҲҶжһҗеҷЁпјҢе№ҝжіӣеә”з”ЁдәҺDSLжһ„е»әпјҢиҜӯиЁҖиҜҚжі•иҜӯжі•и§ЈжһҗзӯүйўҶеҹҹгҖӮзҺ°еңЁеңЁйқһеёёеӨҡзҡ„жөҒиЎҢзҡ„жЎҶжһ¶дёӯйғҪз”ЁдҪҝз”ЁпјҢдҫӢеҰӮпјҢеңЁжһ„е»әзү№е®ҡиҜӯиЁҖзҡ„ASTж–№йқўпјҢCheckStyleе·Ҙе…·пјҢе°ұжҳҜеҹәдәҺAntlrжқҘи§ЈжһҗJavaзҡ„иҜӯжі•з»“жһ„зҡ„пјҲеҪ“еүҚJava ParserжҳҜеҹәдәҺJavaCCжқҘи§ЈжһҗJavaж–Ү件зҡ„пјҢжҚ®иҜҙжңү规еҲ’еңЁдёӢдёӘзүҲжң¬ж”№з”ЁAntlrжқҘи§ЈжһҗпјүпјҢиҝҳжңүе°ұжҳҜе№ҝжіӣеә”з”ЁеңЁDSLжһ„е»әдёҠпјҢи‘—еҗҚзҡ„Eclipse Xtextе°ұжңүдҪҝз”ЁAntlrгҖӮ
AntlrеҸҜд»Ҙз”ҹжҲҗдёҚеҗҢtargetзҡ„ASTпјҲhttps://www.antlr.org/download.htmlпјүпјҢеҢ…жӢ¬JavaгҖҒC++гҖҒJSгҖҒPythonгҖҒC#зӯүпјҢеҸҜд»Ҙж»Ўи¶ідёҚеҗҢиҜӯиЁҖзҡ„ејҖеҸ‘йңҖжұӮгҖӮеҪ“еүҚAntlrжңҖж–°зЁіе®ҡзүҲжң¬дёә4.9пјҢAntlr4е®ҳж–№githubд»“еә“дёӯпјҢе·Із»Ҹжңүж•°еҚҒз§ҚиҜӯиЁҖзҡ„grammerпјҲhttps://github.com/antlr/grammars-v4пјҢдёҚиҝҮиҷҪ然иҝҷд№ҲеӨҡиҜӯиЁҖзҡ„规еҲҷж–Үжі•е®ҡд№үйғҪеңЁдёҖдёӘд»“еә“дёӯпјҢдҪҶжҳҜжҜҸз§ҚиҜӯиЁҖзҡ„grammerзҡ„licenseжҳҜдёҚдёҖж ·зҡ„пјҢеҰӮжһңиҰҒдҪҝз”ЁпјҢйңҖиҰҒеҸӮиҖғжҜҸз§ҚиҜӯиЁҖиҮӘе·ұзҡ„иҜӯжі•з»“жһ„зҡ„licenseпјүгҖӮ
жң¬ж–Үе°ҶйҰ–е…Ҳд»Ӣз»ҚAntlr4 grammerзҡ„е®ҡд№үж–№ејҸпјҲз®ҖеҚ•д»Ӣз»ҚиҜӯжі•з»“жһ„пјҢ并д»Ӣз»ҚеҰӮдҪ•еҹәдәҺIDEA Antlr4жҸ’件иҝӣиЎҢи°ғиҜ•пјүпјҢ然еҗҺд»Ӣз»ҚеҰӮдҪ•йҖҡиҝҮAntlr4 grammerз”ҹжҲҗеҜ№еә”зҡ„ASTпјҢжңҖеҗҺд»Ӣз»ҚAntlr4 зҡ„дёӨз§ҚASTйҒҚеҺҶж–№ејҸпјҡVisitorж–№ејҸе’ҢListenerж–№ејҸгҖӮ
2. Antlr4规еҲҷж–Үжі•
дёӢйқўз®ҖеҚ•д»Ӣз»ҚдёҖйғЁеҲҶAntlr4зҡ„g4пјҲgrammarпјүж–Ү件зҡ„еҶҷжі• пјҲдё»иҰҒеҸӮиҖғAntlr4е®ҳж–№wikiпјҡhttps://github.com/antlr/antlr4/blob/master/doc/index.mdпјүгҖӮ жңҖжңүж•Ҳзҡ„еӯҰд№ Antlr4зҡ„规еҲҷж–Үжі•зҡ„еҶҷжі•зҡ„ж–№жі•пјҢе°ұжҳҜеҸӮиҖғе·Іжңүзҡ„规еҲҷж–Үжі•пјҢеӨ§е®¶еңЁеӯҰд№ дёӯпјҢеҸҜд»ҘеҸӮиҖғе·ІжңүиҜӯиЁҖзҡ„ж–Үжі•гҖӮиҖҢдё”Antlr4е·Із»Ҹе®һзҺ°дәҶж•°еҚҒз§ҚиҜӯиЁҖзҡ„ж–Үжі•пјҢеҰӮжһңйңҖиҰҒиҮӘе·ұе®ҡд№үпјҢеҸҜд»ҘеҸӮиҖғе’ҢиҮӘе·ұзҡ„иҜӯиЁҖжңҖжҺҘиҝ‘зҡ„ж–Үжі•жқҘејҖеҸ‘гҖӮ
2.1 Antlr4规еҲҷеҹәжң¬иҜӯжі•е’Ңе…ій”®еӯ—
йҰ–е…ҲпјҢеҰӮжһңжңүдёҖзӮ№е„ҝCжҲ–иҖ…JavaеҹәзЎҖпјҢеҜ№дёҠжүӢAntlr4 g4зҡ„ж–Үжі•йқһеёёеҝ«гҖӮдё»иҰҒжңүдёӢйқўзҡ„дёҖдәӣж–Үжі•з»“жһ„пјҡ
жіЁйҮҠпјҡе’ҢJavaзҡ„жіЁйҮҠе®Ңе…ЁдёҖиҮҙпјҢд№ҹеҸҜеҸӮиҖғCзҡ„жіЁйҮҠпјҢеҸӘжҳҜеўһеҠ дәҶJavaDocзұ»еһӢзҡ„жіЁйҮҠпјӣ
ж Үеҝ—з¬ҰпјҡеҸӮиҖғJavaжҲ–иҖ…Cзҡ„ж Үеҝ—з¬Ұе‘ҪеҗҚ规иҢғпјҢй’ҲеҜ№Lexer йғЁеҲҶзҡ„ Token еҗҚзҡ„е®ҡд№үпјҢйҮҮз”Ёе…ЁеӨ§еҶҷеӯ—жҜҚзҡ„еҪўејҸпјҢеҜ№дәҺparser ruleе‘ҪеҗҚпјҢжҺЁиҚҗйҰ–еӯ—жҜҚе°ҸеҶҷзҡ„й©јеі°е‘ҪеҗҚпјӣ
дёҚеҢәеҲҶеӯ—з¬Ұе’Ңеӯ—з¬ҰдёІпјҢйғҪжҳҜз”ЁеҚ•еј•еҸ·еј•иө·жқҘзҡ„пјҢеҗҢж—¶пјҢиҷҪ然Antlr g4ж”ҜжҢҒ Unicodeзј–з ҒпјҲеҚіж”ҜжҢҒдёӯж–Үзј–з ҒпјүпјҢдҪҶжҳҜе»әи®®еӨ§е®¶е°ҪйҮҸиҝҳжңүиӢұж–Үпјӣ
ActionпјҢиЎҢдёәпјҢдё»иҰҒжңү@header е’Ң@membersпјҢз”ЁжқҘе®ҡд№үдёҖдәӣйңҖиҰҒз”ҹжҲҗеҲ°зӣ®ж Үд»Јз Ғдёӯзҡ„иЎҢдёәпјҢдҫӢеҰӮпјҢеҸҜд»ҘйҖҡиҝҮ@headerи®ҫзҪ®з”ҹжҲҗзҡ„д»Јз Ғзҡ„packageдҝЎжҒҜпјҢ@membersеҸҜд»Ҙе®ҡд№үйўқеӨ–зҡ„дёҖдәӣеҸҳйҮҸеҲ°Antlr4иҜӯжі•ж–Ү件дёӯпјӣ
Antlr4иҜӯжі•дёӯпјҢж”ҜжҢҒзҡ„е…ій”®еӯ—жңүпјҡimport, fragment, lexer, parser, grammar, returns, locals, throws, catch, finally, mode, options, tokensгҖӮ
2.2 Antlr4иҜӯжі•д»Ӣз»Қ
2.2.1иҜӯжі•ж–Ү件зҡ„ж•ҙдҪ“з»“жһ„еҸҠеҶҷжі•зӨәдҫӢ
Antlr4ж•ҙдҪ“з»“жһ„еҰӮдёӢпјҡ
/** Optional javadoc style comment */
grammar Name;
options {...}
import ... ;
tokens {...}
channels {...} // lexer only
@actionName {...}
rule1 // parser and lexer rules, possibly intermingled
...
ruleNдёҖиҲ¬еҰӮжһңиҜӯжі•йқһеёёеӨҚжқӮпјҢдјҡеҹәдәҺLexerе’ҢParserеҶҷеҲ°дёӨдёӘдёҚеҗҢзҡ„ж–Ү件дёӯпјҲдҫӢеҰӮJavaпјҢеҸҜеҸӮиҖғпјҡhttps://github.com/antlr/grammars-v4/tree/master/java/java8пјүпјҢеҰӮжһңиҜӯжі•жҜ”иҫғз®ҖеҚ•пјҢеҸҜд»ҘеҸӘеҶҷеҲ°дёҖдёӘж–Ү件дёӯпјҲдҫӢеҰӮLuaпјҢеҸҜеҸӮиҖғпјҡhttps://github.com/antlr/grammars-v4/blob/master/lua/Lua.g4пјүгҖӮ
дёӢйқўжҲ‘们结еҗҲLua.g4дёӯзҡ„дёҖйғЁеҲҶиҜӯжі•з»“жһ„пјҢд»Ӣз»ҚдҪҝз”Ёж–№жі•гҖӮеҶҷAntlr4зҡ„ж–Үжі•пјҢйңҖиҰҒдҫқжҚ®жәҗз Ғзҡ„з»“жһ„жқҘеҶіе®ҡгҖӮе®ҡд№үж—¶пјҢдҫқжҚ®жәҗз Ғж–Ү件зҡ„еҶҷжі•пјҢд»ҺдёҠеҲ°дёӢејҖе§Ӣжһ„йҖ иҜӯжі•з»“жһ„гҖӮдҫӢеҰӮпјҢдёӢйқўжҳҜLua.g4зҡ„дёҖйғЁеҲҶпјҡ
chunk
: block EOF
;
block
: stat* retstat?
;
stat
: ';'
| varlist '=' explist
| functioncall
| label
| 'break'
| 'goto' NAME
| 'do' block 'end'
| 'while' exp 'do' block 'end'
| 'repeat' block 'until' exp
| 'if' exp 'then' block ('elseif' exp 'then' block)* ('else' block)? 'end'
| 'for' NAME '=' exp ',' exp (',' exp)? 'do' block 'end'
| 'for' namelist 'in' explist 'do' block 'end'
| 'function' funcname funcbody
| 'local' 'function' NAME funcbody
| 'local' attnamelist ('=' explist)?
;
attnamelist
: NAME attrib (',' NAME attrib)*
;еҰӮдёҠиҜӯжі•дёӯпјҢж•ҙдёӘж–Ү件被表зӨәжҲҗдёҖдёӘchunkпјҢchunkиЎЁзӨәдёәдёҖдёӘblockе’ҢдёҖдёӘж–Ү件结жқҹз¬ҰпјҲEOFпјүпјӣblockеҸҲиў«иЎЁзӨәдёәдёҖзі»еҲ—зҡ„иҜӯеҸҘзҡ„йӣҶеҗҲпјҢиҖҢжҜҸдёҖз§ҚиҜӯеҸҘеҸҲжңүзү№е®ҡзҡ„иҜӯжі•з»“жһ„пјҢеҢ…еҗ«дәҶзү№е®ҡзҡ„иЎЁиҫҫејҸгҖҒе…ій”®еӯ—гҖҒеҸҳйҮҸгҖҒеёёйҮҸзӯүдҝЎжҒҜпјҢ然еҗҺйҖ’еҪ’иЎЁиҫҫејҸзҡ„ж–Үжі•з»„жҲҗпјҢеҸҳйҮҸзҡ„еҶҷжі•зӯүпјҢжңҖз»Ҳе…ЁйғЁйғҪеҪ’з»“еҲ°LexerпјҲTokenпјүдёҠпјҢйҖ’еҪ’ж ‘з»“жқҹгҖӮ
дёҠйқўе…¶е®һе·Із»ҸеҸҜд»ҘзңӢеҲ°Antlr4规еҲҷзҡ„еҶҷжі•пјҢдёӢйқўд»Ӣз»ҚдёҖйғЁеҲҶжҜ”иҫғйҮҚиҰҒзҡ„规еҲҷзҡ„еҶҷжі•гҖӮ
2.2.2 жӣҝд»Јж Үзӯҫ
йҰ–е…ҲпјҢеҰӮ2.2.1иҠӮзҡ„д»Јз ҒжүҖзӨәпјҢstatеҸҜд»ҘжңүйқһеёёеӨҡзҡ„зұ»еһӢпјҢдҫӢеҰӮеҸҳйҮҸе®ҡд№үгҖҒеҮҪж•°е®ҡд№үгҖҒifгҖҒwhileзӯүпјҢиҝҷдәӣйғҪжІЎжңүиҝӣиЎҢеҢәеҲҶпјҢиҝҷж ·и§ЈжһҗеҮәжқҘиҜӯжі•ж ‘ж—¶пјҢдјҡеҫҲдёҚжё…жҷ°пјҢйңҖиҰҒз»“еҗҲеҫҲеӨҡзҡ„ж Үи®°е®ҢжҲҗе…·дҪ“иҜӯеҸҘзҡ„иҜҶеҲ«пјҢиҝҷз§Қжғ…еҶөдёӢпјҢжҲ‘们еҸҜд»Ҙз»“еҗҲжӣҝд»Јж Үзӯҫе®ҢжҲҗеҢәеҲҶпјҢеҰӮдёӢд»Јз Ғпјҡ
stat
: ';'
| varlist '=' explist #varListStat
| functioncall #functionCallStat
| label #labelStat
| 'break' #breakStat
| 'goto' NAME #gotoStat
| 'do' block 'end' #doStat
| 'while' exp 'do' block 'end' #whileStat
| 'repeat' block 'until' exp #repeatStat
| 'if' exp 'then' block ('elseif' exp 'then' block)* ('else' block)? 'end' #ifStat
| 'for' NAME '=' exp ',' exp (',' exp)? 'do' block 'end' #forStat
| 'for' namelist 'in' explist 'do' block 'end' #forInStat
| 'function' funcname funcbody #functionDefStat
| 'local' 'function' NAME funcbody #localFunctionDefStat
| 'local' attnamelist ('=' explist)? #localVarListStat
;йҖҡиҝҮеңЁиҜӯеҸҘеҗҺйқўпјҢж·»еҠ #жӣҝд»Јж ҮзӯҫпјҢеҸҜд»Ҙе°ҶиҜӯеҸҘиҪ¬жҚўдёәиҝҷдәӣжӣҝд»Јж ҮзӯҫпјҢд»ҺиҖҢеҠ д»ҘеҢәеҲҶгҖӮ
2.2.3 ж“ҚдҪңз¬Ұдјҳе…Ҳзә§еӨ„зҗҶ
й»ҳи®Өжғ…еҶөдёӢпјҢANTLRд»Һе·ҰеҲ°еҸіз»“еҗҲиҝҗз®—з¬ҰпјҢ然иҖҢжҹҗдәӣеғҸжҢҮж•°зҫӨиҝҷж ·зҡ„иҝҗз®—з¬ҰеҲҷжҳҜд»ҺеҸіеҲ°е·ҰгҖӮеҸҜд»ҘдҪҝз”ЁйҖүйЎ№assocжүӢеҠЁжҢҮе®ҡиҝҗз®—з¬Ұи®°еҸ·дёҠзҡ„зӣёе…іжҖ§гҖӮеҰӮдёӢйқўзҡ„ж“ҚдҪңпјҡ
expr : expr '^'<assoc=right> expr
^ иЎЁзӨәжҢҮж•°иҝҗз®—пјҢеўһеҠ assoc=rightпјҢиЎЁзӨәиҜҘиҝҗз®—з¬ҰжҳҜеҸіз»“еҗҲгҖӮ
е®һйҷ…дёҠпјҢAntlr4 е·Із»ҸеҜ№дёҖдәӣеёёз”Ёзҡ„ж“ҚдҪңз¬Ұзҡ„дјҳе…Ҳзә§иҝӣиЎҢдәҶеӨ„зҗҶпјҢдҫӢеҰӮеҠ еҮҸд№ҳйҷӨзӯүпјҢиҝҷдәӣе°ұдёҚйңҖиҰҒеҶҚзү№ж®ҠеӨ„зҗҶгҖӮ
2.2.4 йҡҗи—ҸйҖҡйҒ“
еҫҲеӨҡдҝЎжҒҜпјҢдҫӢеҰӮжіЁйҮҠгҖҒз©әж јзӯүпјҢжҳҜз»“жһңдҝЎжҒҜз”ҹжҲҗдёҚйңҖиҰҒеӨ„зҗҶзҡ„пјҢдҪҶжҳҜжҲ‘们еҸҲдёҚйҖӮеҗҲзӣҙжҺҘдёўејғпјҢе®үе…Ёең°еҝҪз•ҘжҺүжіЁйҮҠе’Ңз©әж јзҡ„ж–№жі•жҳҜжҠҠиҝҷдәӣеҸ‘йҖҒз»ҷиҜӯжі•еҲҶжһҗеҷЁзҡ„и®°еҸ·ж”ҫеҲ°дёҖдёӘвҖңйҡҗи—ҸйҖҡйҒ“вҖқдёӯпјҢиҜӯжі•еҲҶжһҗеҷЁд»…йңҖиҰҒи°ғеҚҸеҲ°еҚ•дёӘйҖҡйҒ“еҚіеҸҜгҖӮжҲ‘们еҸҜд»ҘжҠҠд»»дҪ•жҲ‘们жғіиҰҒзҡ„дёңиҘҝдј йҖ’еҲ°е…¶е®ғйҖҡйҒ“дёӯгҖӮеңЁLua.g4дёӯпјҢиҝҷзұ»дҝЎжҒҜзҡ„еӨ„зҗҶеҰӮдёӢпјҡ
COMMENT
: '--[' NESTED_STR ']' -> channel(HIDDEN)
;
LINE_COMMENT
: '--'
( // --
| '[' '='* // --[==
| '[' '='* ~('='|'['|'\r'|'\n') ~('\r'|'\n')* // --[==AA
| ~('['|'\r'|'\n') ~('\r'|'\n')* // --AAA
) ('\r\n'|'\r'|'\n'|EOF)
-> channel(HIDDEN)
;
WS
: [ \t\u000C\r\n]+ -> skip
;
SHEBANG
: '#' '!' ~('\n'|'\r')* -> channel(HIDDEN)
;ж”ҫеҲ° channel(HIDDEN) дёӯзҡ„ TokenпјҢдёҚдјҡиў«иҜӯжі•и§Јжһҗйҳ¶ж®өеӨ„зҗҶпјҢдҪҶжҳҜеҸҜд»ҘйҖҡиҝҮTokenйҒҚеҺҶиҺ·еҸ–еҲ°гҖӮ
2.2.5 еёёи§ҒиҜҚжі•з»“жһ„
Antlr4йҮҮз”ЁBNFиҢғејҸпјҢз”ЁвҖҷ|вҖҷиЎЁзӨәеҲҶж”ҜйҖүйЎ№пјҢвҖҷ*вҖҷиЎЁзӨәеҢ№й…ҚеүҚдёҖдёӘеҢ№й…ҚйЎ№0ж¬ЎжҲ–иҖ…еӨҡж¬ЎпјҢвҖҷ+вҖҷ иЎЁзӨәеҢ№й…ҚеүҚдёҖдёӘеҢ№й…ҚйЎ№иҮіе°‘дёҖж¬ЎгҖӮдёӢйқўд»Ӣз»ҚеҮ з§Қеёёи§Ғзҡ„иҜҚжі•дёҫдҫӢпјҲеқҮжқҘиҮӘLua.g4ж–Ү件пјүпјҡ
1) жіЁйҮҠдҝЎжҒҜ
COMMENT
: '--[' NESTED_STR ']' -> channel(HIDDEN)
;
LINE_COMMENT
: '--'
( // --
| '[' '='* // --[==
| '[' '='* ~('='|'['|'\r'|'\n') ~('\r'|'\n')* // --[==AA
| ~('['|'\r'|'\n') ~('\r'|'\n')* // --AAA
) ('\r\n'|'\r'|'\n'|EOF)
-> channel(HIDDEN)
;2) ж•°еӯ—
INT
: Digit+
;
Digit
: [0-9]
;
3) IDпјҲе‘ҪеҗҚпјү
NAME
: [a-zA-Z_][a-zA-Z_0-9]*
;
3. еҹәдәҺIDEAи°ғиҜ•Antlr4иҜӯ法规еҲҷпјҲж–Үжі•еҸҜи§ҶеҢ–пјү
еҰӮжһңиҰҒе®үиЈ…Antlr4пјҢйҖүжӢ© File -> Settings -> PluginsпјҢ然еҗҺеңЁжҗңзҙўжЎҶжҗңзҙў Antlrе®үиЈ…еҚіеҸҜпјҢеҸҜд»ҘйҖүжӢ©е®үиЈ…жҗңзҙўеҮәжқҘзҡ„жңҖж–°зүҲжң¬пјҢдёӢеӣҫжҳҜеҲҡеҲҡе®үиЈ…зҡ„ANTLR v4пјҢзүҲжң¬жҳҜv1.15пјҢж”ҜжҢҒжңҖж–°зҡ„Antlr 4.9зүҲжң¬гҖӮ
еҹәдәҺIDEAи°ғиҜ•Antlr4иҜӯжі•дёҖиҲ¬жӯҘйӘӨпјҡ
1) еҲӣе»әдёҖдёӘи°ғиҜ•е·ҘзЁӢпјҢ并еҲӣе»әдёҖдёӘg4ж–Ү件
иҝҷйҮҢпјҢжҲ‘иҮӘе·ұжөӢиҜ•з”ЁJavaејҖеҸ‘пјҢжүҖд»ҘеҲӣе»әзҡ„жҳҜдёҖдёӘMavenе·ҘзЁӢпјҢg4ж–Ү件ж”ҫеңЁдәҶsrc/main/resources зӣ®еҪ•дёӢпјҢеҸ–еҗҚ Test.g4
2пјүеҶҷдёҖдёӘз®ҖеҚ•зҡ„иҜӯжі•з»“жһ„
иҝҷйҮҢжҲ‘们еҸӮиҖғеҶҷдёҖдёӘеҠ еҮҸд№ҳйҷӨж“ҚдҪңзҡ„иЎЁиҫҫејҸпјҢ然еҗҺеңЁиөӢеҖјж“ҚдҪңеҜ№еә”зҡ„RuleдёҠеҸій”®пјҢеҸҜйҖүжӢ©жөӢиҜ•пјҡ
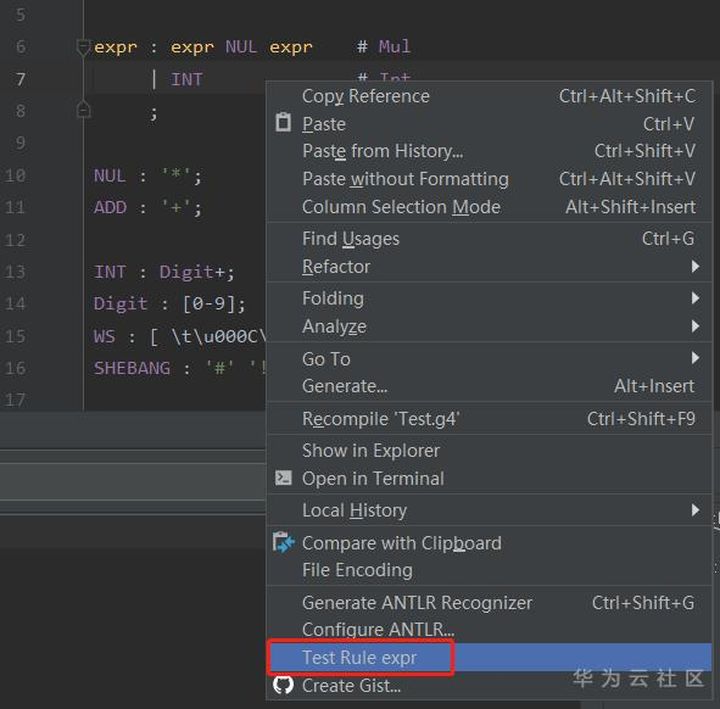
еҰӮдёҠеӣҫпјҢexpr иЎЁзӨәзҡ„жҳҜдёҖдёӘд№ҳжі•ж“ҚдҪңпјҢжүҖд»ҘжҲ‘们еҰӮдёӢжөӢиҜ•пјҡ
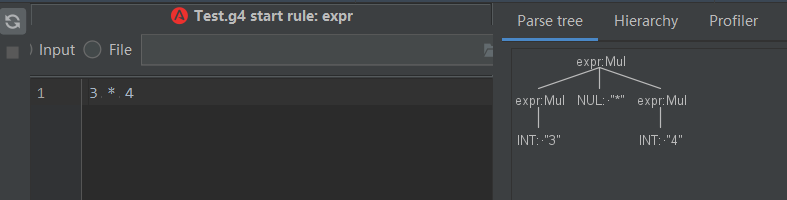
дҪҶжҳҜпјҢеҰӮжһңж”№жҲҗдёҖдёӘеҠ жі•ж“ҚдҪңпјҢеҲҷж— жі•иҜҶеҲ«пјҢеҸӘиғҪиҜҶеҲ«еҲ°з¬¬дёҖдёӘж•°еӯ—гҖӮ
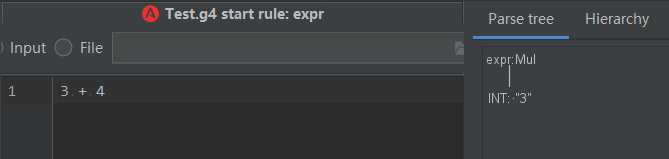
иҝҷз§Қжғ…еҶөдёӢпјҢе°ұйңҖиҰҒ继з»ӯжү©е…… exprзҡ„е®ҡд№үпјҢдё°еҜҢдёҚеҗҢзҡ„иҜӯжі•пјҢжқҘ继з»ӯж”ҜжҢҒе…¶д»–зҡ„иҜӯжі•пјҢеҰӮдёӢпјҡ
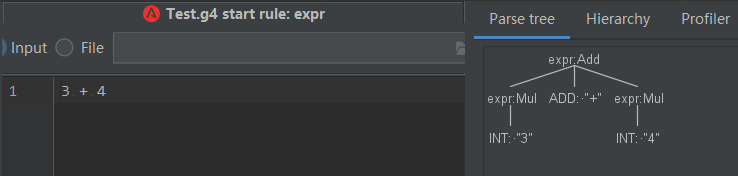
иҝҳеҸҜд»Ҙ继з»ӯжү©е……е…¶д»–зұ»еһӢзҡ„ж”ҜжҢҒпјҢиҝҷж ·дёҖжӯҘжӯҘе°Ҷж•ҙдёӘиҜӯиЁҖзҡ„иҜӯжі•йғҪж”ҜжҢҒе®Ңж•ҙгҖӮиҝҷйҮҢпјҢжҲ‘们еҪўжҲҗзҡ„дёҖдёӘе®Ңж•ҙзҡ„ж јејҸеҰӮдёӢпјҲиЎЁзӨәж•ҙеҪўж•°еӯ—зҡ„еҠ еҮҸд№ҳйҷӨпјүпјҡ
grammar Test;
@header {
package zmj.test.antlr4.parser;
}
stmt : expr;
expr : expr NUL expr # Mul
| expr ADD expr # Add
| expr DIV expr # Div
| expr MIN expr # Min
| INT # Int
;
NUL : '*';
ADD : '+';
DIV : '/';
MIN : '-';
INT : Digit+;
Digit : [0-9];
WS : [ \t\u000C\r\n]+ -> skip;
SHEBANG : '#' '!' ~('\n'|'\r')* -> channel(HIDDEN);4. Antlr4з”ҹжҲҗ并йҒҚеҺҶAST
4.1 з”ҹжҲҗжәҗз Ғж–Ү件
иҝҷдёҖжӯҘд»Ӣз»ҚдёӨз§Қз”ҹжҲҗи§ЈжһҗиҜӯжі•ж ‘зҡ„дёӨз§Қж–№жі•пјҢдҫӣеҸӮиҖғпјҡ
pom.xmlи®ҫзҪ®Antlr4 MavenжҸ’件пјҢеҸҜд»ҘйҖҡиҝҮжү§иЎҢ mvn generate-sourcesиҮӘеҠЁз”ҹжҲҗйңҖиҰҒзҡ„д»Јз ҒпјҲеҸӮиҖғй“ҫжҺҘпјҡ https://www.antlr.org/api/maven-plugin/latest/antlr4-mojo.htmlпјҢдё»иҰҒзҡ„ж„Ҹд№үеңЁдәҺпјҢд»Јз Ғе…Ҙеә“зҡ„ж—¶еҖҷпјҢдёҚйңҖиҰҒеҶҚе°Ҷз”ҹжҲҗзҡ„иҝҷдәӣиҜӯжі•ж–Ү件е…Ҙеә“пјҢеҮҸе°‘еә“йҮҢйқўзҡ„д»Јз ҒеҶ—дҪҷпјҢеҸӘеҢ…еҗ«иҮӘе·ұејҖеҸ‘зҡ„д»Јз ҒпјҢдёҚдјҡжңүиҮӘеҠЁз”ҹжҲҗзҡ„д»Јз ҒпјҢд№ҹдёҚйңҖиҰҒеҒҡclean codeж•ҙж”№пјүпјҢдёӢйқўжҳҜдёҖдёӘзӨәдҫӢпјҡ
<build>
<plugins>
<plugin>
<groupId>org.antlr</groupId>
<artifactId>antlr4-maven-plugin</artifactId>
<version>4.3</version>
<executions>
<execution>
<id>antlr</id>
<goals>
<goal>antlr4</goal>
</goals>
<phase>generate-sources</phase>
</execution>
</executions>
<configuration>
<sourceDirectory>${basedir}/src/main/resources</sourceDirectory>
<outputDirectory>${project.build.directory}/generated-sources/antlr4/zmj/test/antlr4/parser</outputDirectory>
<listener>true</listener>
<visitor>true</visitor>
<treatWarningsAsErrors>true</treatWarningsAsErrors>
</configuration>
</plugin>
</plugins>
</build>жҢүз…§дёҠйқўи®ҫзҪ®еҗҺпјҢеҸӘйңҖиҰҒжү§иЎҢ mvn generate-sources еҚіеҸҜеңЁmavenе·ҘзЁӢдёӯиҮӘеҠЁз”ҹжҲҗд»Јз ҒгҖӮ
дё»иҰҒеҸӮиҖғй“ҫжҺҘпјҲhttps://www.antlr.org/download.htmlпјүпјҢжңүжҜҸз§ҚиҜӯиЁҖзҡ„иҜӯжі•й…ҚзҪ®пјҢжҲ‘们иҝҷйҮҢиҖғиҷ‘дёӢиҪҪAntlr4е®Ңж•ҙjarпјҡ

дёӢиҪҪеҘҪеҗҺпјҲantlr-4.9-complete.jarпјү,еҸҜд»ҘдҪҝз”ЁеҰӮдёӢе‘Ҫд»ӨжқҘз”ҹжҲҗйңҖиҰҒзҡ„дҝЎжҒҜпјҡ
java -jar antlr-4.9-complete.jar -Dlanguage=Python3 -visitor Test.g4
иҝҷж ·е°ұеҸҜд»Ҙз”ҹжҲҗPython3 targetзҡ„жәҗз ҒпјҢж”ҜжҢҒзҡ„жәҗз ҒеҸҜд»Ҙд»ҺдёҠйқўй“ҫжҺҘжҹҘзңӢпјҢеҰӮжһңдёҚеёҢжңӣз”ҹжҲҗListenerпјҢеҸҜд»Ҙж·»еҠ еҸӮж•° -no-listener
4.2 и®ҝй—®иҖ…жЁЎејҸйҒҚеҺҶAntlr4иҜӯжі•ж ‘
Antlr4еңЁASTйҒҚеҺҶж—¶пјҢж”ҜжҢҒдёӨз§Қи®ҫи®ЎжЁЎејҸпјҡи®ҝй—®иҖ…и®ҫи®ЎжЁЎејҸ е’Ң зӣ‘еҗ¬еҷЁжЁЎејҸгҖӮ
еҜ№дәҺ и®ҝй—®иҖ…и®ҫи®ЎжЁЎејҸпјҢжҲ‘们йңҖиҰҒиҮӘе·ұе®ҡд№үеҜ№ AST зҡ„и®ҝй—®пјҲhttps://xie.infoq.cn/article/5f80da3c014fd69f8dbe09b28пјҢиҝҷжҳҜдёҖзҜҮй’ҲеҜ№и®ҝй—®иҖ…и®ҫи®ЎжЁЎејҸзҡ„д»Ӣз»ҚпјҢеӨ§е®¶еҸҜд»ҘеҸӮиҖғпјүгҖӮдёӢйқўзӣҙжҺҘйҖҡиҝҮд»Јз Ғеұ•зӨәи®ҝй—®иҖ…жЁЎејҸеңЁAntlr4дёӯдҪҝз”ЁпјҲеҹәдәҺ第3з« зҡ„дҫӢеӯҗпјүпјҡ
import org.antlr.v4.runtime.CharStream;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CommonTokenStream;
import zmj.test.antlr4.parser.TestBaseVisitor;
import zmj.test.antlr4.parser.TestLexer;
import zmj.test.antlr4.parser.TestParser;
public class App {
public static void main(String[] args) {
CharStream input = CharStreams.fromString("12*2+12");
TestLexer lexer=new TestLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
TestParser parser = new TestParser(tokens);
TestParser.ExprContext tree = parser.expr();
TestVisitor tv = new TestVisitor();
tv.visit(tree);
}
static class TestVisitor extends TestBaseVisitor<Void> {
@Override
public Void visitAdd(TestParser.AddContext ctx) {
System.out.println("========= test add");
System.out.println("first arg: " + ctx.expr(0).getText());
System.out.println("second arg: " + ctx.expr(1).getText());
return super.visitAdd(ctx);
}
}
}еҰӮдёҠпјҢmainж–№жі•дёӯпјҢи§ЈжһҗеҮәдәҶиЎЁиҫҫејҸзҡ„ASTз»“жһ„пјҢеҗҢж—¶еңЁжәҗз Ғдёӯд№ҹе®ҡд№үдәҶдёҖдёӘVisitorпјҡTestVisitorпјҢи®ҝй—®AddContextпјҢ并且жү“еҚ°иҜҘеҠ иЎЁиҫҫејҸзҡ„еүҚеҗҺдёӨдёӘиЎЁиҫҫејҸпјҢдёҠйқўдҫӢеӯҗзҡ„иҫ“еҮәдёәпјҡ
========= test add
first arg: 12*2
second arg: 12
4.2 зӣ‘еҗ¬еҷЁжЁЎејҸпјҲи§ӮеҜҹиҖ…жЁЎејҸпјү
еҜ№дәҺзӣ‘еҗ¬еҷЁжЁЎејҸпјҢе°ұжҳҜйҖҡиҝҮзӣ‘еҗ¬жҹҗеҜ№иұЎпјҢеҰӮжһңиҜҘеҜ№иұЎдёҠжңүзү№е®ҡзҡ„дәӢ件еҸ‘з”ҹпјҢеҲҷи§ҰеҸ‘иҜҘзӣ‘еҗ¬иЎҢдёәжү§иЎҢгҖӮжҜ”еҰӮжңүдёӘзӣ‘жҺ§пјҲзӣ‘еҗ¬еҷЁпјүпјҢзӣ‘жҺ§зҡ„жҳҜеӨ§й—ЁпјҲдәӢ件еҜ№иұЎпјүпјҢеҰӮжһңеҸ‘з”ҹдәҶй—Ҝй—Ёзҡ„иЎҢдёәпјҲдәӢ件жәҗпјүпјҢеҲҷиҝӣиЎҢжҠҘиӯҰпјҲи§ҰеҸ‘ж“ҚдҪңиЎҢдёәпјүгҖӮ
еңЁAntlr4дёӯпјҢеҰӮжһңдҪҝз”Ёзӣ‘еҗ¬еҷЁжЁЎејҸпјҢйҰ–е…ҲйңҖиҰҒејҖеҸ‘дёҖдёӘзӣ‘еҗ¬еҷЁпјҢиҜҘзӣ‘еҗ¬еҷЁеҸҜд»Ҙзӣ‘еҗ¬жҜҸдёӘASTиҠӮзӮ№пјҲдҫӢеҰӮиЎЁиҫҫејҸгҖҒиҜӯеҸҘзӯүпјүзҡ„дёҚеҗҢзҡ„иЎҢдёәпјҲдҫӢеҰӮиҝӣе…ҘиҜҘиҠӮзӮ№гҖҒз»“жқҹиҜҘиҠӮзӮ№пјүгҖӮеңЁдҪҝз”Ёж—¶пјҢAntlr4дјҡеҜ№з”ҹжҲҗзҡ„ASTиҝӣиЎҢйҒҚеҺҶпјҲParseTreeWalkerпјүпјҢеҰӮжһңйҒҚеҺҶеҲ°жҹҗдёӘе…·дҪ“зҡ„иҠӮзӮ№пјҢ并且жү§иЎҢдәҶзү№е®ҡиЎҢдёәпјҢе°ұдјҡи§ҰеҸ‘зӣ‘еҗ¬еҷЁзҡ„дәӢ件гҖӮ
зӣ‘еҗ¬еҷЁж–№жі•жҳҜжІЎжңүиҝ”еӣһеҖјзҡ„пјҲеҚіиҝ”еӣһзұ»еһӢжҳҜvoidпјүгҖӮеӣ жӯӨйңҖиҰҒдёҖз§ҚйўқеӨ–зҡ„ж•°жҚ®з»“жһ„пјҲеҸҜд»ҘйҖҡиҝҮMapжҲ–иҖ…ж ҲпјүжқҘеӯҳеӮЁеҪ“ж¬Ўзҡ„и®Ўз®—з»“жһңпјҢдҫӣдёӢдёҖж¬Ўи®Ўз®—и°ғз”ЁгҖӮ
дёҖиҲ¬жқҘиҜҙпјҢйқўеҗ‘зЁӢеәҸйқҷжҖҒеҲҶжһҗж—¶пјҢйғҪжҳҜдҪҝз”Ёи®ҝй—®иҖ…жЁЎејҸзҡ„пјҢеҫҲе°‘дҪҝз”Ёзӣ‘еҗ¬еҷЁжЁЎејҸпјҲж— жі•дё»еҠЁжҺ§еҲ¶йҒҚеҺҶASTзҡ„йЎәеәҸпјҢдёҚж–№дҫҝеңЁдёҚеҗҢиҠӮзӮ№йҒҚеҺҶд№Ӣй—ҙдј йҖ’ж•°жҚ®пјүпјҢз”Ёжі•еҜ№е’ұ们д№ҹдёҚеҸӢеҘҪпјҢжүҖд»Ҙжң¬ж–ҮдёҚд»Ӣз»Қзӣ‘еҗ¬еҷЁжЁЎејҸпјҢеҰӮжһңжңүе…ҙи¶ЈпјҢеҸҜд»ҘиҮӘе·ұжҗңзҙўжөӢиҜ•дҪҝз”ЁгҖӮ
5. Antlr4иҜҚжі•и§Јжһҗе’ҢиҜӯжі•и§Јжһҗ
иҝҷйғЁеҲҶе®һйҷ…дёҠпјҢз®—жҳҜAntlr4жңҖеҹәзЎҖзҡ„еҶ…е®№пјҢдҪҶжҳҜж”ҫеҲ°жңҖеҗҺдёҖйғЁеҲҶжқҘи®ІпјҢжңүзү№е®ҡзҡ„зӣ®зҡ„пјҢе°ұжҳҜжҺўи®ЁдёҖдёӢиҜҚжі•и§Јжһҗе’ҢиҜӯжі•и§Јжһҗзҡ„з•ҢйҷҗпјҢд»ҘеҸҠAntlr4зҡ„з»“жһңзҡ„еӨ„зҗҶгҖӮ
5.1 Antlr4жү§иЎҢйҳ¶ж®ө
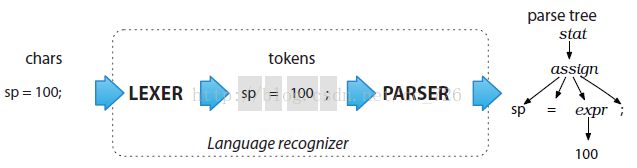
еҰӮеүҚйқўзҡ„иҜӯжі•е®ҡд№үпјҢеҲҶдёәLexerе’ҢParserпјҢе®һйҷ…дёҠиЎЁзӨәдәҶдёӨдёӘдёҚеҗҢзҡ„йҳ¶ж®өпјҡ
еҰӮдёӢеӣҫжүҖзӨәпјҡ
5.2 иҜҚжі•и§Јжһҗе’ҢиҜӯжі•и§Јжһҗзҡ„и°ғе’Ң
йҰ–е…ҲпјҢжҲ‘们еә”иҜҘжңүдёӘжҷ®йҒҚзҡ„и®ӨзҹҘпјҡиҜӯжі•и§ЈжһҗзӣёеҜ№дәҺиҜҚжі•и§ЈжһҗпјҢдјҡдә§з”ҹжӣҙеӨҡзҡ„ејҖй”ҖпјҢжүҖд»ҘпјҢеә”иҜҘе°ҪйҮҸе°ҶжҹҗдәӣеҸҜиғҪзҡ„еӨ„зҗҶеңЁиҜҚжі•и§Јжһҗйҳ¶ж®өе®ҢжҲҗпјҢеҮҸе°‘иҜӯжі•и§Јжһҗйҳ¶ж®өзҡ„ејҖй”ҖпјҢдё»иҰҒдёӢйқўзҡ„иҝҷдәӣдҫӢеӯҗпјҡ
еҗҲ并иҜӯиЁҖдёҚе…іеҝғзҡ„ж Үи®°пјҢдҫӢеҰӮпјҢжҹҗдәӣиҜӯиЁҖпјҲдҫӢеҰӮjsпјүдёҚеҢәеҲҶintгҖҒdoubleпјҢеҸӘжңү numberпјҢйӮЈд№ҲеңЁиҜҚжі•и§Јжһҗйҳ¶ж®өпјҢе°ұдёҚйңҖиҰҒе°Ҷintе’ҢdoubleеҢәеҲҶејҖпјҢз»ҹдёҖеҗҲ并дёәдёҖдёӘnumberпјӣ
з©әж јгҖҒжіЁйҮҠзӯүдҝЎжҒҜпјҢеҜ№дәҺиҜӯжі•и§Јжһҗе№¶ж— еӨ§зҡ„её®еҠ©пјҢеҸҜд»ҘеңЁиҜҚжі•еҲҶжһҗйҳ¶ж®өеү”йҷӨжҺүпјӣ
иҜёеҰӮж Үеҝ—з¬ҰгҖҒе…ій”®еӯ—гҖҒеӯ—з¬ҰдёІе’Ңж•°еӯ—иҝҷж ·зҡ„еёёз”Ёи®°еҸ·пјҢеқҮеә”иҜҘеңЁиҜҚжі•и§Јжһҗж—¶е®ҢжҲҗпјҢиҖҢдёҚиҰҒеҲ°иҜӯжі•и§Јжһҗйҳ¶ж®өеҶҚиҝӣиЎҢгҖӮ
дҪҶжҳҜпјҢиҝҷж ·зҡ„ж“ҚдҪңеңЁиҠӮзңҒдәҶиҜӯжі•еҲҶжһҗзҡ„ејҖй”Җд№ӢеӨ–пјҢе…¶е®һеҜ№жҲ‘们д№ҹдә§з”ҹдәҶдёҖдәӣеҪұе“Қпјҡ
иҷҪ然иҜӯиЁҖдёҚеҢәеҲҶзұ»еһӢпјҢдҫӢеҰӮеҸӘжңү numberпјҢжІЎжңү int е’Ң double зӯүпјҢдҪҶжҳҜйқўеҗ‘йқҷжҖҒд»Јз ҒеҲҶжһҗпјҢжҲ‘们еҸҜиғҪйңҖиҰҒзҹҘйҒ“зЎ®еҲҮзҡ„зұ»еһӢжқҘеё®еҠ©еҲҶжһҗзү№е®ҡзҡ„зјәйҷ·пјӣ
иҷҪ然注йҮҠеҜ№д»Јз Ғеё®еҠ©дёҚеӨ§пјҢдҪҶжҳҜжҲ‘们жңүж—¶еҖҷд№ҹйңҖиҰҒи§ЈжһҗжіЁйҮҠзҡ„еҶ…е®№жқҘиҝӣиЎҢеҲҶжһҗпјҢеҰӮжһңж— жі•еңЁиҜӯжі•и§Јжһҗзҡ„ж—¶еҖҷиҺ·еҸ–пјҢйӮЈд№Ҳе°ұйңҖиҰҒйҒҚеҺҶTokenпјҢд»ҺиҖҢеҜјиҮҙйқҷжҖҒд»Јз ҒеҲҶжһҗејҖй”ҖжӣҙеӨ§зӯүпјӣ
вҖҰ
иҝҷж ·зҡ„дёҖдәӣй—®йўҳиҜҘеҰӮдҪ•еӨ„зҗҶе‘ўпјҹ
5.3 и§Јжһҗж ‘vsиҜӯжі•ж ‘
еӨ§йғЁеҲҶзҡ„иө„ж–ҷдёӯпјҢйғҪжҠҠAntlr4з”ҹжҲҗзҡ„ж ‘зҠ¶з»“жһ„пјҢз§°дёәи§Јжһҗж ‘жҲ–иҖ…жҳҜиҜӯжі•ж ‘пјҢдҪҶжҳҜпјҢеҰӮжһңжҲ‘们з»Ҷ究зҡ„иҜқпјҢеҸҜиғҪиҜҙжҲҗжҳҜи§Јжһҗж ‘жӣҙеҠ еҮҶзЎ®пјҢеӣ дёәAntlr4зҡ„з»“жһңпјҢеҸӘжҳҜз®ҖеҚ•зҡ„ж–Үжі•и§ЈжһҗпјҢдёҚиғҪз§°д№ӢдёәиҜӯжі•ж ‘пјҲиҜӯжі•ж ‘еә”иҜҘжҳҜиғҪеӨҹдҪ“зҺ°еҮәжқҘиҜӯжі•зү№жҖ§зҡ„дҝЎжҒҜпјүпјҢеҰӮдёҠйқўзҡ„йӮЈдәӣй—®йўҳпјҢе°ұеҫҲйҡҫеңЁAntlr4з”ҹжҲҗзҡ„и§Јжһҗж ‘дёҠиҺ·еҸ–еҲ°гҖӮ
жүҖд»ҘпјҢзҺ°еңЁеҫҲеӨҡе·Ҙе…·пјҢеҹәдәҺAntlr4иҝӣиЎҢе°ҒиЈ…пјҢ然еҗҺиҝӣиЎҢдәҶжӣҙиҝӣдёҖжӯҘең°еӨ„зҗҶпјҢд»ҺиҖҢиҺ·еҸ–еҲ°дәҶжӣҙеҠ дё°еҜҢзҡ„иҜӯжі•ж ‘пјҢдҫӢеҰӮCheckStyleгҖӮеӣ жӯӨпјҢеҰӮжһңйҖҡиҝҮAntlr4и§ЈжһҗиҜӯиЁҖз®ҖеҚ•дҪҝз”ЁпјҢеҸҜд»ҘзӣҙжҺҘеҹәдәҺAntlr4зҡ„з»“жһңејҖеҸ‘пјҢдҪҶжҳҜеҰӮжһңиҰҒиҝӣиЎҢжӣҙеҠ ж·ұе…Ҙзҡ„еӨ„зҗҶпјҢе°ұйңҖиҰҒеҜ№Antlr4зҡ„з»“жһңиҝӣиЎҢжӣҙиҝӣдёҖжӯҘзҡ„еӨ„зҗҶпјҢд»Ҙжӣҙз¬ҰеҗҲжҲ‘们зҡ„дҪҝз”Ёд№ жғҜпјҲдҫӢеҰӮпјҢJava Parserж јејҸзҡ„Javaзҡ„ASTпјҢClangж јејҸзҡ„C/C++зҡ„ASTпјүпјҢ然еҗҺжүҚиғҪжӣҙеҘҪең°еңЁдёҠйқўиҝӣиЎҢејҖеҸ‘гҖӮ
еҲ°жӯӨпјҢзӣёдҝЎеӨ§е®¶еҜ№вҖңд»Җд№ҲжҳҜAntlr4вҖқжңүдәҶжӣҙж·ұзҡ„дәҶи§ЈпјҢдёҚеҰЁжқҘе®һйҷ…ж“ҚдҪңдёҖз•Әеҗ§пјҒиҝҷйҮҢжҳҜдәҝйҖҹдә‘зҪ‘з«ҷпјҢжӣҙеӨҡзӣёе…іеҶ…е®№еҸҜд»Ҙиҝӣе…Ҙзӣёе…ійў‘йҒ“иҝӣиЎҢжҹҘиҜўпјҢе…іжіЁжҲ‘们пјҢ继з»ӯеӯҰд№ пјҒ





