这篇文章主要讲解了“总结一次CPU占用1600%问题的定位过程”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“总结一次CPU占用1600%问题的定位过程”吧!
经过一次稍微大的改版后,系统上线,上线后测试没发现问题,第二天反馈系统卡顿,下线。
检查系统问题 ,优化接口速度 上线,上线后发现没问题,第二天依旧出现卡顿。此时观察CPU占用1600%.此时想到的时先回滚。没有保留现场。
测试环境测试,发现cpu空闲时占用100% 找到问题 修复。但是可以确定,这里100%不是引起1600%的原因。
再次上线,人工实时监控cpu占用率。此时出现了1600%的情况。此时占用cpu 1600%的进程对应的线程如下.

6619 6625 等是占用最高的进程Id.
对JVM栈信息进行打印 并输出到文件。
6619转成16进制后为19db 根据进程号在栈文件中搜 如下图所示 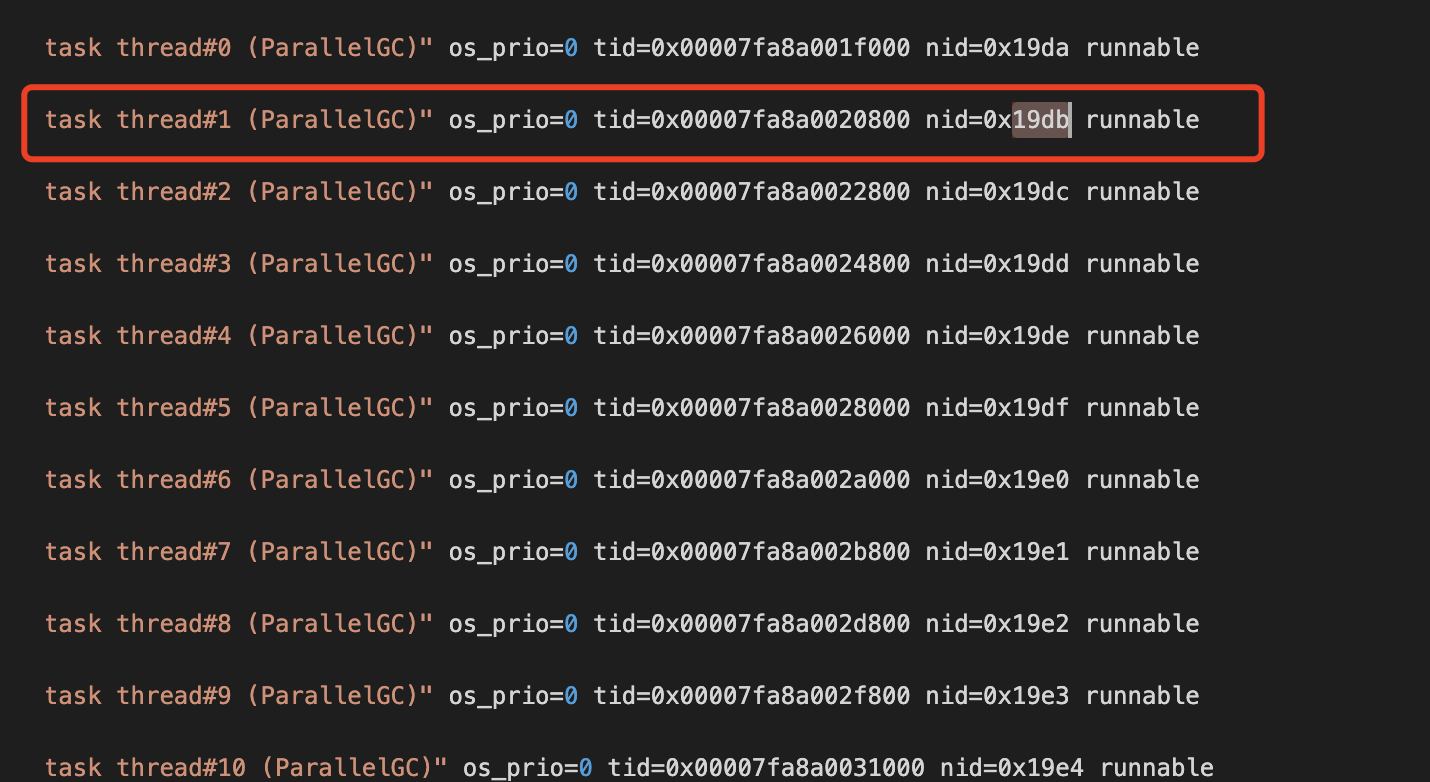
最后发现占用cpu高的全部为gc进程 ,此时可以判定。有部分代码逻辑内存占用过高。或者出现内存泄漏。
此时已经连续三次上线失败,没办法在从线上测试。那么想的是在灰度环境模拟这个现象 然后dump堆信息 这样肯定可以找到原因。
第一天 转移很少一部其他系统流量,以及很少一部分用户流量过去,没发现问题。
第二天 其他系统请求的流量保持不变,增加更多的用户流量,没有复现问题。
第三天 增加部分其他系统请求的流量,没有复现问题。
第n天 增加其他系统请求的流量 内存调整小,没有复现问题。
第n+1天 灰度环境服务与正式环境平分流量,继续增加用户量。没出现问题。
此时核心流程代码修改过的部分 已经检查了n遍 没发现问题。
那么 需要思考一下,为什么灰度环境没有问题。而线上有问题。他们的用户有什么不同?
此时发现灰度环境全是权限最低的用户,而管理员没有在灰度环境上工作,想到这里 问题已经离真相很近了。可以说已经定位到问题所在了,只需要验证一下自己的猜想。
其中有个功能,是查看自己所管理人的数据,这个功能因为不是核心功能 ,并且请求的量很小很小,起初并没有向这个方向考虑。
逻辑是 : 查找自己下一级别,如果有数据,在继续查找,恰好 数据库有一条异常的数据 ,他的下一级就是自己! 导致产生了死循环,导致内存里的数据越来越多。
又因为是IO密集的操作,所以 这个循环占用的cpu很低。在线程栈中并没有发现他。
找到问题解决就是很容易的事情了,不再详细描述。
第一次系统出现卡顿,正确的处理方式大概应该如下
发现cpu占用高,查看该进程对应的线程在执行什么操作
发现大量的线程在执行gc操作,此时应该dump堆信息
使用jmap等工具查看哪些对象占用内存占用高
找到对应代码 解决问题
这种bug不应该存在,即使存在了出现问题也不要太慌 应该快速的保留能保留下来的信息。
大的改动上线前需要灰度发布,少量用户先使用。
感谢各位的阅读,以上就是“总结一次CPU占用1600%问题的定位过程”的内容了,经过本文的学习后,相信大家对总结一次CPU占用1600%问题的定位过程这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/wang520/blog/4899718



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



