这篇文章将为大家详细讲解有关hadoop和hive如何安装,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
一、环境准备篇
vmware虚拟机安装两个centos7服务器(这里介绍一下vmware虚拟机设置固定ip)
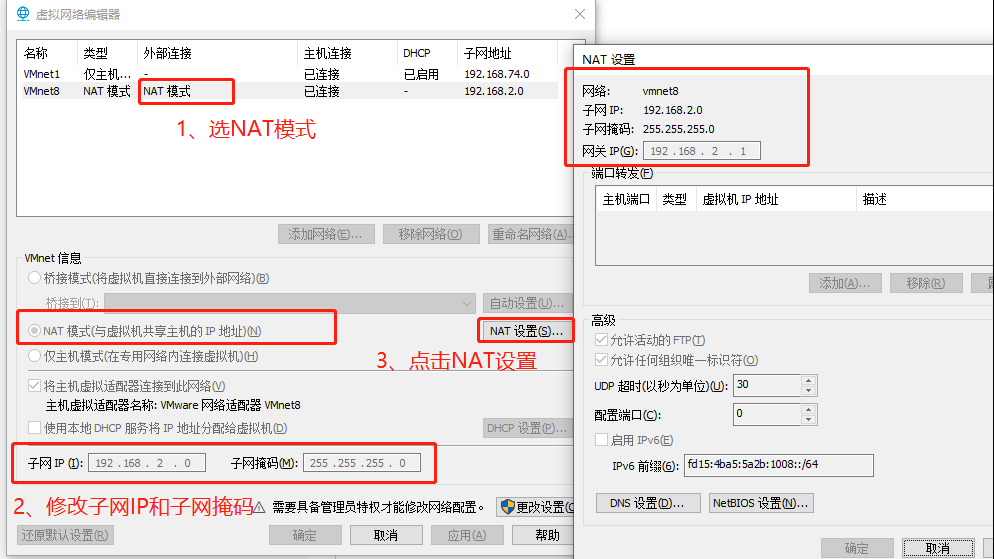
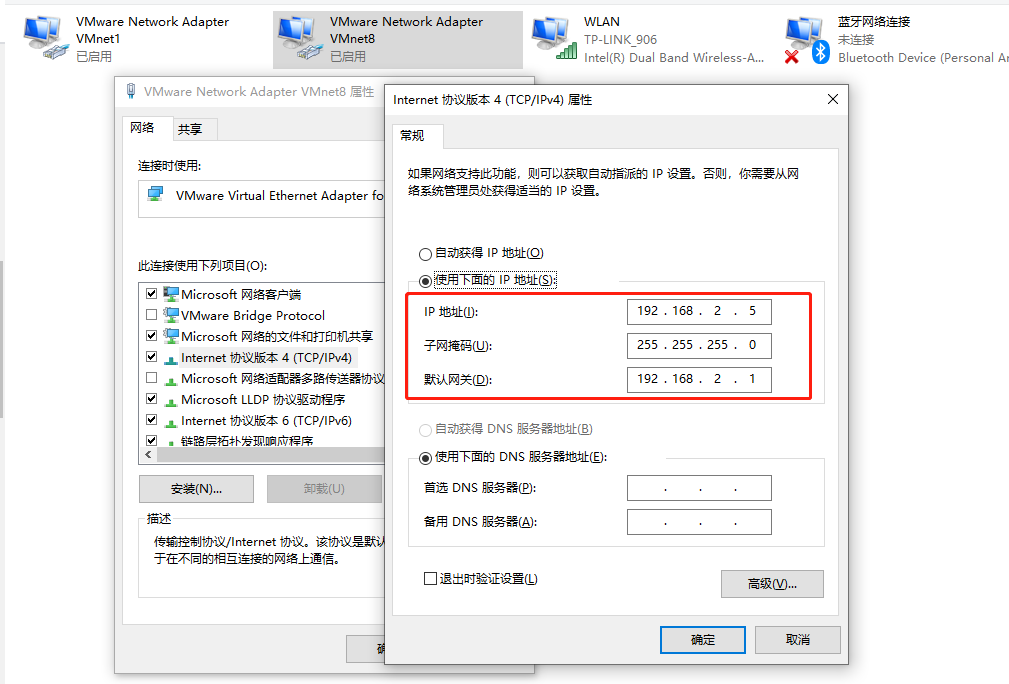
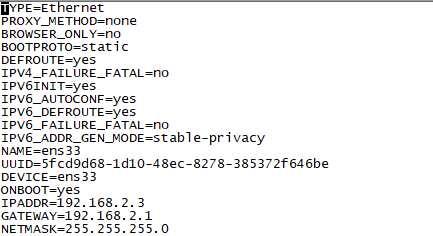
这样vmware虚拟机固定ip网络就搭建好了,搭建Hadoop机器说明:主:192.168.2.2,从192.168.2.3(虚拟机一开始要设置固定ip) 两个服务器上的/etc/hosts如下: 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 192.168.2.2 master 192.168.2.3 slave0
二、hadoop安装包下载部署,下载地址: http://archive.apache.org/dist/hadoop/core/hadoop-2.7.5/
1、cd /data/software/
2、rz -y
3、tar -zxvf hadoop-2.7.5.tar.gz /usr/local/
4、mv hadoop-2.7.5 hadoop
5、vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh
找到export JAVA_HOME,修改为export JAVA_HOME=/usr/local/jdk1.8.0_251
6、 vi /usr/local/hadoop/etc/hadoop/core-site.xml需要在<configuration>和</configuration>之间加入的代码:
<!--指定namenode的地址--><property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoopdata</value>
</property>
7、vi /usr/local/hadoop/etc/hadoop/hdfs-site.xml
需要在<configuration>和</configuration>之间加入的代码:
<!--指定hdfs保存数据的副本数量--><property>
<name>dfs.replication</name>
<value>1</value>
</property>
8、vi /usr/local/hadoop/etc/hadoop/yarn-site.xml需要在<configuration>和</configuration>之间加入的代码:<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
9、cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
vi /usr/local/hadoop/etc/hadoop/mapred-site.xml需要在<configuration>和</configuration>之间加入的代码:
<!--告诉hadoop以后MR运行在yarn上--><property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
10、vi /opt/hadoop/hadoop/etc/hadoop/slaves
slave0
slave1
11、scp -r /usr/local/hadoop root@slave0:/usr/local
12、cd /usr/local/hadoop(两个节点都做)
vi ~/.bash_profile
export HADOOP_HOME=/usr/local/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source ~/.bash_profile
13、mkdir /opt/hadoop/hadoopdata
hadoop namenode -format
14、cd /usr/local/hadoop/sbin
start-all.sh
stop-all.sh在13做完以后需要创建hadoop用户,hadoop组,然后使用chown命令将/usr/local/hadoop授权给hadoop组下的Hadoop用户,检查两个服务器上的进程,进程明细如下:
192.168.2.2主节点
18784 SecondaryNameNode
18579 NameNode
18942 ResourceManager
21726 Jps
192.168.2.3从节点
129605 NodeManager
1445 Jps
129480 DataNode如果从节点上datanode没有启动,可以查看从节点上datanode日志,日志目录 :/usr/local/hadoop/logs/hadoop-hadoop-datanode-slave0.log
cd /usr/local/hadoop/bin
echo "abc" file.txt
ls -l
./hdfs dfs -ls /
./hdfs dfs -put file.txt /这样就上传了一个文件到hdfs中,可以打开地址http://192.168.2.2:50070/查看根目录下是否存在file.txt
三、hive安装包下载部署,下载地址: http://mirror.bit.edu.cn/apache/hive/
1、 tar -zxvf apache-hive-2.1.1-bin.tar.gz -C /usr/local/
2、 mv apache-hive-2.1.1-bin hive
3、 vi /etc/profile
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
source /etc.profile
4、cd /usr/local/hive/conf/
vi hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.2.2:3306/hivedb?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>1234</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>hive default warehouse, if nessecory, change it</description>
</property>
</configuration>
5、复制mysql的驱动程序到hive/lib下面
6、cd /usr/local/hive/bin
schematool -dbType mysql -initSchema
7、执行hive命令
create database test_workcreate table course (id int,name string);8、查询hadoop目录
hadoop fs -lsr /
drwxr-xr-x - hadoop supergroup 0 2020-08-28 22:53 /user
drwxr-xr-x - hadoop supergroup 0 2020-08-28 22:53 /user/hive
drwxr-xr-x - hadoop supergroup 0 2020-08-28 22:53 /user/hive/warehouse
drwxr-xr-x - hadoop supergroup 0 2020-08-28 22:53 /user/hive/warehouse/test_work.db
drwxr-xr-x - hadoop supergroup 0 2020-08-28 22:54 /user/hive/warehouse/test_work.db/course
9、查询hivedb数据库的DBS、TBLS差异关于“hadoop和hive如何安装”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/3769440/blog/4535240



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



