本篇文章给大家分享的是有关如何解析Pytorch转ONNX的理论分析,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
(1)Pytorch转ONNX的意义
一般来说转ONNX只是一个手段,在之后得到ONNX模型后还需要再将它做转换,比如转换到TensorRT上完成部署,或者有的人多加一步,从ONNX先转换到caffe,再从caffe到tensorRT。原因是Caffe对tensorRT更为友好,这里关于友好的定义后面会谈。
因此在转ONNX工作开展之前,首先必须明确目标后端。ONNX只是一个格式,就和json一样。只要你满足一定的规则,都算是合法的,因此单纯从Pytorch转成一个ONNX文件很简单。但是不同后端设备接受的onnx是不一样的,因此这才是坑的来源。
Pytorch自带的torch.onnx.export转换得到的ONNX,ONNXRuntime需要的ONNX,TensorRT需要的ONNX都是不同的。
这里面举一个最简单的Maxpool的例:
Maxunpool可以被看作Maxpool的逆运算,咱们先来看一个Maxpool的例子,假设有如下一个C*H*W的tensor(shape[2, 3, 3]),其中每个channel的二维矩阵都是一样的,如下所示

在这种情况下,如果我们在Pytorch对它调用MaxPool(kernel_size=2, stride=1,pad=0)
那么会得到两个输出,第一个输出是Maxpool之后的值:

另一个是Maxpool的Idx,即每个输出对应原来的哪个输入,这样做反向传播的时候就可以直接把输出的梯度传给对应的输入:

细心的同学会发现其实Maxpool的Idx还可以有另一种写法:
 ,
,
即每个channel的idx放到一起,并不是每个channel单独从0开始。这两种写法都没什么问题,毕竟只要反向传播的时候一致就可以。
但是当我在支持OpenMMEditing的时候,会涉及到Maxunpool,即Maxpool的逆运算:输入MaxpoolId和Maxpool的输出,得到Maxpool的输入。
Pytorch的MaxUnpool实现是接收每个channel都从0开始的Idx格式,而Onnxruntime则相反。因此如果你希望用Onnxruntime跑一样的结果,那么必须对输入的Idx(即和Pytorch一样的输入)做额外的处理才可以。换言之,Pytorch转出来的神经网络图和ONNXRuntime需要的神经网络图是不一样的。
(2)ONNX与Caffe
主流的模型部署有两种路径,以TensorRT为例,一种是Pytorch->ONNX->TensorRT,另一种是Pytorch->Caffe->TensorRT。个人认为目前后者更为成熟,这主要是ONNX,Caffe和TensorRT的性质共同决定的
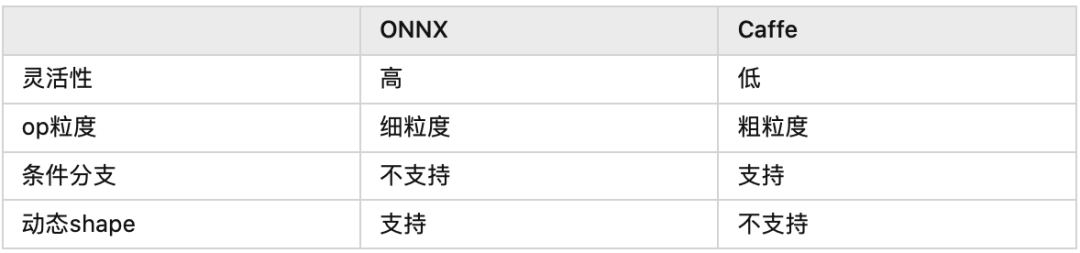
上面的表列了ONNX和Caffe的几点区别,其中最重要的区别就是op的粒度。举个例子,如果对Bert的Attention层做转换,ONNX会把它变成MatMul,Scale,SoftMax的组合,而Caffe可能会直接生成一个叫做Multi-Head Attention的层,同时告诉CUDA工程师:“你去给我写一个大kernel“(很怀疑发展到最后会不会把ResNet50都变成一个层。。。)
tensor i = funcA();if(i==0) j = funcB(i);else j = funcC(i);funcD(j);
tensor i = funcA();coarse_func(tensor i) { if(i==0) return funcB(i); else return funcC(i);}funcD(coarse_func(i))
以上就是如何解析Pytorch转ONNX的理论分析,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4586369/blog/4792607



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



