如何让Python爬取招聘网站数据并实现可视化交互大屏,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
随着科技的飞速发展,数据呈现爆发式的增长,任何人都摆脱不了与数据打交道,社会对于“数据”方面的人才需求也在不断增大。因此了解当下企业究竟需要招聘什么样的人才?需要什么样的技能?不管是对于在校生,还是对于求职者来说,都显得很有必要。
本文基于这个问题,针对51job招聘网站,爬取了全国范围内大数据、数据分析、数据挖掘、机器学习、人工智能等相关岗位的招聘信息。分析比较了不同岗位的薪资、学历要求;分析比较了不同区域、行业对相关人才的需求情况;分析比较了不同岗位的知识、技能要求等。
做完以后的项目效果如下:
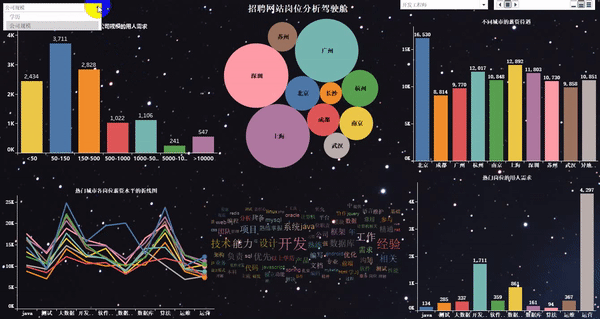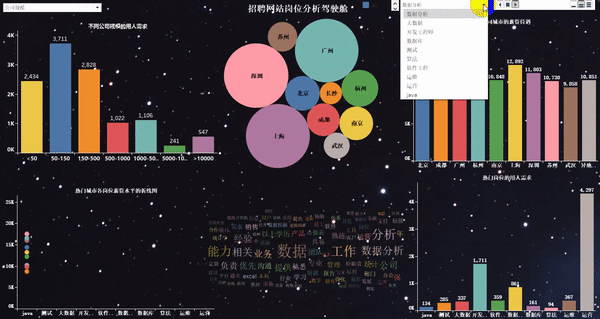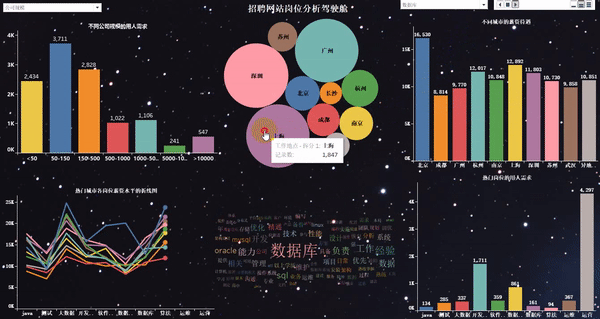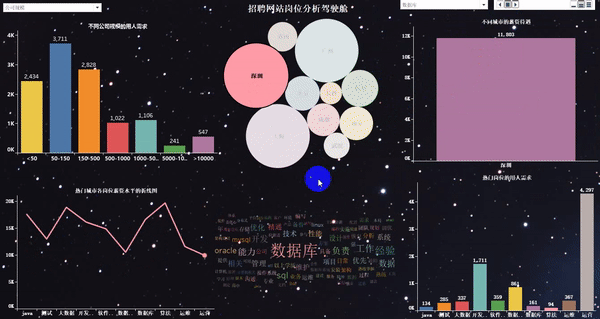
爬取岗位:大数据、数据分析、机器学习、人工智能等相关岗位;
爬取字段:公司名、岗位名、工作地址、薪资、发布时间、工作描述、公司类型、员工人数、所属行业;
说明:基于51job招聘网站,我们搜索全国对于“数据”岗位的需求,大概有2000页。我们爬取的字段,既有一级页面的相关信息,还有二级页面的部分信息;
爬取思路:先针对某一页数据的一级页面做一个解析,然后再进行二级页面做一个解析,最后再进行翻页操作;
使用工具:Python+requests+lxml+pandas+time
网站解析方式:Xpath
1、导入相关库
import requests
import pandas as pd
from pprint import pprint
from lxml import etree
import time
import warnings
warnings.filterwarnings("ignore")2、关于翻页的说明
# 第一页的特点
https://search.51job.com/list/000000,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE,2,1.html?
# 第二页的特点
https://search.51job.com/list/000000,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE,2,2.html?
# 第三页的特点
https://search.51job.com/list/000000,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE,2,3.html?注意:通过对于页面的观察,可以看出,就一个地方的数字变化了,因此只需要做字符串拼接,然后循环爬取即可。
3、完整的爬取代码
import requests
import pandas as pd
from pprint import pprint
from lxml import etree
import time
import warnings
warnings.filterwarnings("ignore")
for i in range(1,1501):
print("正在爬取第">这里可以看到,我们爬取了1000多页的数据做最终的分析。因此每爬取一页的数据,做一次数据存储,避免最终一次性存储导致失败。同时根据自己的测试,有一些页数进行数据存储,会导致失败,为了不影响后面代码的执行,我们使用了“try-except”异常处理。
在一级页面中,我们爬取了“岗位名称”,“公司名称”,“工作地点”,“工资”,“发布日期”,“二级网址的url”这几个字段。
在二级页面中,我们爬取了“经验、学历信息”,“岗位描述”,“公司类型”,“公司规模”,“所属行业”这几个字段。
从爬取到的数据中截取部分做了一个展示,可以看出数据很乱。杂乱的数据并不利于我们的分析,因此需要根据研究的目标做一个数据预处理,得到我们最终可以用来做可视化展示的数据。
1、相关库的导入及数据的读取
df = pd.read_csv(r"G:\8泰迪\python_project\51_job\job_info1.csv",engine="python",header=None)
# 为数据框指定行索引
df.index = range(len(df))
# 为数据框指定列索引
df.columns = ["岗位名","公司名","工作地点","工资","发布日期","经验与学历","公司类型","公司规模","行业","工作描述"]2、数据去重
我们认为一个公司的公司名和和发布的岗位名一致,就看作是重复值。因此,使用drop_duplicates(subset=[])函数,基于“岗位名”和“公司名”做一个重复值的剔除。
# 去重之前的记录数
print("去重之前的记录数",df.shape)
# 记录去重
df.drop_duplicates(subset=["公司名","岗位名"],inplace=True)
# 去重之后的记录数
print("去重之后的记录数",df.shape)3、岗位名字段的处理
① 岗位名字段的探索
df["岗位名"].value_counts()
df["岗位名"] = df["岗位名"].apply(lambda x:x.lower())说明:首先我们对每个岗位出现的频次做一个统计,可以看出“岗位名字段”太杂乱,不便于我们做统计分析。接着我们将岗位名中的大写英文字母统一转换为小写字母,也就是说“AI”和“Ai”属于同一个东西。
② 构造想要分析的目标岗位,做一个数据筛选
job_list = ['数据分析', "数据统计","数据专员",'数据挖掘', '算法',
'大数据','开发工程师', '运营', '软件工程', '前端开发',
'深度学习', 'ai', '数据库', '数据库', '数据产品',
'客服', 'java', '.net', 'andrio', '人工智能', 'c++',
'数据管理',"测试","运维"]
job_list = np.array(job_list)
def rename(x=None,job_list=job_list):
index = [i in x for i in job_list]
if sum(index) > 0:
return job_list[index][0]
else:
return x
job_info["岗位名"] = job_info["岗位名"].apply(rename)
job_info["岗位名"].value_counts()
# 数据统计、数据专员、数据分析统一归为数据分析
job_info["岗位名"] = job_info["岗位名"].apply(lambda x:re.sub("数据专员","数据分析",x))
job_info["岗位名"] = job_info["岗位名"].apply(lambda x:re.sub("数据统计","数据分析",x))说明:首先我们构造了如上七个目标岗位的关键字眼。然后利用count()函数统计每一条记录中,是否包含这七个关键字眼,如果包含就保留这个字段,不过不包含就删除这个字段。最后查看筛选之后还剩余多少条记录。
③ 目标岗位标准化处理(由于目标岗位太杂乱,我们需要统一一下)
job_list = ['数据分析', "数据统计","数据专员",'数据挖掘', '算法',
'大数据','开发工程师', '运营', '软件工程', '前端开发',
'深度学习', 'ai', '数据库', '数据库', '数据产品',
'客服', 'java', '.net', 'andrio', '人工智能', 'c++',
'数据管理',"测试","运维"]
job_list = np.array(job_list)
def rename(x=None,job_list=job_list):
index = [i in x for i in job_list]
if sum(index) > 0:
return job_list[index][0]
else:
return x
job_info["岗位名"] = job_info["岗位名"].apply(rename)
job_info["岗位名"].value_counts()
# 数据统计、数据专员、数据分析统一归为数据分析
job_info["岗位名"] = job_info["岗位名"].apply(lambda x:re.sub("数据专员","数据分析",x))
job_info["岗位名"] = job_info["岗位名"].apply(lambda x:re.sub("数据统计","数据分析",x))说明:首先我们定义了一个想要替换的目标岗位job_list,将其转换为ndarray数组。然后定义一个函数,如果某条记录包含job_list数组中的某个关键词,那么就将该条记录替换为这个关键词,如果某条记录包含job_list数组中的多个关键词,我们只取第一个关键词替换该条记录。接着使用value_counts()函数统计一下替换后的各岗位的频次。最后,我们将“数据专员”、“数据统计”统一归为“数据分析”。
4、工资水平字段的处理
工资水平字段的数据类似于“20-30万/年”、“2.5-3万/月”和“3.5-4.5千/月”这样的格式。我们需要做一个统一的变化,将数据格式转换为“元/月”,然后取出这两个数字,求一个平均值。
job_info["工资"].str[-1].value_counts()
job_info["工资"].str[-3].value_counts()
index1 = job_info["工资"].str[-1].isin(["年","月"])
index2 = job_info["工资"].str[-3].isin(["万","千"])
job_info = job_info[index1 & index2]
def get_money_max_min(x):
try:
if x[-3] == "万":
z = [float(i)*10000 for i in re.findall("[0-9]+\.?[0-9]*",x)]
elif x[-3] == "千":
z = [float(i) * 1000 for i in re.findall("[0-9]+\.?[0-9]*", x)]
if x[-1] == "年":
z = [i/12 for i in z]
return z
except:
return x
salary = job_info["工资"].apply(get_money_max_min)
job_info["最低工资"] = salary.str[0]
job_info["最高工资"] = salary.str[1]
job_info["工资水平"] = job_info[["最低工资","最高工资"]].mean(axis=1)说明:首先我们做了一个数据筛选,针对于每一条记录,如果最后一个字在“年”和“月”中,同时第三个字在“万”和“千”中,那么就保留这条记录,否则就删除。接着定义了一个函数,将格式统一转换为“元/月”。最后将最低工资和最高工资求平均值,得到最终的“工资水平”字段。
5、工作地点字段的处理
由于整个数据是关于全国的数据,涉及到的城市也是特别多。我们需要自定义一个常用的目标工作地点字段,对数据做一个统一处理。
#job_info["工作地点"].value_counts()
address_list = ['北京', '上海', '广州', '深圳', '杭州', '苏州', '长沙',
'武汉', '天津', '成都', '西安', '东莞', '合肥', '佛山',
'宁波', '南京', '重庆', '长春', '郑州', '常州', '福州',
'沈阳', '济南', '宁波', '厦门', '贵州', '珠海', '青岛',
'中山', '大连','昆山',"惠州","哈尔滨","昆明","南昌","无锡"]
address_list = np.array(address_list)
def rename(x=None,address_list=address_list):
index = [i in x for i in address_list]
if sum(index) > 0:
return address_list[index][0]
else:
return x
job_info["工作地点"] = job_info["工作地点"].apply(rename)说明:首先我们定义了一个目标工作地点列表,将其转换为ndarray数组。接着定义了一个函数,将原始工作地点记录,替换为目标工作地点中的城市。
6、公司类型字段的处理
这个很容易,就不详细说明了。
job_info.loc[job_info["公司类型"].apply(lambda x:len(x)<6),"公司类型"] = np.nan
job_info["公司类型"] = job_info["公司类型"].str[2:-2]7、行业字段的处理
每个公司的行业字段可能会有多个行业标签,但是我们默认以第一个作为该公司的行业标签。
# job_info["行业"].value_counts()
job_info["行业"] = job_info["行业"].apply(lambda x:re.sub(",","/",x))
job_info.loc[job_info["行业"].apply(lambda x:len(x)<6),"行业"] = np.nan
job_info["行业"] = job_info["行业"].str[2:-2].str.split("/").str[0]8、经验与学历字段的处理
关于这个字段的数据处理,我很是思考了一会儿,不太好叙述,放上代码自己下去体会。
job_info["学历"] = job_info["经验与学历"].apply(lambda x:re.findall("本科|大专|应届生|在校生|硕士",x))
def func(x):
if len(x) == 0:
return np.nan
elif len(x) == 1 or len(x) == 2:
return x[0]
else:
return x[2]
job_info["学历"] = job_info["学历"].apply(func)9、工作描述字段的处理
对于每一行记录,我们去除停用词以后,做一个jieba分词。
with open(r"G:\8泰迪\python_project\51_job\stopword.txt","r") as f:
stopword = f.read()
stopword = stopword.split()
stopword = stopword + ["任职","职位"," "]
job_info["工作描述"] = job_info["工作描述"].str[2:-2].apply(lambda x:x.lower()).apply(lambda x:"".join(x))\
.apply(jieba.lcut).apply(lambda x:[i for i in x if i not in stopword])
job_info.loc[job_info["工作描述"].apply(lambda x:len(x) < 6),"工作描述"] = np.nan10、公司规模字段的处理
#job_info["公司规模"].value_counts()
def func(x):
if x == "['少于50人']":
return "<50"
elif x == "['50-150人']":
return "50-150"
elif x == "['150-500人']":
return '150-500'
elif x == "['500-1000人']":
return '500-1000'
elif x == "['1000-5000人']":
return '1000-5000'
elif x == "['5000-10000人']":
return '5000-10000'
elif x == "['10000人以上']":
return ">10000"
else:
return np.nan
job_info["公司规模"] = job_info["公司规模"].apply(func)11、构造新数据
我们针对最终清洗干净的数据,选取需要分析的字段,做一个数据存储。
feature = ["公司名","岗位名","工作地点","工资水平","发布日期","学历","公司类型","公司规模","行业","工作描述"]
final_df = job_info[feature]
final_df.to_excel(r"G:\8泰迪\python_project\51_job\词云图.xlsx",encoding="gbk",index=None)由于我们之后需要针对不同的岗位名做不同的词云图处理,并且是在tableau中做可视化展示,因此我们需要按照岗位名分类,求出不同岗位下各关键词的词频统计。
import numpy as np
import pandas as pd
import re
import jieba
import warnings
warnings.filterwarnings("ignore")
df = pd.read_excel(r"G:\8泰迪\python_project\51_job\new_job_info1.xlsx",encoding="gbk")
df
def get_word_cloud(data=None, job_name=None):
words = []
describe = data['工作描述'][data['岗位名'] == job_name].str[1:-1]
describe.dropna(inplace=True)
[words.extend(i.split(',')) for i in describe]
words = pd.Series(words)
word_fre = words.value_counts()
return word_fre
zz = ['数据分析', '算法', '大数据','开发工程师', '运营', '软件工程','运维', '数据库','java',"测试"]
for i in zz:
word_fre = get_word_cloud(data=df, job_name='{}'.format(i))
word_fre = word_fre[1:].reset_index()[:100]
word_fre["岗位名"] = pd.Series("{}".format(i),index=range(len(word_fre)))
word_fre.to_csv(r"G:\8泰迪\python_project\51_job\词云图\bb.csv", mode='a',index=False, header=None,encoding="gbk")1、热门城市的用人需求TOP10
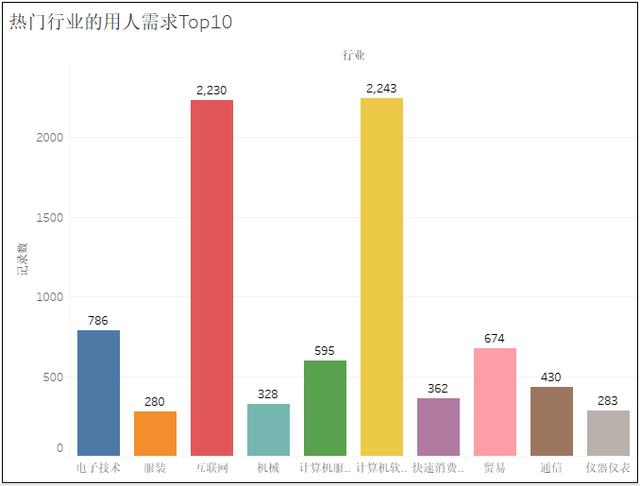
2、热门城市的岗位数量TOP10
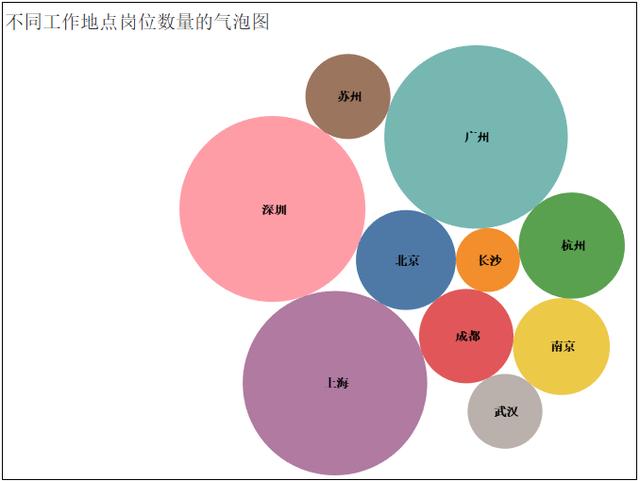
4、热门岗位的薪资待遇
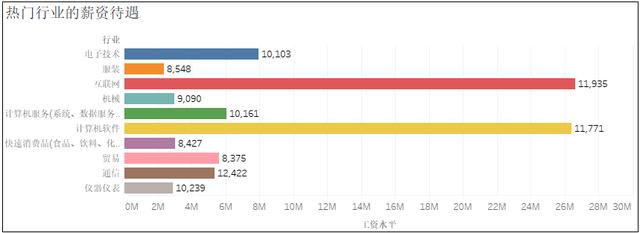
关于如何让Python爬取招聘网站数据并实现可视化交互大屏问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4848094/blog/4746073



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



