这篇文章主要介绍“python模拟逻辑斯蒂回归模型及最大熵模型举例分析”,在日常操作中,相信很多人在python模拟逻辑斯蒂回归模型及最大熵模型举例分析问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”python模拟逻辑斯蒂回归模型及最大熵模型举例分析”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
思想:用了新的回归函数y = 1/( exp(-x) ),其中x为分类函数,即w1*x1 + w2*x2 + ······ = 0。对于每一条样本数据,我们计算一次y,并求出误差△y;然后对权重向量w进行更新,更新策略为w = w + α*△y*x[i]' 其中α为学习率,△y为当前训练数据的误差,x[i]'为当前训练数据的转置;如此训返往复。
这个例子中是对次数加了限制,也可以对误差大小加以限制。
from math import exp
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# data
def create_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
data = np.array(df.iloc[:100, [0, 1, -1]])
# print(data)
return data[:, :2], data[:, -1]
class LogisticReressionClassifier:
def __init__(self, max_iter=200, learning_rate=0.01):
self.max_iter = max_iter # 对整个数据的最大训练次数
self.learning_rate = learning_rate # 学习率
def sigmoid(self, x): # 回归模型
return 1 / (1 + exp(-x))
# 对数据进行了整理,对原来的每行两列添加了一列,
# 因为我们的线性分类器:w1*x1 + w2*x2 + b*1.0
# 所以将原来的(x1, x2,)扩充为(x1, x2, 1.0)
def data_matrix(self, X):
data_mat = []
for d in X:
data_mat.append([1.0, *d])
return data_mat
def fit(self, X, y):
data_mat = self.data_matrix(X) # 处理训练数据
# 生成权重数组
# n行一列零数组,行数为data_mat[0]的长度
# 这里也就是我们的 w0,w1,w2
self.weights = np.zeros((len(data_mat[0]), 1), dtype=np.float32)
for iter_ in range(self.max_iter):
for i in range(len(X)): # 对每条X进行遍历
# dot函数返回数组的点乘,也就是矩阵乘法:一行乘一列
# 在这里就是将 向量w*向量x 传入回归模型
# 返回训练值
result = self.sigmoid(np.dot(data_mat[i], self.weights))
error = y[i] - result # 误差
# transpose是转置函数。改变权值
# w = w + 学习率*误差*向量x
self.weights += self.learning_rate * error * np.transpose([data_mat[i]])
print('逻辑斯谛回归模型训练完成(learning_rate={},max_iter={})'.format(
self.learning_rate, self.max_iter))
def score(self, X_test, y_test):
right = 0
X_test = self.data_matrix(X_test)
for x, y in zip(X_test, y_test):
result = np.dot(x, self.weights)
if (result > 0 and y == 1) or (result < 0 and y == 0):
right += 1
return right / len(X_test)
X, y = create_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
lr_clf = LogisticReressionClassifier()
lr_clf.fit(X_train, y_train)
print("评分:")
print(lr_clf.score(X_test, y_test))
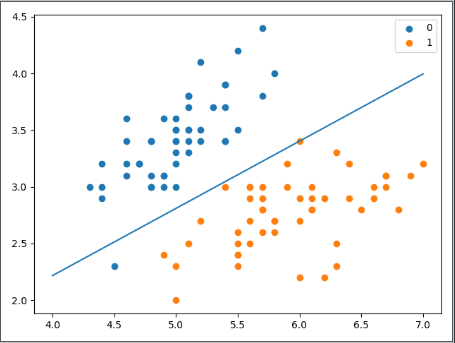
x_points = np.arange(4, 8)
# 原拟合函数为: w1*x1 + w2*x2 + b = 0
# 即 w1*x + w2*y + w0 = 0
y_ = -(lr_clf.weights[1]*x_points + lr_clf.weights[0])/lr_clf.weights[2]
plt.plot(x_points, y_)
plt.scatter(X[:50, 0], X[:50, 1], label='0')
plt.scatter(X[50:, 0], X[50:, 1], label='1')
plt.legend()
plt.show()结果如下:
逻辑斯谛回归模型训练完成(learning_rate=0.01,max_iter=200) 评分: 1.0
from math import exp
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
def create_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
data = np.array(df.iloc[:100, [0, 1, -1]])
# print(data)
return data[:, :2], data[:, -1]
X, y = create_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
clf = LogisticRegression(max_iter=200)
clf.fit(X_train, y_train)
print("socre:{}".format(clf.score(X_test, y_test)))
print(clf.coef_, clf.intercept_)
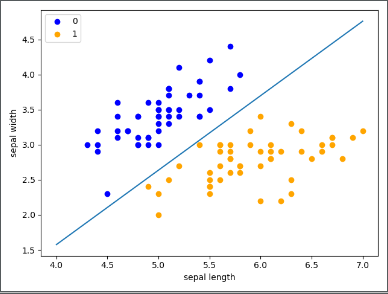
x_points = np.arange(4, 8)
y_ = -(clf.coef_[0][0]*x_points + clf.intercept_)/clf.coef_[0][1]
plt.plot(x_points, y_)
plt.plot(X[:50, 0], X[:50, 1], 'bo', color='blue', label='0')
plt.plot(X[50:, 0], X[50:, 1], 'bo', color='orange', label='1')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
plt.show()结果:
socre:1.0 [[ 2.72989376 -2.5726044 ]] [-6.86599549]
最大熵原理:在满足约束条件的模型集合中选取熵最大的模型。
思想比较简单,但公式太多,结合课本公式使用更佳
import math
from copy import deepcopy
# 深复制:将被复制的对象完全复制一份
# 浅复制:将被复制的对象打一个标签,两者改变其一,另一个随着改变
class MaxEntropy:
def __init__(self, EPS=0.005): # 参数为收敛条件
self._samples = [] # 存储我们的训练数据
self._Y = set() # 标签集合,相当于去重后的y
self._numXY = {} # key为(x,y),value为出现次数
self._N = 0 # 样本数
self._Ep_ = [] # 样本分布的特征期望值
self._xyID = {} # key记录(x,y),value记录id号
self._n = 0 # 所有特征键值(x,y)的个数
self._C = 0 # 最大特征数
self._IDxy = {} # key为ID,value为对应的(x,y)
self._w = [] #存我们的w系数
self._EPS = EPS # 收敛条件
self._lastw = [] # 上一次w参数值
def loadData(self, dataset):
self._samples = deepcopy(dataset)
for items in self._samples:
y = items[0]
X = items[1:]
self._Y.add(y) # 集合中y若已存在则会自动忽略
for x in X:
if (x, y) in self._numXY:
self._numXY[(x, y)] += 1
else:
self._numXY[(x, y)] = 1
self._N = len(self._samples)
self._n = len(self._numXY)
self._C = max([len(sample) - 1 for sample in self._samples])
self._w = [0] * self._n # w参数初始化为n个0,其中n为所有特征值数
self._lastw = self._w[:]
self._Ep_ = [0] * self._n
# 计算特征函数fi关于经验分布的期望
# 其中i对应第几条
# xy对应(x, y)
for i, xy in enumerate(self._numXY):
self._Ep_[i] = self._numXY[xy] / self._N
self._xyID[xy] = i
self._IDxy[i] = xy
def _Zx(self, X): # 计算每个Z(x)值。其中Z(x)为规范化因子。
zx = 0
for y in self._Y:
ss = 0
for x in X:
if (x, y) in self._numXY:
ss += self._w[self._xyID[(x, y)]]
zx += math.exp(ss)
return zx
def _model_pyx(self, y, X): # 计算每个P(y|x)
zx = self._Zx(X)
ss = 0
for x in X:
if (x, y) in self._numXY:
ss += self._w[self._xyID[(x, y)]]
pyx = math.exp(ss) / zx
return pyx
def _model_ep(self, index): # 计算特征函数fi关于模型的期望
x, y = self._IDxy[index]
ep = 0
for sample in self._samples:
if x not in sample:
continue
pyx = self._model_pyx(y, sample)
ep += pyx / self._N
return ep
def _convergence(self): # 判断是否全部收敛
for last, now in zip(self._lastw, self._w):
if abs(last - now) >= self._EPS:
return False
return True
def predict(self, X): # 计算预测概率
Z = self._Zx(X)
result = {}
for y in self._Y:
ss = 0
for x in X:
if (x, y) in self._numXY:
ss += self._w[self._xyID[(x, y)]]
pyx = math.exp(ss) / Z
result[y] = pyx
return result
def train(self, maxiter=1000): # 训练数据
for loop in range(maxiter): # 最大训练次数
self._lastw = self._w[:]
for i in range(self._n):
ep = self._model_ep(i) # 计算第i个特征的模型期望
self._w[i] += math.log(self._Ep_[i] / ep) / self._C # 更新参数
if self._convergence(): # 判断是否收敛
break
dataset = [['no', 'sunny', 'hot', 'high', 'FALSE'],
['no', 'sunny', 'hot', 'high', 'TRUE'],
['yes', 'overcast', 'hot', 'high', 'FALSE'],
['yes', 'rainy', 'mild', 'high', 'FALSE'],
['yes', 'rainy', 'cool', 'normal', 'FALSE'],
['no', 'rainy', 'cool', 'normal', 'TRUE'],
['yes', 'overcast', 'cool', 'normal', 'TRUE'],
['no', 'sunny', 'mild', 'high', 'FALSE'],
['yes', 'sunny', 'cool', 'normal', 'FALSE'],
['yes', 'rainy', 'mild', 'normal', 'FALSE'],
['yes', 'sunny', 'mild', 'normal', 'TRUE'],
['yes', 'overcast', 'mild', 'high', 'TRUE'],
['yes', 'overcast', 'hot', 'normal', 'FALSE'],
['no', 'rainy', 'mild', 'high', 'TRUE']]
maxent = MaxEntropy()
x = ['overcast', 'mild', 'high', 'FALSE']
maxent.loadData(dataset)
maxent.train()
print('predict:', maxent.predict(x))结果:
predict: {'yes': 0.9999971802186581, 'no': 2.819781341881656e-06}到此,关于“python模拟逻辑斯蒂回归模型及最大熵模型举例分析”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





