[TOC]
txid:
namenode对每个操作事件(增删改操作)都给了一个唯一的id标识,称为txid,一般是从0开始自增,每多一个操作,txid就自增1。
fsimage:
是namenode在内存中的元数据在本地磁盘的一个镜像文件,但是通常情况fsimage并没有包含自新的操作事件,所以本质上和内存中元数据还是有差距的。这里记录的不是操作日志,其中包含HDFS文件系统的所有目录和文件idnode的序列化信息。一般命名方式是fsimage_txid 的形式,后面的txid表示该fsimage记录的最新的操作事件的txid。
edits:
是记录对namenode进行增删改操作的操作日志文件,如果有知道mysql的话,这和mysql 的二进制日志有点相似。
[root@bigdata121 tmp]# tree dfs/name
dfs/name
├── current
│ ├── edits_0000000000000000001-0000000000000000002
│ ├── edits_0000000000000000003-0000000000000000004
│ ├── edits_0000000000000000005-0000000000000000006
│ ├── edits_0000000000000000007-0000000000000000008
│ ├── edits_0000000000000000009-0000000000000000009
│ ├── edits_0000000000000000010-0000000000000000011
│ ├── edits_0000000000000000012-0000000000000000013
│ ├── edits_0000000000000000014-0000000000000000015
│ ├── edits_0000000000000000016-0000000000000000017
│ ├── edits_0000000000000000018-0000000000000000019
│ ├── edits_0000000000000000020-0000000000000000021
│ ├── edits_0000000000000000022-0000000000000000024
│ ├── edits_0000000000000000025-0000000000000000026
│ ├── edits_inprogress_0000000000000000027
│ ├── fsimage_0000000000000000024
│ ├── fsimage_0000000000000000024.md5
│ ├── fsimage_0000000000000000026
│ ├── fsimage_0000000000000000026.md5
│ ├── seen_txid
│ └── VERSION
└── in_use.lock总结来说,其实简化成以下结构:
dfs/name ├── current │ ├── edits_txid1-txid2 可能有多个,是已经滚动生成的旧的edits文件 │ ├── edits_inprogress_txid3 是目前正在使用的edits │ ├── fsimage_0000000000000000024 fsimage文件 │ ├── fsimage_0000000000000000024.md5 fsimage文件的md5校验值 │ ├── seen_txid 记录最新的txid │ └── VERSION 记录hdfs集群的一些简单信息 └── in_use.lock 锁文件,避免该目录用于启动多个namenode
(1)VERSION文件的内容
# 在hdfs中会有多个namenode,不同的namenode的namenodeID是不同的,分别管理一组blockpoolID
namespaceID=983105879
# 集群ID,全局唯一
clusterID=CID-c12b7022-0c51-49c5-942f-edc889d37fee
# 标记该namenode的存储目录创建的时间。对于刚刚创建的存储系统,这个属性为0.但在文件系统升级之后,该值会更新到新的时间戳
cTime=1558262787574
# 标记该存储目录是namenode还是datanode
storageType=NAME_NODE
# 一个block pool id标识一个block pool,并且是跨集群的全局唯一。当一个新的Namespace被创建的时候(format过程的一部分)会创建并持久化一个唯一ID。在创建过程构建全局唯一的BlockPoolID比人为的配置更可靠一些。NN将BlockPoolID持久化到磁盘中,在后续的启动过程中,会再次load并使用。
blockpoolID=BP-473222668-192.168.50.121-1558262787574
# 这个没什么用
layoutVersion=-63 (2)seen_txid
这个文件中记录了目前最新的一个txid
(3)SNN的目录结构和namenode是一样的,只是缺少了部分最新的edits文件。
我们可以看到上面fsimage和edits文件的文件名都跟着很长一串数字,那是什么呢,其实是txid,从两者命名方式上,我们可以看出一些规律来。
edits文件:
我们可以看到edits文件都是 edits_00000xxx-000000xxx的方式命名的,其实意思就是表示该edits文件中记录了txid操作事件的范围。而 edit_inprogess_00000xxx 则表示当前所记录到的最新的txid事件,以及该文件是目前正在使用的edits文件。
fsimage文件:
以fsimage_000000xxx 的方式命名,表示的是该fsimage 文件记录到的最新的txid事件,请注意,因为fsimage是有条件触发之后,edits文件才会合并到fsimage的,否则不会合并。所以一般情况下,edits文件后面的txid会比fsimage 大的。
//格式 : hdfs oiv -p 输出格式 -i 输入文件 -o 输出文件
[root@bigdata121 current]# hdfs oiv -p XML -i fsimage_0000000000000000037 -o /tmp/fsimage37.xml前面已经说到,fsimage记录的主要是元数据信息,它描述了hdfs 中存储的目录结构以及目录下的文件,还有对应的目录和文件的元信息。我们截取部分信息来看看:
<fsimage>
<version>
<layoutVersion>-63</layoutVersion>
<onDiskVersion>1</onDiskVersion>
<oivRevision>17e75c2a11685af3e043aa5e604dc831e5b14674</oivRevision>
</version>
<NameSection>
<namespaceId>983105879</namespaceId>
<genstampV1>1000</genstampV1>
<genstampV2>1014</genstampV2>
<genstampV1Limit>0</genstampV1Limit>
<lastAllocatedBlockId>1073741837</lastAllocatedBlockId>
<txid>334</txid>
</NameSection>
<INodeSection>
<lastInodeId>16407</lastInodeId>
<numInodes>16</numInodes>
这里开始是重点,记录的就是目录结构以及元信息
<inode>
<id>16386</id>
<type>DIRECTORY</type> 这个是目录,名字是test
<name>test</name>
<mtime>1558263065070</mtime> 修改时间
<permission>root:supergroup:0755</permission> 权限
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
<inode>
<id>16387</id> 这是个文件,名为edit_new.xml
<type>FILE</type>
<name>edit_new.xml</name>
<replication>2</replication>
<mtime>1558263065045</mtime>
<atime>1558269494520</atime>
<preferredBlockSize>134217728</preferredBlockSize>
<permission>root:supergroup:0644</permission> 权限
<blocks> 这里是block信息,包含了哪些block
<block>
<id>1073741825</id>
<genstamp>1001</genstamp>
<numBytes>580</numBytes>
</block>
</blocks>
<storagePolicyId>0</storagePolicyId>
</inode>
<INodeSection>
<fsimage>由以上这部分fsimage信息可知,它记录当前文件系统的目录结构以及对应的元信息。和edits的差别是,edits记录的是对该文件系统的操作。
//格式:hdfs oev -p 输出格式(默认XML) -i 输入文件 -o 输出文件
[root@bigdata121 current]# hdfs oev -i edits_inprogress_0000000000000000038 -o /tmp/edits_inprogess.xml同样截取部分信息查看:
<?xml version="1.0" encoding="UTF-8"?>
<EDITS>
<EDITS_VERSION>-63</EDITS_VERSION>
<RECORD>
<OPCODE>OP_START_LOG_SEGMENT</OPCODE> 表示操作的类别,这里是表示日志开始记录
<DATA>
<TXID>38</TXID> 类似于操的ID,是唯一的
</DATA>
</RECORD>
</EDITS>
每个RECORD记录的就是一次操作
<RECORD>
<OPCODE>OP_ADD_BLOCK</OPCODE> //像这个就表示上传文件的操作
<DATA>
<TXID>34</TXID>
<PATH>/jdk-8u144-linux-x64.tar.gz._COPYING_</PATH>
<BLOCK>
<BLOCK_ID>1073741825</BLOCK_ID>
<NUM_BYTES>134217728</NUM_BYTES>
<GENSTAMP>1001</GENSTAMP>
</BLOCK>
<BLOCK>
<BLOCK_ID>1073741826</BLOCK_ID>
<NUM_BYTES>0</NUM_BYTES>
<GENSTAMP>1002</GENSTAMP>
</BLOCK>
<RPC_CLIENTID></RPC_CLIENTID>
<RPC_CALLID>-2</RPC_CALLID>
</DATA>
</RECORD>每个RECORD记录了一次操作,比如图中的
OP_ADD代表添加文件操作。一般来说里面还记录了
文件路径(PATH)
修改时间(MTIME)
添加时间(ATIME)
客户端名称(CLIENT_NAME)
客户端地址(CLIENT_MACHINE)
权限(PERMISSION_STATUS)等非常有用的信息
格式:hdfs dfsadmin -rollEdits
在core-site.xml中配置了hadoop.tmp.dir的话,各自的数据目录如下:
NN:{hadoop.tmp.dir}/dfs/name fsimage和edits文件都会存储在这一个目录下
SNN:${hadoop.tmp.dir}/dfs/namesecondary SNN的数据目录
DN:${hadoop.tmp.dir}/dfs/data datanode的数据目录如果不设置hadoop.tmp.dir 这个值,那么NN,SNN,DN都需要手动设置各自的数据目录,否则数据文件都会生成到 /tmp/hadoop-root/dfs/ 下,各自的设置参数如下:
/*都在hdfs-site.xml中设置*/
//如果这两个只设置了其中一个,那么fsimage和edits文件都会存储到指定的一个目录下
NN:dfs.namenode.name.dir 设置fsimage存储的路径
dfs.namenode.edits.dir 设置edits存储路径
DN: dfs.datanode.data.dir 这是datanode存储目录
SNN:dfs.namenode.checkpoint.dir 这是SNN存储目录在单独设置namenode的工作目录时,我们可以给dfs.namenode.name.dir 设置多个值,以逗号分隔开,那么hdfs namenode -format格式化的时候,也会格式化出两个namenode目录,并且两个目录在运行过程中内容也保持一致,可以使用这种方式作为给namenode备份数据的补充。如:
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2</value>
</property>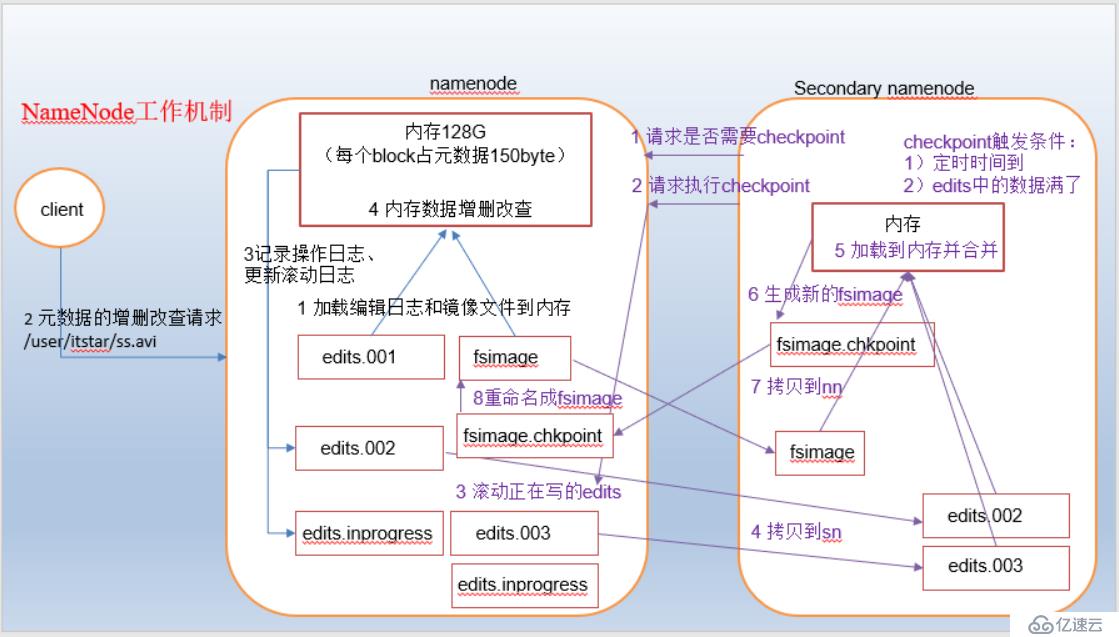
(1)第一次启动namenode时(即第一次格式化namenode之后),会自动创建fsimage和edits文件。如果不是第一次启动,则namenode会加载最新的fsimage以及从fsimage开始到最新的操作事件(以seen_txid文件记录的txid为准)的所包含的edits文件到内存中,最终在内存中存储的是最新的元信息。并创建一个新的edits文件,用于记录的操作,名字是 edit_inprogress_xxxx。
(2)client 对namenode发起增删改请求
(3)namenode响应请求
(4)namenode记录增删改操作时,会先将操作写入到edits文件中,当成功写入之后,才会修改内存中存储的元数据。这种方式是为了保证最新的操作一定持续化存储在磁盘这种永久性存储中,避免意外导致操作记录丢失。
(1)SNN根据设置的检查checkpoint的时间间隔,询问namenode是否需要执行checkpoint。namenode响应SNN结果。
(2)如果结果为是,则SNN请求namenode执行checkpoint操作
(3)namenode开始执行checkpoint操作,首先滚动目前正使用的edits文件,将滚动后的edits文件命名为 edits_txid1-txid2的形式,并创建新的edits文件,名字为 edits_inprogess_txid2+1。滚动edits目的主要是为了防止合并操作影响namenode对外提供服务,滚动之后,操作记录可以正常写入到新的edits文件中。
(4)将最新的fsimage(看文件后面的txid,最大的就是最新的),以及由此到最新的txid的edits文件拷贝到SNN。注意看fsimage文件名的txid以及edits文件名后面的txid,小于fsimage后面的txid的edits文件不需要拷贝。
(5)SNN读取拷贝过来的fsiamge和edits文件到内存中进行合并
(6)合并后生成新的fsimage文件,名字为 fsimage.chkpoint
(7)拷贝fsimage.chkpoint到namenode
(8)namenode收到fsimage.chkpoint之后,重名为 fsimage_txid 的形式,后面txid表示此fsimage文件记录的最新的操作的txid。
hdfs-default.xml
---------------checkpoint实际间隔------------------------
<!--checkpoint的时间间隔,默认一小时,单位是秒-->
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
---------------操作次数------------------------
<!--触发checkpoint操作条件之一,edits记录的操作次数,达到这里指定的次数就会触发checkpoint-->
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
<!--检查操作次数的实际间隔,默认60秒-->
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
</property>(1)edis文件的大小超过64M
(2)当前edits文件存在时间超过一定时间,默认3600秒
(3)edit文件中记录的操作次数达到指定的次数,默认1000000次。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



