жң¬зҜҮж–Үз« з»ҷеӨ§е®¶еҲҶдә«зҡ„жҳҜжңүе…іжҖҺд№ҲдҪҝз”ЁCatBoostиҝӣиЎҢеҝ«йҖҹжўҜеәҰжҸҗеҚҮпјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еӯҰд№ пјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·пјҢиҜқдёҚеӨҡиҜҙпјҢи·ҹзқҖе°Ҹзј–дёҖиө·жқҘзңӢзңӢеҗ§гҖӮ
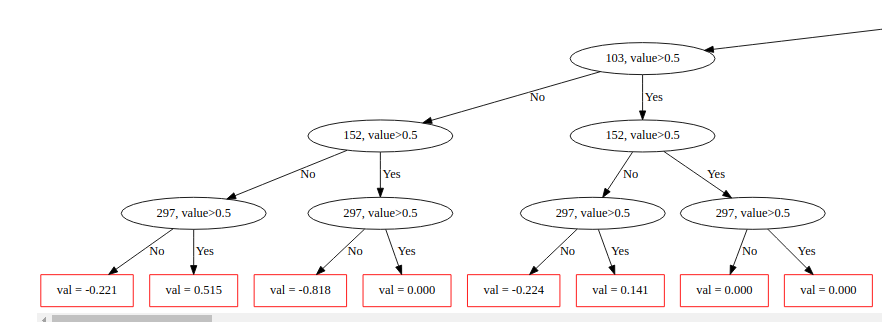
еңЁжўҜеәҰжҸҗеҚҮдёӯпјҢйў„жөӢжҳҜз”ұдёҖзҫӨејұеӯҰд№ иҖ…еҒҡеҮәзҡ„гҖӮдёҺдёәжҜҸдёӘж ·жң¬еҲӣе»әеҶізӯ–ж ‘зҡ„йҡҸжңәжЈ®жһ—дёҚеҗҢпјҢеңЁжўҜеәҰеўһејәдёӯпјҢж ‘жҳҜдёҖдёӘжҺҘдёҖдёӘең°еҲӣе»әзҡ„гҖӮжЁЎеһӢдёӯзҡ„е…ҲеүҚж ‘дёҚдјҡжӣҙж”№гҖӮеүҚдёҖжЈөж ‘зҡ„з»“жһңз”ЁдәҺж”№иҝӣдёӢдёҖжЈөж ‘гҖӮеңЁжң¬ж–ҮдёӯпјҢжҲ‘们е°Ҷд»”з»Ҷз ”з©¶дёҖдёӘеҗҚдёәCatBoostзҡ„жўҜеәҰеўһејәеә“гҖӮ
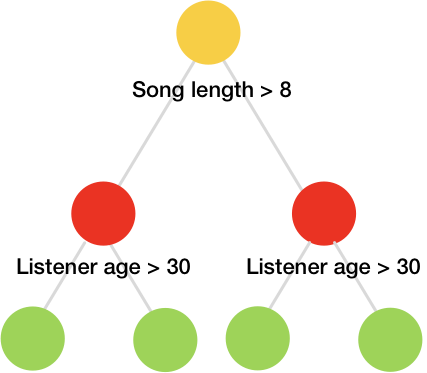
CatBoost жҳҜYandexејҖеҸ‘зҡ„ж·ұеәҰж–№еҗ‘жўҜеәҰеўһејәеә“ гҖӮе®ғдҪҝз”ЁйҒ—еҝҳзҡ„еҶізӯ–ж ‘жқҘз”ҹжҲҗе№іиЎЎж ‘гҖӮзӣёеҗҢзҡ„еҠҹиғҪз”ЁдәҺеҜ№ж ‘зҡ„жҜҸдёӘзә§еҲ«иҝӣиЎҢе·ҰеҸіжӢҶеҲҶгҖӮ
дёҺз»Ҹе…ёж ‘зӣёжҜ”пјҢйҒ—еҝҳж ‘еңЁCPUдёҠе®һзҺ°ж•ҲзҺҮжӣҙй«ҳпјҢ并且жҳ“дәҺе®үиЈ…гҖӮ
еңЁжңәеҷЁеӯҰд№ дёӯеӨ„зҗҶеҲҶзұ»зҡ„еёёи§Ғж–№жі•жҳҜеҚ•зғӯзј–з Ғе’Ңж Үзӯҫзј–з ҒгҖӮCatBoostе…Ғи®ёжӮЁдҪҝз”ЁеҲҶзұ»еҠҹиғҪпјҢиҖҢж— йңҖеҜ№е…¶иҝӣиЎҢйў„еӨ„зҗҶгҖӮ
дҪҝз”ЁCatBoostж—¶пјҢжҲ‘们дёҚеә”иҜҘдҪҝз”ЁдёҖй”®зј–з ҒпјҢеӣ дёәиҝҷдјҡеҪұе“Қи®ӯз»ғйҖҹеәҰд»ҘеҸҠйў„жөӢиҙЁйҮҸгҖӮзӣёеҸҚпјҢжҲ‘们еҸӘйңҖиҰҒдҪҝз”Ёcat_features еҸӮж•°жҢҮе®ҡеҲҶзұ»зү№еҫҒеҚіеҸҜ гҖӮ
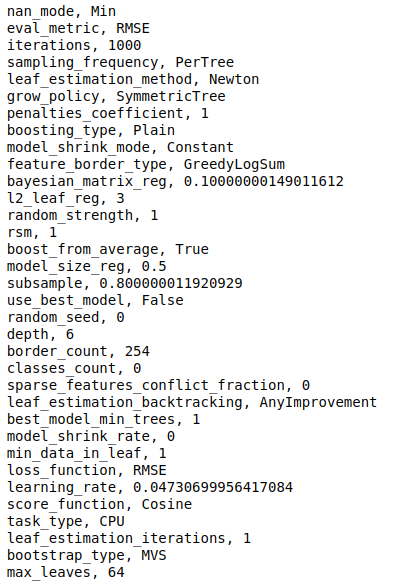
loss_function еҲ«еҗҚдёә objective -з”ЁдәҺи®ӯз»ғзҡ„жҢҮж ҮгҖӮиҝҷдәӣжҳҜеӣһеҪ’жҢҮж ҮпјҢдҫӢеҰӮз”ЁдәҺеӣһеҪ’зҡ„еқҮж–№ж №иҜҜе·®е’Ңз”ЁдәҺеҲҶзұ»зҡ„еҜ№ж•°жҚҹеӨұгҖӮ
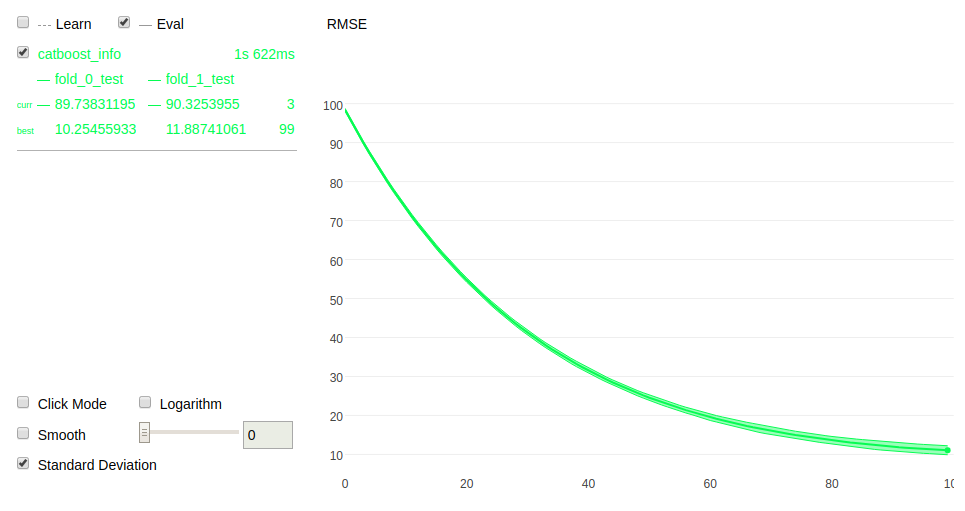
eval_metric вҖ”з”ЁдәҺжЈҖжөӢиҝҮеәҰжӢҹеҗҲзҡ„еәҰйҮҸгҖӮ
iterations -еҫ…е»әзҡ„ж ‘зҡ„жңҖеӨ§ж•°йҮҸпјҢй»ҳи®Өдёә1000гҖӮеҲ«еҗҚжҳҜ num_boost_roundпјҢ n_estimatorsе’Ң num_treesгҖӮ
learning_rate еҲ«еҗҚ eta -еӯҰд№ йҖҹзҺҮпјҢзЎ®е®ҡжЁЎеһӢе°ҶеӯҰд№ еӨҡеҝ«жҲ–еӨҡж…ўгҖӮй»ҳи®ӨеҖјйҖҡеёёдёә0.03гҖӮ
random_seed еҲ«еҗҚ random_state вҖ”з”ЁдәҺи®ӯз»ғзҡ„йҡҸжңәз§ҚеӯҗгҖӮ
l2_leaf_reg еҲ«еҗҚ reg_lambda вҖ”жҲҗжң¬еҮҪж•°зҡ„L2жӯЈеҲҷеҢ–йЎ№зҡ„зі»ж•°гҖӮй»ҳи®ӨеҖјдёә3.0гҖӮ
bootstrap_type вҖ”зЎ®е®ҡеҜ№иұЎжқғйҮҚзҡ„йҮҮж ·ж–№жі•пјҢдҫӢеҰӮиҙқеҸ¶ж–ҜпјҢиҙқеҠӘеҲ©пјҢMVSе’ҢжіҠжқҫгҖӮ
depth вҖ”ж ‘зҡ„ж·ұеәҰгҖӮ
grow_policy вҖ”зЎ®е®ҡеҰӮдҪ•еә”з”ЁиҙӘе©Әжҗңзҙўз®—жі•гҖӮе®ғеҸҜд»ҘжҳҜ SymmetricTreeпјҢ DepthwiseжҲ– LossguideгҖӮ SymmetricTree жҳҜй»ҳи®ӨеҖјгҖӮеңЁдёӯ SymmetricTreeпјҢйҖҗзә§жһ„е»әж ‘пјҢзӣҙеҲ°иҫҫеҲ°ж·ұеәҰдёәжӯўгҖӮеңЁжҜҸдёӘжӯҘйӘӨдёӯпјҢд»ҘзӣёеҗҢжқЎд»¶еҲҶеүІеүҚдёҖжЈөж ‘зҡ„еҸ¶еӯҗгҖӮеҪ“ Depthwise иў«йҖүжӢ©пјҢдёҖжЈөж ‘жҳҜеҶ…зҪ®дёҖжӯҘжӯҘйӘӨпјҢзӣҙеҲ°жҢҮе®ҡзҡ„ж·ұеәҰе®һзҺ°гҖӮеңЁжҜҸдёӘжӯҘйӘӨдёӯпјҢе°ҶжңҖеҗҺдёҖжЈөж ‘зә§еҲ«зҡ„жүҖжңүйқһз»Ҳз«ҜеҸ¶еӯҗеҲҶејҖгҖӮдҪҝз”ЁеҜјиҮҙжңҖдҪіжҚҹеӨұж”№е–„зҡ„жқЎд»¶жқҘеҲҶиЈӮеҸ¶еӯҗгҖӮеңЁдёӯ LossguideпјҢйҖҗеҸ¶жһ„е»әж ‘пјҢзӣҙеҲ°иҫҫеҲ°жҢҮе®ҡзҡ„еҸ¶ж•°гҖӮеңЁжҜҸдёӘжӯҘйӘӨдёӯпјҢе°ҶжҚҹиҖ—ж”№е–„жңҖдҪізҡ„йқһз»Ҳз«ҜеҸ¶еӯҗиҝӣиЎҢжӢҶеҲҶ
min_data_in_leaf еҲ«еҗҚ min_child_samples вҖ”иҝҷжҳҜдёҖзүҮеҸ¶еӯҗдёӯи®ӯз»ғж ·жң¬зҡ„жңҖе°Ҹж•°йҮҸгҖӮжӯӨеҸӮж•°д»…дёҺ Lossguide е’Ң Depthwise еўһй•ҝзӯ–з•ҘдёҖиө·дҪҝз”ЁгҖӮ
max_leaves alias num_leaves вҖ”жӯӨеҸӮж•°д»…дёҺLossguide зӯ–з•ҘдёҖиө·дҪҝз”ЁпјҢ 并确е®ҡж ‘дёӯзҡ„еҸ¶еӯҗж•°гҖӮ
ignored_features вҖ”иЎЁзӨәеңЁеҹ№и®ӯиҝҮзЁӢдёӯеә”еҝҪз•Ҙзҡ„еҠҹиғҪгҖӮ
nan_mode вҖ”еӨ„зҗҶзјәеӨұеҖјзҡ„ж–№жі•гҖӮйҖүйЎ№еҢ…жӢ¬ ForbiddenпјҢ MinпјҢе’Ң MaxгҖӮй»ҳи®ӨеҖјдёә MinгҖӮеҪ“ Forbidden дҪҝз”Ёж—¶пјҢзјәеӨұеҖјеҜјиҮҙй”ҷиҜҜзҡ„еӯҳеңЁгҖӮдҪҝз”Ё MinпјҢзјәе°‘зҡ„еҖје°ҶдҪңдёәиҜҘеҠҹиғҪзҡ„жңҖе°ҸеҖјгҖӮеңЁдёӯ MaxпјҢзјәеӨұеҖјиў«и§Ҷдёәзү№еҫҒзҡ„жңҖеӨ§еҖјгҖӮ
leaf_estimation_method вҖ”з”ЁдәҺи®Ўз®—еҸ¶еӯҗдёӯеҖјзҡ„ж–№жі•гҖӮеңЁеҲҶзұ»дёӯпјҢдҪҝз”Ё10 Newton ж¬Ўиҝӯд»ЈгҖӮдҪҝз”ЁеҲҶдҪҚж•°жҲ–MAEжҚҹеӨұзҡ„еӣһеҪ’й—®йўҳдҪҝз”ЁдёҖж¬Ў Exact иҝӯд»ЈгҖӮеӨҡеҲҶзұ»дҪҝз”ЁдёҖж¬Ў Netwon иҝӯд»ЈгҖӮ
leaf_estimation_backtracking вҖ”еңЁжўҜеәҰдёӢйҷҚиҝҮзЁӢдёӯдҪҝз”Ёзҡ„еӣһжәҜзұ»еһӢгҖӮй»ҳи®ӨеҖјдёә AnyImprovementгҖӮ AnyImprovement еҮҸе°ҸдёӢйҷҚжӯҘй•ҝпјҢзӣҙиҮіжҚҹеӨұеҮҪж•°еҖје°ҸдәҺдёҠж¬Ўиҝӯд»Јзҡ„еҖјгҖӮ Armijo еҮҸе°ҸдёӢйҷҚжӯҘй•ҝпјҢзӣҙеҲ°ж»Ўи¶і ArmijoжқЎд»¶ гҖӮ
boosting_type вҖ”еҠ ејәи®ЎеҲ’гҖӮе®ғеҸҜд»Ҙplain з”ЁдәҺз»Ҹе…ёзҡ„жўҜеәҰеўһејәж–№жЎҲпјҢд№ҹеҸҜд»Ҙ з”ЁдәҺжҲ– orderedпјҢе®ғеңЁиҫғе°Ҹзҡ„ж•°жҚ®йӣҶдёҠеҸҜд»ҘжҸҗдҫӣжӣҙеҘҪзҡ„иҙЁйҮҸгҖӮ
score_function вҖ” еҲҶж•°зұ»еһӢпјҢ з”ЁдәҺеңЁж ‘жһ„е»әиҝҮзЁӢдёӯйҖүжӢ©дёӢдёҖдёӘжӢҶеҲҶгҖӮ Cosine жҳҜй»ҳи®ӨйҖүйЎ№гҖӮе…¶д»–еҸҜз”Ёзҡ„йҖүйЎ№жҳҜ L2пјҢ NewtonL2е’Ң NewtonCosineгҖӮ
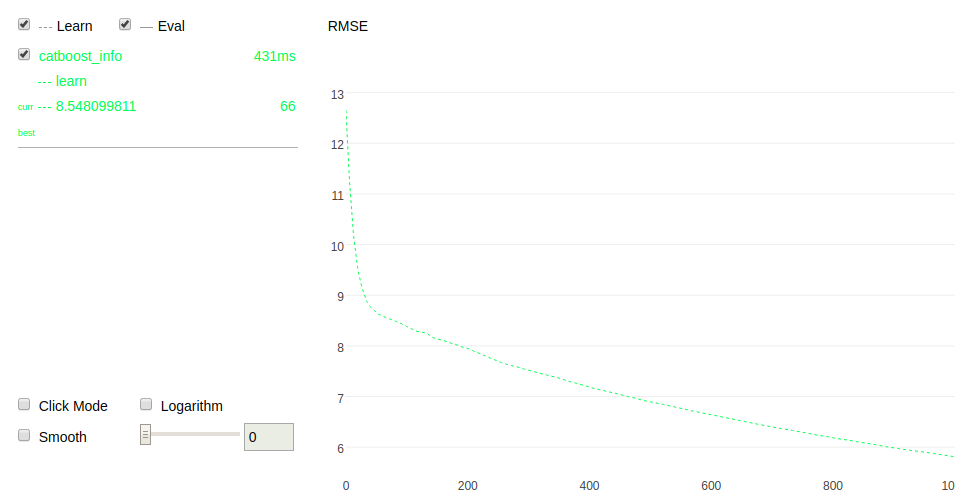
early_stopping_rounds вҖ”еҪ“ж—¶ TrueпјҢе°ҶиҝҮжӢҹеҗҲжЈҖжөӢеҷЁзұ»еһӢи®ҫзҪ®дёәпјҢ Iter 并еңЁиҫҫеҲ°жңҖдҪіеәҰйҮҸж—¶еҒңжӯўи®ӯз»ғгҖӮ
classes_count вҖ”еӨҡйҮҚеҲҶзұ»й—®йўҳзҡ„зұ»еҲ«ж•°гҖӮ
task_type вҖ”дҪҝз”Ёзҡ„жҳҜCPUиҝҳжҳҜGPUгҖӮCPUжҳҜй»ҳи®Өи®ҫзҪ®гҖӮ
devices вҖ”з”ЁдәҺи®ӯз»ғзҡ„GPUи®ҫеӨҮзҡ„IDгҖӮ
cat_features вҖ”е…·жңүеҲҶзұ»еҲ—зҡ„ж•°з»„гҖӮ
text_features -з”ЁдәҺеңЁеҲҶзұ»й—®йўҳдёӯеЈ°жҳҺж–Үжң¬еҲ—гҖӮ
CatBoostеңЁе…¶е®һж–ҪдёӯдҪҝз”Ёscikit-learnж ҮеҮҶгҖӮи®©жҲ‘们зңӢзңӢеҰӮдҪ•е°Ҷе…¶з”ЁдәҺеӣһеҪ’гҖӮ
д»ҘдёҠе°ұжҳҜжҖҺд№ҲдҪҝз”ЁCatBoostиҝӣиЎҢеҝ«йҖҹжўҜеәҰжҸҗеҚҮпјҢе°Ҹзј–зӣёдҝЎжңүйғЁеҲҶзҹҘиҜҶзӮ№еҸҜиғҪжҳҜжҲ‘们ж—Ҙеёёе·ҘдҪңдјҡи§ҒеҲ°жҲ–з”ЁеҲ°зҡ„гҖӮеёҢжңӣдҪ иғҪйҖҡиҝҮиҝҷзҜҮж–Үз« еӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮжӣҙеӨҡиҜҰжғ…敬иҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ