

vi hadoop-env.sh:
export= JAVA_HOME=/opt/inst/jdk181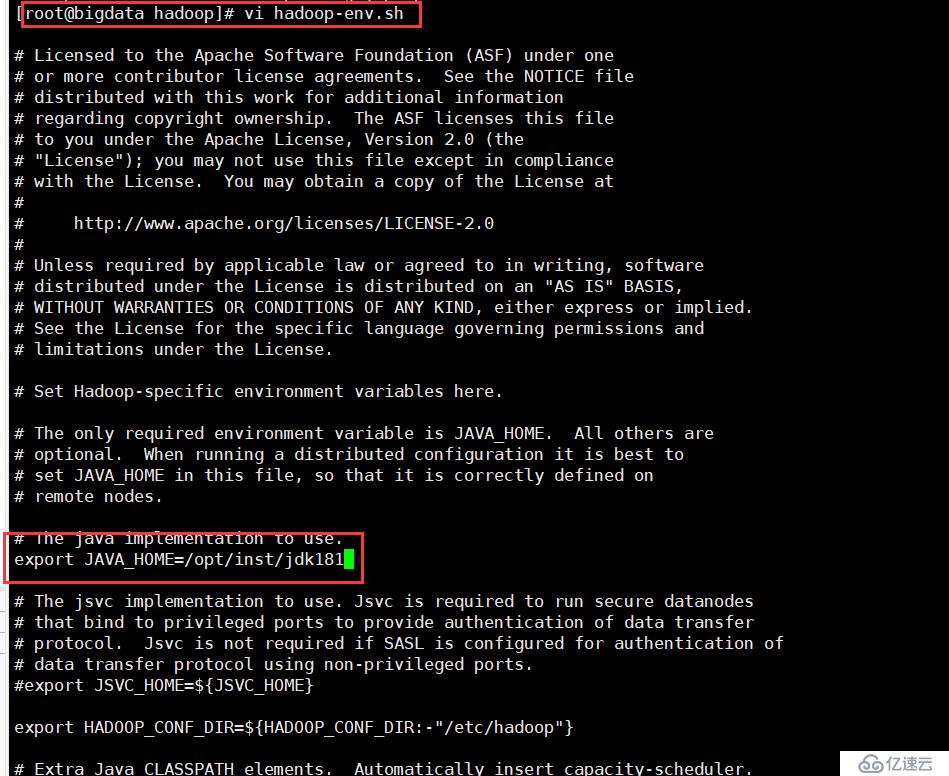
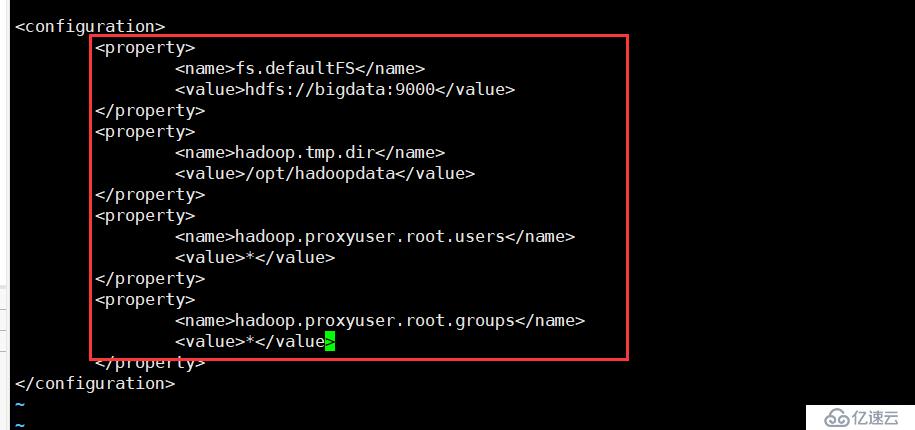
vi core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoopdata</value>
</property>
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
vi hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>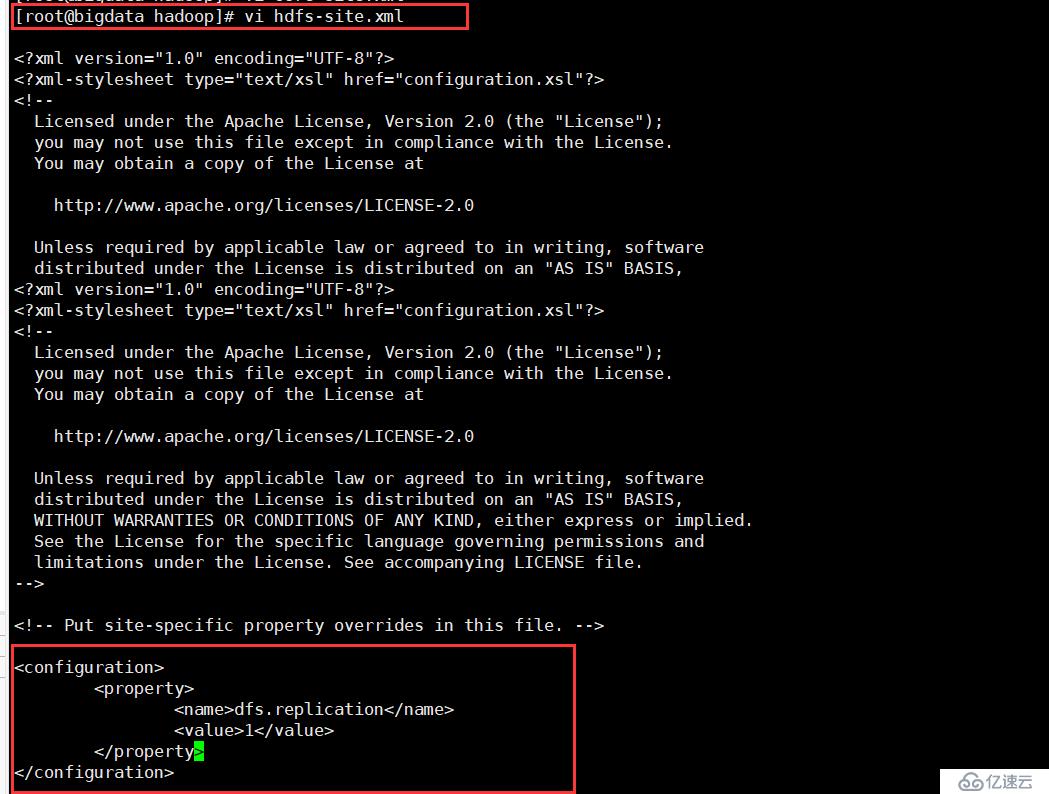
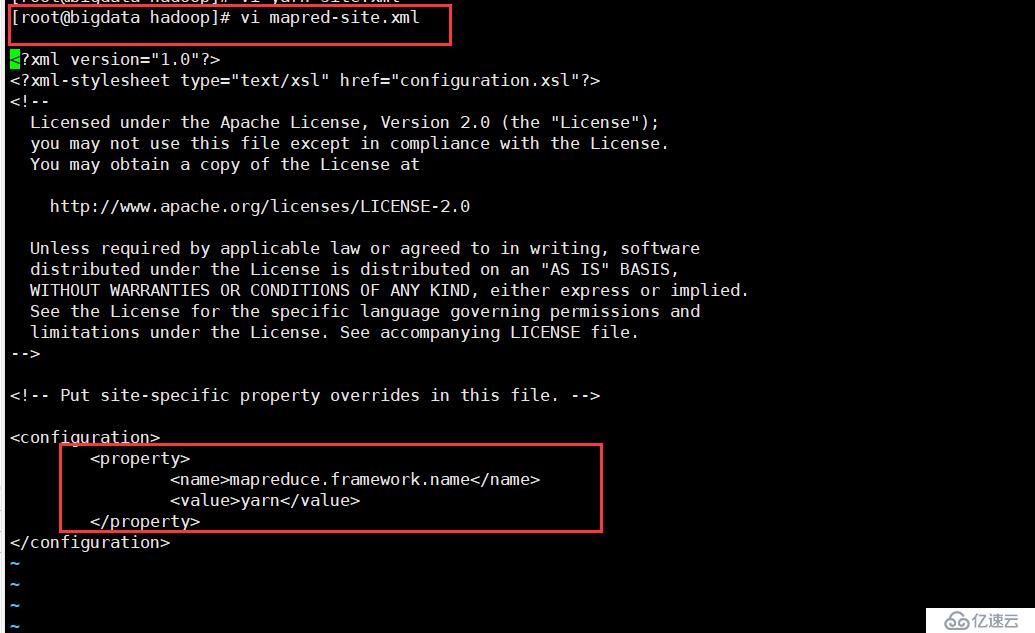
cp mapred-site.xml.template mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
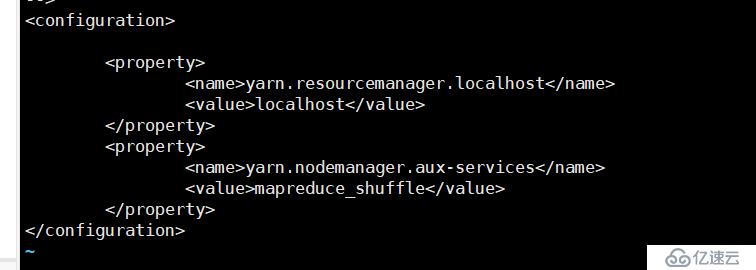
vi
export HADOOP_HOME=/opt/bigdata/hadoop260
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME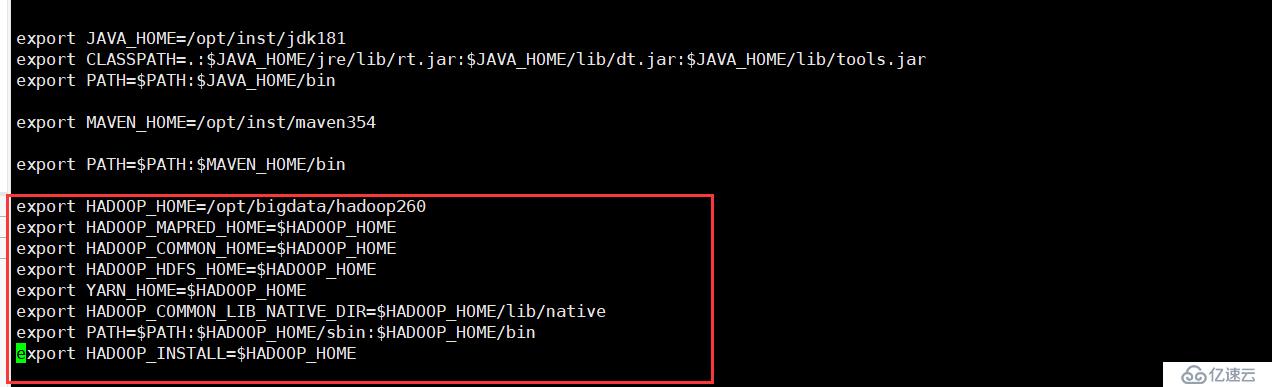
source /etc/profile
hdfs namenode -format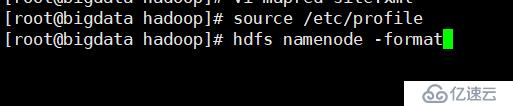
start-all.sh
jps
#查看进程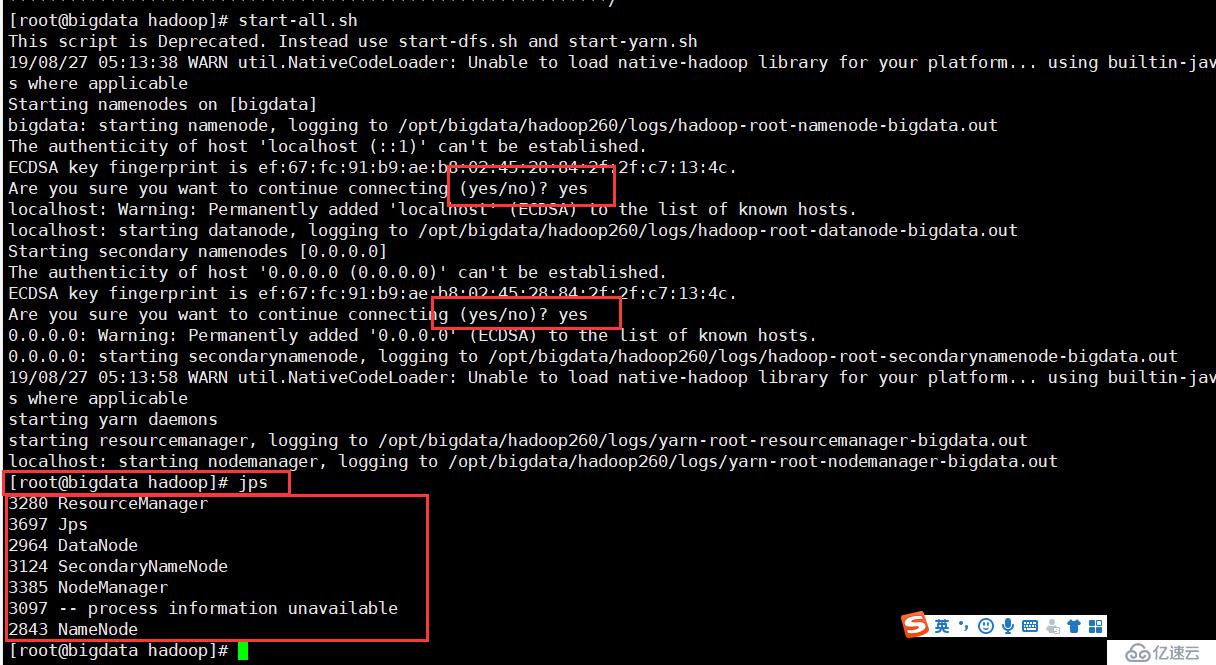
hdfs dfs -put /opt/a.txt /cm/
hdfs dfs -ls /cm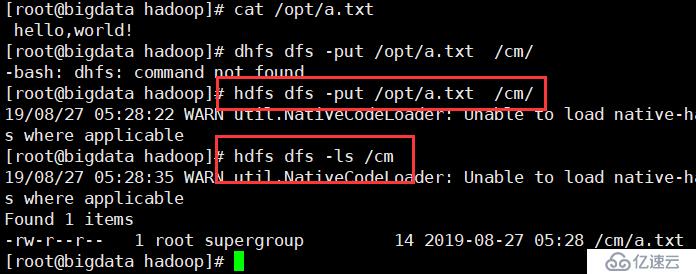
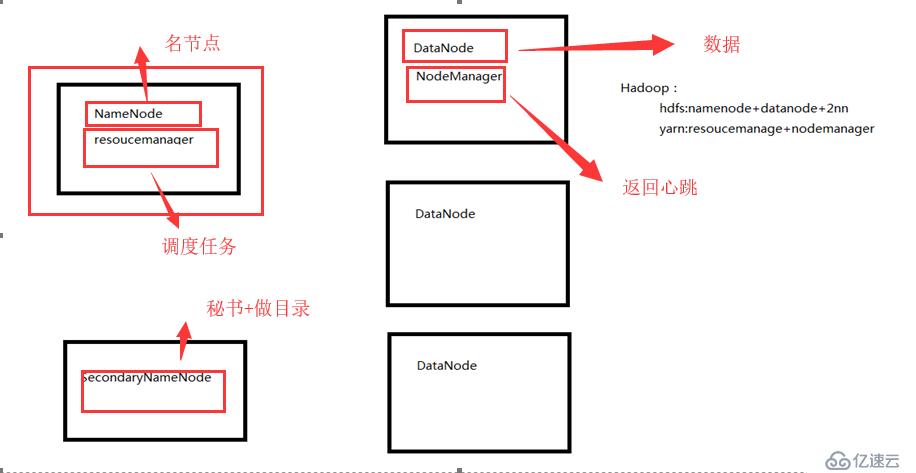
NameNode:主节点,目录
DataNode:从节点,数据
SecondaryNameNode:主节点的备份
调度的是内存的资源和CPU的算力
通过ResourceManager(只有一个) 来调度
ResourceManager主要作用:
1.处理客户端请求
2.监控NodeManager
3.启动或监控ApplicationMaster()
4.资源的分配或调度
NodeManager(多个)
NodeManager主要作用:
1.管理单个节点上的资源
2.处理来自ResourceManager的命令
3.处理来自ApplicationMaster的命令
运算的

亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



