本篇内容介绍了“性能超高的API网关之怎么使用Fizz Gateway”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
中间层在Web网站上的部署偏前,一般部署于防火墙及Nginx之后,更多面向C端用户服务,所以在性能并发量上有较高的要求,大部分团队在选型上会选择异步框架。正因为其直接面向C端,变化较多,大部分需要经常性地变更或者配置的代码都会安排在这一层次,发布非常频繁。此外,很多团队使用编译型语言进行编码,而非解释型语言。这三个因素组合在一起,使得开发者调试与开发非常痛苦。比如,我们曾经选择Play2框架,这是一个异步Java框架,需要开发者能够流畅地编写异步,但是熟悉调试技巧的同事也不多。在代码里面配置了各种请求参数,以及结果处理,看似非常简单,但是联调、单元测试、或者配置文件修改之后等待Java编译花费的时间和精力是巨大的。如果异步编码规范也有问题,这对开发者来说无疑是一种折磨。
public F.Promise<BaseDto<List<Good>>> getGoodsByCondi(final StringBuilder searchParams, final GoodsQueryParam param) {
final Map<String, String> params = new TreeMap<String, String>();
final OutboundApiKey apiKey = OutboundApiKeyUtils.getApiKey("search.api");
params.put("apiKey", apiKey.getApiKey());
params.put("service", "Search.getMerchandiseBy");
if(StringUtils.isNotBlank(param.getSizeName())){
try {
searchParams.append("sizes:" + URLEncoder.encode(param.getSizeName(), "utf-8") + ";");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
if (param.getStock() != null) {
searchParams.append("hasStock:" + param.getStock() + ";");
}
if (param.getSort() != null && !param.getSort().isEmpty()) {
searchParams.append("orderBy:" + param.getSort() + ";");
}
searchParams.append("limit:" + param.getLimit() + ";page:" + param.getStart());
params.put("traceId", "open.api.vip.com");
ApiKeySignUtil.getApiSignMap(params,apiKey.getApiSecret(),"apiSign");
String url = RemoteServiceUrl.SEARCH_API_URL;
Promise<HttpResponse> promise = HttpInvoker.get(url, params);
final GoodListBaseDto retVal = new GoodListBaseDto();
Promise<BaseDto<List<Good>>> goodListPromise = promise.map(new Function<HttpResponse, BaseDto<List<Good>>>() {
@Override
public BaseDto<List<Good>> apply(HttpResponse httpResponse)throws Throwable {
JsonNode json = JsonUtil.toJsonNode(httpResponse.getBody());
if (json.get("code").asInt() != 200) {
Logger.error("Error :" + httpResponse.getBody());
return new BaseDto<List<Good>>(CommonError.SYS_ERROR);
}
JsonNode result = json.get("items");
Iterator<JsonNode> iterator = result.elements();
final List<Good> goods = new ArrayList<Good>();
while (iterator.hasNext()) {
final Good good = new Good();
JsonNode goodJson = iterator.next();
good.setGid(goodJson.get("id").asText());
good.setDiscount(String.format("%.2f", goodJson.get("discount").asDouble()));
good.setAgio(goodJson.get("setAgio").asText());
if (goodJson.get("brandStoreSn") != null) {
good.setBrandStoreSn(goodJson.get("brandStoreSn").asText());
}
Iterator<JsonNode> whIter = goodJson.get("warehouses").elements();
while (whIter.hasNext()) {
good.getWarehouses().add(whIter.next().asText());
}
if (goodJson.get("saleOut").asInt() == 1) {
good.setSaleOut(true);
} good.setVipPrice(goodJson.get("vipPrice").asText());
goods.add(good);
}
retVal.setData(goods);
return retVal;
}
});
if(param.getBrandId() != null && !param.getBrandId().isEmpty()))){
final Promise<List<ActiveTip>> pmsPromise = service.getActiveTipsByBrand(param.getBrandId());
return goodListPromise.flatMap(new Function<BaseDto<List<Good>>, Promise<BaseDto<List<Good>>>>() {
@Override
public Promise<BaseDto<List<Good>>> apply(BaseDto<List<Good>> listBaseDto) throws Throwable {
return pmsPromise.flatMap(new Function<List<ActiveTip>, Promise<BaseDto<List<Good>>>>() {
@Override
public Promise<BaseDto<List<Good>>> apply(List<ActiveTip> activeTips) throws Throwable {
retVal.setPmsList(activeTips);
BaseDto<List<Good>> baseDto = (BaseDto<List<Good>>)retVal;
return Promise.pure(baseDto);
}
});
}
});
}
return goodListPromise;
}上述代码只是摘抄了其中一个过程函数。如果我们将中间层的场景设置得更为复杂一些,我们要解决的就不仅仅是编码性能、编码质量、编码时间的问题。
## “复杂”场景问题
微服务颗粒度较细,为了实现简洁的前端逻辑以及较少的服务调用次数,我们针对C端的大部分输出是聚合的结果。比如,我们一个搜索的中间层逻辑,其服务是这样一个过程:
获取会员信息、会员卡列表、会员积分余额,因为不同级别的会员会有不同价格;
获取用户的优惠券信息,这部分会对计算出来的价格产生影响;
获取搜索的结果信息,结果来自三部分,商旅商品的库存价格,猜你喜欢的库存价格,推荐位的库存价格,海外商品的库存价格。
这其中涉及到的服务有:中间层服务(聚合服务)、会员服务、优惠券服务、推荐服务、企业服务、海外搜索服务、搜索服务。此外,还有各种类型的缓存设施以及数据库的配置服务。
public List<ExtenalProduct> searchProduct(String traceId, ExtenalProductQueryParam param, MemberAssetVO memberAssetVO, ProductInfoResultVO resultVO,boolean needAddPrice) {
// 用户可用优惠券的configId
String configIds = memberAssetVO == null ? null : memberAssetVO.getConfigIds();
// 特殊项目,限制不能使用优惠券功能
if(customProperties.getIgnoreChannel().contains(param.getChannelCode())) {
configIds = null;
}
final String configIdConstant = configIds;
// 主搜索列表信息
Mono<List<ExtenalProduct>> innInfos = this.search(traceId, param, configIds, resultVO);
return innInfos.flatMap(inns -> {
// 商旅产品推荐
Mono<ExtenalProduct> busiProduct = this.recommendProductService.getBusiProduct(traceId, param, configIdConstant);
// 会员产品推荐(猜您喜欢)
Mono<ExtenalProduct> guessPref = this.recommendProductService.getGuessPref(traceId, param, configIdConstant);
// 业务相关查询
String registChainId = memberAssetVO == null || memberAssetVO.getMember() == null ? null : memberAssetVO.getMember().getRegistChainId();
Mono<ExtenalProduct> registChain = this.recommendProductService.registChain(traceId, param, configIdConstant, registChainId);
// 店长热推产品
Mono<ExtenalProduct> advert = this.recommendProductService.advert(traceId, param, configIdConstant);
return Mono.zip(busiProduct, guessPref, registChain, advert).flatMap(product -> {
// 推荐位(广告位)包装
List<ExtenalProduct> products = recommendProductService.setRecommend(inns, product.getT1(), product.getT2(), product.getT3(), product.getT4(), param);
// 设置其他参数
return this.setOtherParam(traceId, param, products, memberAssetVO);
});
}).block();
}这个服务的Service层会经常性地根据产品需求和底层微服务接口的变更做出调整改变,而研发的接口调用时序图却因为团队的这些更改对应不上代码。
除了上述问题外,该服务中的多个微服务异步调用聚合的编码问题也未能被妥善处理,因为其使用的Spring-MVC框架编码风格是同步的,而Service层却使用了异步的Mono,只能不合时宜地用block。这些代码更改、文档缺失、编码质量共同组成了中间层的代码管理问题。
## 野蛮发展问题
我参与过一个初创技术团队建设。最开始,因为快速开发的需要,我们倾向于做一个胖服务,但当团队规模开始扩大时,我们却需要逐步地将胖服务分拆为微服务,开始产生中间层团队,他们的主要目的是应用于底层服务的聚合。
但是,有一段时间,我们的招聘速度并不能完全赶上服务数量的增长速度,于是写底层的同事就需要不断地切换编码思路。因为除了要编写分拆之后的底层微服务,还要编写聚合的中间层服务。
当我停掉某一些项目时,开始整顿人手,我又发现一个残酷事实:每个人手上都有数十个中间层服务,因此无法换掉任何一个人。因为经过多次地换手,同事们已经搞不清中间服务的联系。
另外,还有各种授权方式,因为团队一直以来的野蛮成长,各种授权方式都混在一起,既有简单的,又有复杂的,既有合理的,还有不合理的。总之,团队没有人能搞清楚。
经过一段时间的发展后,通过整理线上服务,我们发现很多资源浪费,比如有时候,仅仅一个接口就使用了一个微服务。在早起,这些微服务是有较大规模请求的,但是后来,项目被遗弃,也没有了流量,但是运行的接口依然在线上。而作为团队管理人员的我甚至没有任何书面上接口汇总的统计信息。
当老板告诉我,把合作公司对接的服务暂停时,我无法做到逻辑上停机返回一个业务异常。作为一个多渠道发展的上游库存供应商,我们对接的渠道很多,提供给客户的接口有很多特别定制的需求,这些需求一般就在中间的逻辑控制代码里面,渠道下线了,也不会做任何调整,因为开发者需要根据需求来进行代码更新。
而且,中间层团队对外联合调试也是长久以来存在的一个问题。经常有前端同事向我抱怨,后端的同事不肯增加数据处理逻辑的代码,而作为前端,他们不得不增加很多转换数据的代码来适配界面的逻辑。而像在小程序这种的对包大小进行限制的环境里,这些代码的移动在发展后期就成为一个老大难问题。
# 网关的选型失败
当时,市面上存在两种类型的解决方案:
中间层的解决方案。中间层方案一般提供裸异步服务、其他插件以及功能根据需求自定义,部分中间层的服务经过改造后也具备网关的部分功能。
网关的解决方案。网关方案一般围绕着微服务全家桶提供,或者自成一派,提供通用型的功能(如路由功能)。当然,部分网关经过自定义改造也能加入中间层的业务功能。
我们的业务发展变化非常快。如果市面上已有的网关方案能满足需求,我们又有能力进行二次开发,我们非常乐意使用。
当时,Eolinker是我们的API 自动测试的供应商,提供了对应的管理型网关,但语言是Go。而我们团队的技术栈主要以Java为主,运维的部署方案也一直围绕着Java,这意味我们的选型就偏窄,因此不得不放弃这一想法。
在之前,我们也选择过Kong网关,但是引入一个新的复杂技术栈是一件成本不低的事情,比如,Lua的招聘与二次开发是难以避免的痛。
另外,Gravitee、Zuul、Vert.x 都是不同小规模团队使用过的网关。谈及最多的特性是:
1、支持熔断、流量控制和过载保护
2、支持特别高的并发
3、秒杀
然而,对商业而言,熔断、流量控制和过载保护应该是最后考虑的措施。而且,对一个成长中的团队来说,服务的过载崩溃是需要经历较长时间的业务沉淀。
另外,秒杀业务的流量更多是维持一个普通水平,其偶尔的高并发也是在我们团队处理能力范围之内。换句话说,选型时,更多的是需要结合实际,而不是考虑类似阿里巴巴的流量,我只需考虑中等水平以上并且具备集群扩展性的方式即可。
此前,我们团队使用比较广的网关是Vert.x,编码风格是这样的,华丽酷炫。
private void dispatchRequests(RoutingContext context) {
int initialOffset = 5; // length of `/api/`
// run with circuit breaker in order to deal with failure
circuitBreaker.execute(future -> { // (1)
getAllEndpoints().setHandler(ar -> { // (2)
if (ar.succeeded()) {
List<Record> recordList = ar.result();
// get relative path and retrieve prefix to dispatch client
String path = context.request().uri();
if (path.length() <= initialOffset) {
notFound(context);
future.complete();
return;
}
String prefix = (path.substring(initialOffset)
.split("/"))[0];
// generate new relative path
String newPath = path.substring(initialOffset + prefix.length());
// get one relevant HTTP client, may not exist
Optional<Record> client = recordList.stream()
.filter(record -> record.getMetadata().getString("api.name") != null)
.filter(record -> record.getMetadata().getString("api.name").equals(prefix)) // (3)
.findAny(); // (4) simple load balance
if (client.isPresent()) {
doDispatch(context, newPath, discovery.getReference(client.get()).get(), future); // (5)
} else {
notFound(context); // (6)
future.complete();
}
} else {
future.fail(ar.cause());
}
});
}).setHandler(ar -> {
if (ar.failed()) {
badGateway(ar.cause(), context); // (7)
}
});
}但是,Vert.x社区缺乏支持以及入门成本高的问题一直存在,而团队甚至找不到更多合适的同事来维护代码。
以上网关的选型失败让我们意识到,市面没有完全符合我们公司的情况的“瑞士军刀”,由此我们开始走上了自研之路,开始进行Fizz网关的设计。
# 走上自研网关之路
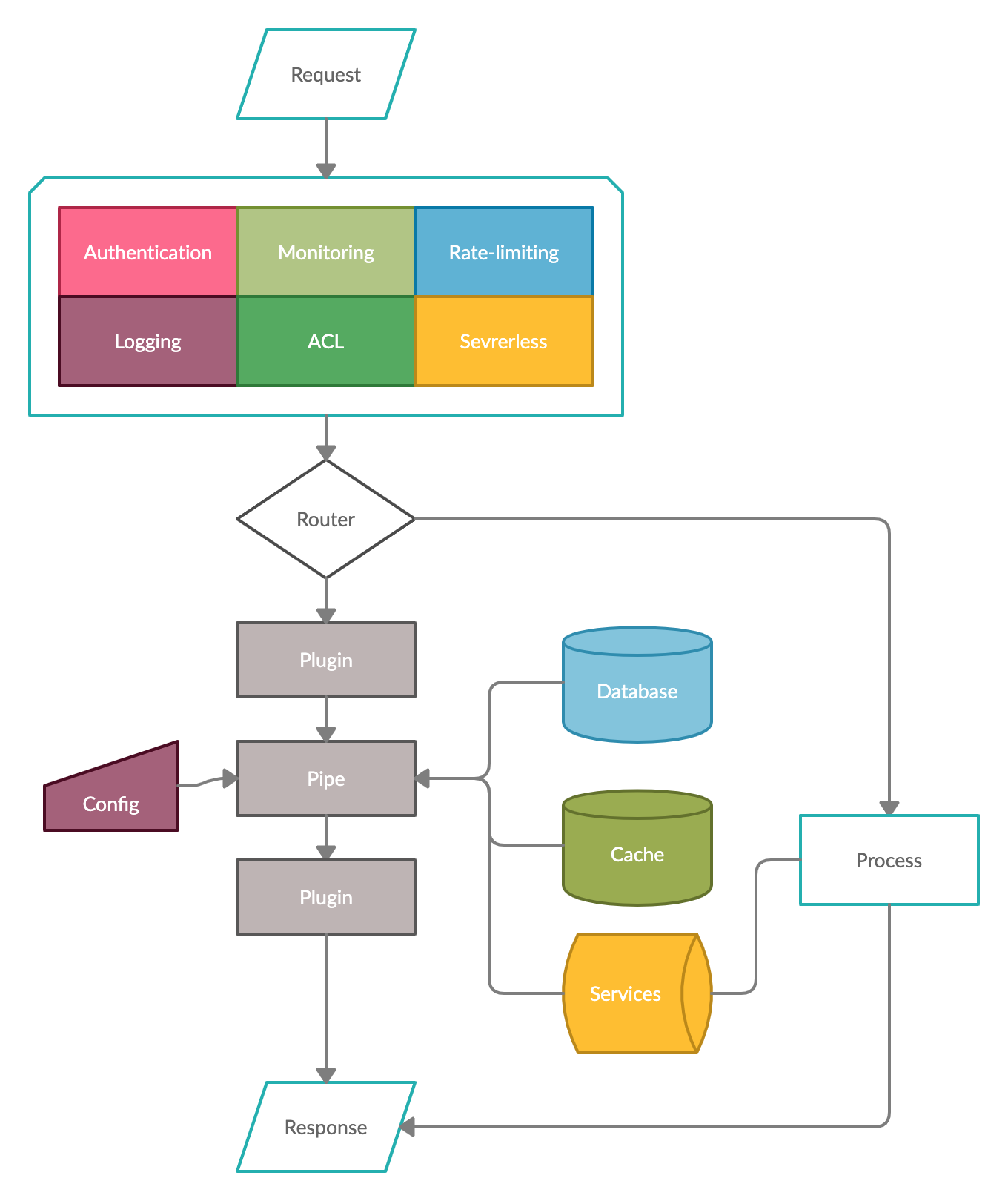
我们需要网关么?网关层解决什么问题?这两个问题不言而喻。我们需要网关,因为它可以帮我们解决负载均衡、聚合、授权、监控、限流、日志、权限控制等一系列的问题。同时,我们也需要中间层,细化服务颗粒度的微服务让我们不得不通过中间层聚合它们。
而我们不需要的是复杂的编码、冗余的胶水代码,以及冗长的发布流程。
为解决这些问题,我们需要让网关与中间层模糊界限,抹去网关和中间层隔阂,让网关支持中间层动态编码,尽可能少的发布部署。为实现这个目的,只需要用一个简洁的网关模型并同时利用low-code特性尽可能地去覆盖中间层的功能即可。
## 从原点出发的需求
在复盘当初这个选择时,我需要再强调下从原点出发的需求:
1、Java技术栈,支持Spring全家桶;
2、方便易用,零培训也能编排;
3、动态路由能力,随时随地能够开启新API;
4、高性能且集群可横向扩展;
5、强热服务编排能力,支持前后端编码,随时随地更新API;
6、线上编码逻辑支持;
7、可扩展的安全认证能力,方便日志记录;
API审核功能,把控所有服务;
可扩展性,强大的插件开发机制;
## Fizz 的技术选型
在选型Spring WebFlux后,因为其单体较强的特性,同事建议命名为Fizz(Fizz是竞技游戏《英雄联盟》中的英雄角色之一,它是一个近战法师,其拥有AP中数一数二的单体爆发,因此可以克制大部分法师,可以作为一个很好地反制英雄使用)。
WebFlux是一个典型非阻塞异步的框架,它的核心是基于Reactor的相关API实现的。 相对于传统的web框架来说,它可以运行在诸如Netty、Undertow和支持Servlet3.1的容器上,因此它运行环境的可选择性要比传统web框架多很多。
而Spring WebFlux 是一个异步非阻塞式的 Web 框架,它能够充分利用多核 CPU 的硬件资源去处理大量的并发请求。其依赖Spring的技术栈,代码风格是这样的:
public Mono<ServerResponse> getAll(ServerRequest serverRequest) {
printlnThread("获取所有用户");
Flux<User> userFlux = Flux.fromStream(userRepository.getUsers().entrySet().stream().map(Map.Entry::getValue));
return ServerResponse.ok()
.body(userFlux, User.class);
}## Fizz的核心实现
对我们而言,这是一个从零开始的项目,很多同事刚开始没有信心。我为这个服务写了第一个服务编排代码的核心包fizz,并把这个commit写为“开工大吉”。
我打算所有的服务聚合的定义就靠一个配置文件解决。那么,就有这样的模型:如果把用户请求作为输入,那么响应自然就是输出,这就是一个管道Pipe;在一个Pipe中,会有不同的Step,对应不同的串联的步骤;而在一个Step,至少有一个存在着一个Input接收上一个步骤处理的输出,所有的Input都是并联的,并且可以并行执行;贯穿于Pipe的生命周期中存在唯一的Context保存中间上下文。
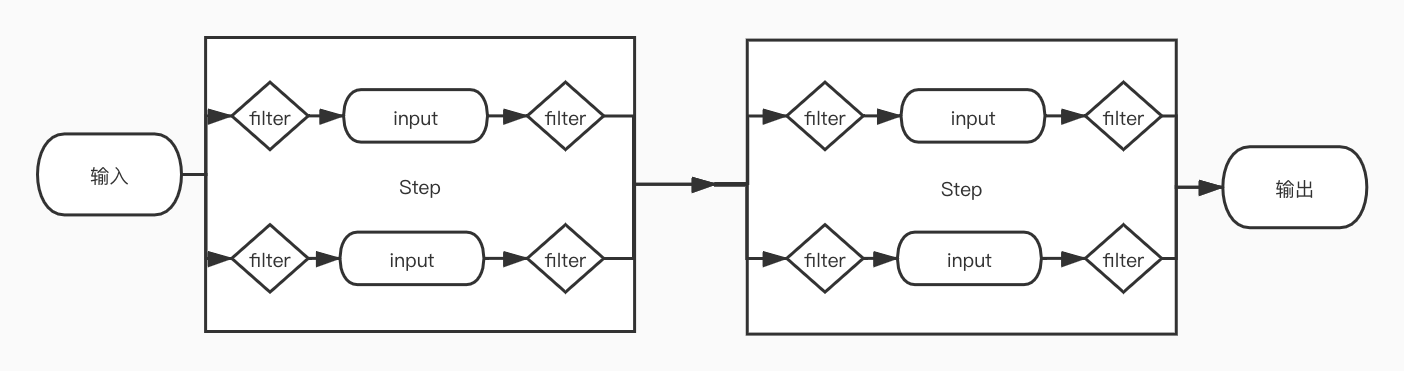
而在每个Input的输入与输出,我增加了动态脚本的扩展能力,到现在已经支持JavaScript和groove两种能力,支持JavaScript的前端逻辑可以在后端得到必要扩展。而我们的配置文件仅仅需要这样一个脚本:
// 聚合接口配置var aggrAPIConfig = {
name: "input name", // 自定义的聚合接口名
debug: false, // 是否为调试模式,默认falsetype: "REQUEST", // 类型,REQUEST/MYSQLmethod: "GET/POST",path: "/proxy/aggr-hotel/hotel/rates", // 格式:/aggr/+服务名+路径, 分组名以aggr-开头,表示聚合接口langDef: { // 可选,提示语言定义,入参验证失败时依据配置提供不同语言的提示信息,目前支持中文、英文langParam: "input.request.body.languageCode", // 入参语言字段langMapping: { // 字段值与语言的映射关系zh: "0", // 中文en: "1" // 英文}},headersDef: { // 可选,定义聚合接口header部分参数,使用JSON Schema规范(详见:http://json-schema.org/specification.html),用于参数验证,接口文档生成type:"object",properties:{ appId:{ type:"string",title:"应用ID",description:"描述"}},required: ["appId"]},paramsDef: { // 可选,定义聚合接口parameter部分参数,使用JSON Schema规范(详见:http://json-schema.org/specification.html),用于参数验证,接口文档生成type:"object",properties:{ lang:{ type:"string",title:"语言",description:"描述"}}},bodyDef: { // 可选,定义聚合接口body部分参数,使用JSON Schema规范(详见:http://json-schema.org/specification.html),用于参数验证,接口文档生成type:"object",properties:{ userId:{ type:"string",title:"用户名",description:"描述"}},required: ["userId"]},scriptValidate: { // 可选,用于headersDef、paramsDef、bodyDef无法覆盖的入参验证场景type: "", // groovysource: "" // 脚本返回List<String>对象,null:验证通过,List:错误信息列表},validateResponse:{ // 入参验证失败响应,处理方式同dataMapping.responsefixedBody: { // 固定的body"code": -411},fixedHeaders: { // 固定header"a":"b"},headers: { // 引用的header},body: { // 引用的header"msg": "validateMsg"},script: { type: "", // groovysource: ""}},dataMapping: { // 聚合接口数据转换规则response:{ fixedBody: { // 固定的body"code":"b"},fixedHeaders: { // 固定header"a":"b"}, headers: { // 引用的header,默认为源数据类型,如果要转换类型则以目标类型+空格开头,如:"int ""abc": "int step1.requests.request1.headers.xyz"},body: { // 引用的header,默认为源数据类型,如果要转换类型则以目标类型+空格开头,如:"int ""abc": "int step1.requests.request1.response.id","inn.innName": "step1.requests.request2.response.hotelName","ddd": { // 脚本, 当脚本的返回对象里包含有_stopAndResponse字段且值为true时,会终请求并把脚本的返回结果响应给浏览器"type": "groovy","source": ""}},script: { // 脚本计算body的值type: "", // groovysource: ""}}},stepConfigs: [{ // step的配置name: "step1", // 步骤名称stop: false, // 是否在执行完当前step就返回dataMapping: { // step response数据转换规则response: {
fixedBody: { // 固定的body"a":"b"},body: { // step result"abc": "step1.requests.request1.response.id","inn.innName": "step1.requests.request2.response.hotelName"},script: { // 脚本计算body的值type: "", // groovysource: ""}}},
requests:[ //每个step可以调用多个接口{ // 自定义的接口名 name: "request1", // 接口名,格式request+N type: "REQUEST", // 类型,REQUEST/MYSQL url: "", // 默认url,当环境url为null时使用devUrl: "http://baidu.com", // testUrl: "http://baidu.com", // preUrl: "http://baidu.com", // prodUrl: "http://baidu.com", // method: "GET", // GET/POST, default GETtimeout: 3000, // 超时时间 单位毫秒,允许1-10000秒之间的值,不填或小于1毫秒取默认值3秒,大于10秒取10秒condition: { type: "", // groovysource: "return \"ABC\".equals(variables.get(\"param1\")) && variables.get(\"param2\") >= 10;" // 脚本执行结果返回TRUE执行该接口调用,FALSE不执行},fallback: { mode: "stop|continue", // 当请求失败时是否继续执行defaultResult: "" // 当mode=continue时,可设置默认的响应报文(json string)},dataMapping: { // 数据转换规则request:{ fixedBody: { },fixedHeaders: { },fixedParams: { },headers: { //默认为源数据类型,如果要转换类型则以目标类型+空格开头,如:"int ""abc": "step1.requests.request1.headers.xyz"},body:{ "*": "input.request.body.*", // * 用于透传一个json对象"inn.innId": "int step1.requests.request1.response.id" // 默认为源数据类型,如果要转换类型则以目标类型+空格开头,如:"int "},params:{ //默认为源数据类型,如果要转换类型则以目标类型+空格开头,如:"int ""userId": "input.requestBody.userId"},script: { // 脚本计算body的值type: "", // groovysource: ""}},response: { fixedBody: { },fixedHeaders: { },headers: { "abc": "step1.requests.request1.headers.xyz"},body:{ "inn.innId": "step1.requests.request1.response.id"},script: { // 脚本计算body的值//type: "", // groovysource: ""}}}}]}]}运行的上下文格式为:
// 运行时上下文,用于保存客户输入和每个步骤的输入与输出结果var stepContext = { // 是否DEBUG模式
debug:false,// elapsed time
elapsedTimes: [{ [actionName]: 123, // 操作名称:耗时}],// input datainput: { request:{ path: "",method: "GET/POST",headers: { },body: { },params: { }},response: { // 聚合接口的响应headers: { },body: { }}},// step namestepName: { // step request datarequests: { request1: { request:{ url: "",method: "GET/POST",headers: { },body: { }},response: { headers: { },body: { }}},request2: { request:{ url: "",method: "GET/POST",headers: { },body: { }},response: { headers: { },body: { }}}//...},// step result result: { }}}当我把Input从仅仅看成一个输入以及输出,加上数据处理的中间过程,那么,它就具备了很大的扩展可能性。比如,在代码中,我们甚至可以编写一个MysqlInput的类,其扩展Input
public class MySQLInput extends Input {
}其仅仅需要定义Input的少量类方法,就能支持MySQL的输入,甚至与动态解析MySQL脚本,并且做数据解析变换。
public class Input {
protected String name;
protected InputConfig config;
protected InputContext inputContext;
protected StepResponse lastStepResponse = null;
protected StepResponse stepResponse;
public void setConfig(InputConfig inputConfig) {
config = inputConfig;
}
public InputConfig getConfig() {
return config;
}
public void beforeRun(InputContext context) {
this.inputContext = context;
}
public String getName() {
if (name == null) {
return name = "input" + (int)(Math.random()*100);
}
return name;
}
/**
* 检查该Input是否需要运行,默认都运行
* @stepContext Step上下文
* @return TRUE:运行
*/
public boolean needRun(StepContext<String, Object> stepContext) {
return Boolean.TRUE;
}
public Mono<Map> run() {
return null;
}
public void setName(String configName) {
this.name = configName;
}
public StepResponse getStepResponse() {
return stepResponse;
}
public void setStepResponse(StepResponse stepResponse) {
this.stepResponse = stepResponse;
}
}而扩展编码的内容并不会涉及异步处理问题。这样,Fizz已经较为友好地处理了异步逻辑。
## Fizz的服务编排
可视化的后台可以进行Fizz的服务编排功能,虽然以上的核心代码并不是很复杂,但是其已经足够将我们整个步骤抽象化。现在,可视化的界面通过fizz-manager只需要生成对应的配置文件,并且让其可以快速地更新加载即可。通过定义的Request Input中的请求头、请求体和Query参数,以及校验规则或者自定义脚本实现复杂的逻辑校验,在定义其Fallback,我们实现了一个Request Input,通过一些的Step组装,最终一个经过线上编排的服务就能实时投入使用。如果是只读接口,甚至我们建议直接在线实时测试,当然支持测试接口和正式接口隔离,支持返回上下文,可以查看整个执行过程中各个步骤和请求的输入与输出。
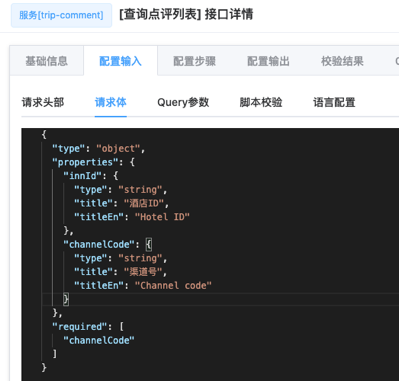
## Fizz的脚本验证
当内置的脚本验证方式不足够覆盖场景时,Fizz还提供更灵活的脚本编程。
// javascript脚本函数名不能修改function dyFunc(paramsJsonStr) {
// 上下文, 数据结构请参考 context.js
var context = JSON.parse(paramsJsonStr)['context'];
// common为内置的上下文便捷操作工具类,详情请参考common.js;例如:
// var data = common.getStepRespBody(context, 'step2', 'request1', 'data');
// do something
// 自定义返回结果,如果返回的Object里含有_stopAndResponse=true字段时将会终止请求并把脚本结果响应给客户端(主要用于有异常情况要终止请求的场景)
var result = { // _stopAndResponse: true,msgCode: '0',message: '',data: null
};
// 返回结果为Array或Object时要先转为json字符串
return JSON.stringify(result);}## Fizz的数据处理
Fizz具备对请求的输入和输出进行数据变换的能力,它充分利用了json path的特性通过加载配置文件的定义对Input的输入以及输出进行变化以便得到合理结果。
## Fizz的强大路由
Fizz的动态路由功能也设计得较为实用。它有一套平滑替换网关的方案。在最初,Fizz是可以跟其他网关并存的,比如之前提到的基于Vert.x的网关。所以,Fizz就有一个类似Nginx的反向代理方案,纯粹基于路由的实现。于是,在项目初期,通过Nginx的流量被原原本本的转发到Fizz,然后再到Vert.x,其代理了Vert.x全部流量。之后,流量被逐步转发到后端的微服务,Vert.x上有一部分特别定制的公用代码被下沉到底层微服务端,Vert.x还有中间层服务被完全废弃,服务器的数量减少50%。在我们做完调整后,原先困扰我的中间层人员以及服务器的问题终于得到解决,我们可以缩减每个同事手中的那一串服务列表清单,将工作落到更有价值的项目上去。当这一切变得清晰时,这个项目也就自然而然显示了它的价值。
针对渠道,这里的路由功能也有非常实用的功能。因为Fizz服务组概念的存在,让它能针对不同渠道设置不同的组,从而解决渠道差别的问题。实际上,线上可以存在多组不同版本的API,也同时变相的解决API版本管理的问题。
## Fizz的可扩展鉴权
Fizz针对授权也有特别的解决方案。我们公司组建比较早,团队里有多年编写的老旧代码,所以在代码上也会有多种鉴权方式。同时,另外也有外部平台支持方面的问题,比如在App和在微信上的代码,就需要使用不同的鉴权支持。
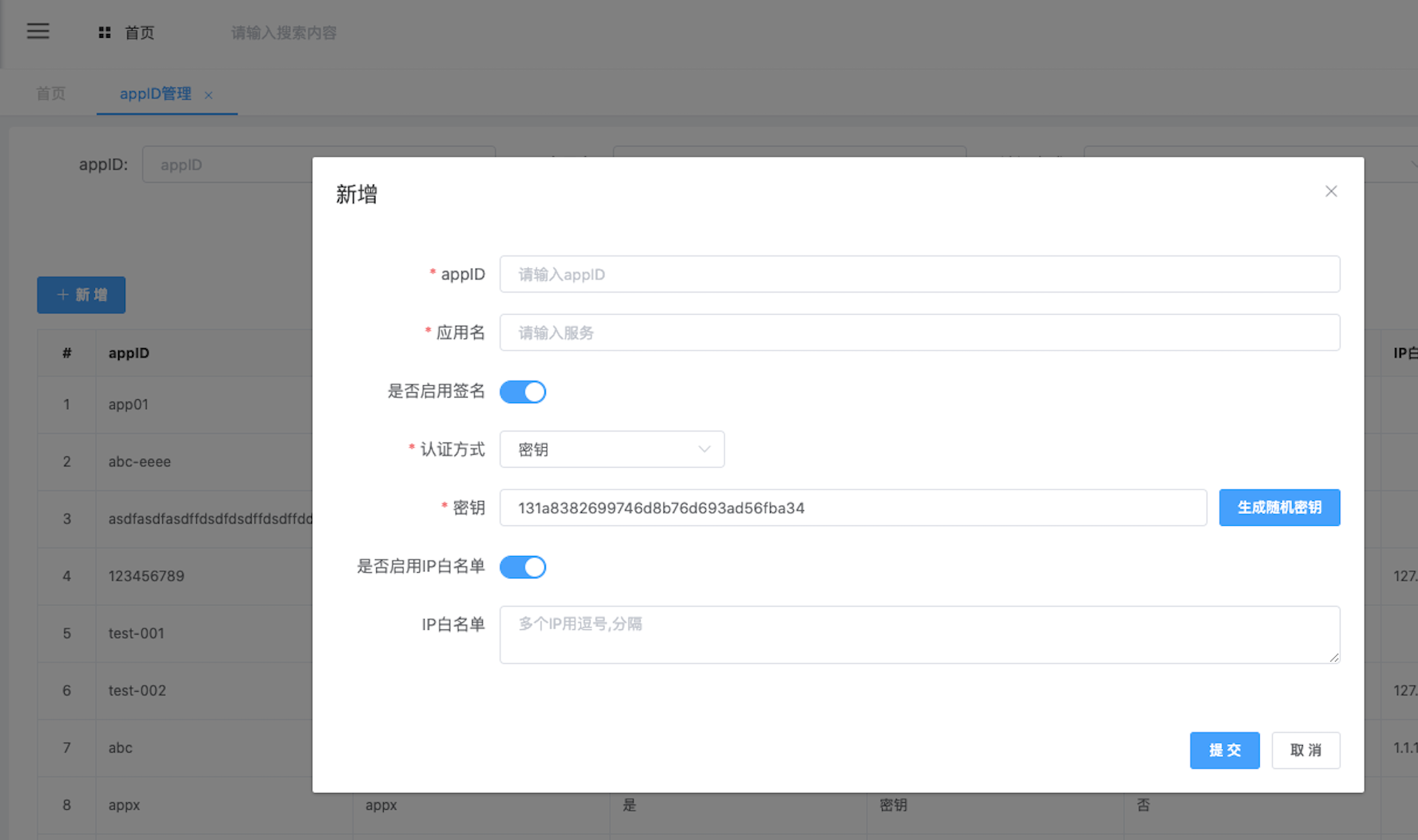
上图显示的是通过的配置方式的验签配置。实际上,Fizz提供了两种方式:一种公用的内置验签,一种是自定义插件验签。用户使用时通过下拉菜单就能进行方便选择。
## Fizz的插件化设计
在Fizz设计初期,我们就充分考虑到插件的重要性,因此设计了方便实现的插件标准。当然,这个需要开发者会对异步编程有很深的了解,这个特性适合有定制需求的团队。插件仅仅需要继承PluginFilter即可,并且只有两个函数需要被实现:
public abstract class PluginFilter { private static final Logger log = LoggerFactory.getLogger(PluginFilter.class);public Mono<Void> filter(ServerWebExchange exchange, Map<String, Object> config, String fixedConfig) { return Mono.empty();}public abstract Mono<Void> doFilter(ServerWebExchange exchange, Map<String, Object> config, String fixedConfig);}## Fizz的管理功能
中大型企业的资源保护也是相当重要。一旦所有的流量通过Fizz,便需要在Fizz建立对应的路由功能,而对应的API审核制度也是其一大特点,所有公司API接口的资源都被方便的保护起来,有严格的审核机制保证每个API都是经过团队的管理人员审核。并且,它具备API快速下线功能以及降级响应功能。
## Fizz的其他功能
当然,Fizz适配Spring的全家桶,使用配置中心Apollo,能够进行均衡负载,访问日志、黑白名单等一系列我们认为该有的网关功能。
# Fizz的性能问题
虽然不以性能作为卖点,但是这并不代表着Fizz的性能就很差。得益与WebFlux的加成,我们将Fizz与官方spring-cloud-gateway进行比较,使用相同的环境和条件,测试对象均为单个节点。测试结果,我们的QPS比spring-cloud-gateway略高。当然,我们还有想当的想象空间可以优化。
Intel® Xeon® CPU X5675 @ 3.07GHz
Linux version 3.10.0-327.el7.x86_64
Intel® Xeon® CPU X5675 @ 3.07GHz
Linux version 3.10.0-327.el7.x86_64
| 条件 | QPS(/s) | 90% Latency(ms) |
| — | — | — |
| 直接访问后端 | 9087.46 | 10.76 |
| fizz-gateway | 5927.13 | 19.86 |
| spring-cloud-gateway | 5044.04 | 22.91 |
在设计Fizz之初,我们就考虑到企业内部复杂的中间层情况:它可以截流所有的流量,能并行且逐步替换现有网关。所以在内部推行时,Fizz很顺利。最初研发时,我们选取了C端业务作为目标业务,发布上线时仅替换其中部分复杂的场景,经过一个季度的试用,我们解决了性能和内存等各种问题。在版本稳定后,Fizz被推广到整个BU的业务线替代原先繁多的应用网关,紧接着是整个公司的适用的业务都开始使用。原来我们C端、B端两个中间层团队研发能够腾出手来从事底层业务的研发,中间层人员虽然减少了,但是研发效率却有很大提升,比如原先需要多天开发的一组复制型服务研发时间缩短为之前的七分之一。借助Fizz,我们开展进行服务合并工作,中间层的服务器减少50%,而服务的承载能力却是上升的。
# Fizz的交流发展
前期,Fizz仅依靠配置就开始规模化的使用,但随着使用人数的增加,配置文件编写和管理需要让我们开始扩展这个项目。现在,Fizz包含两个主要的后端项目fizz-gateway、 fizz-manager。fizz-admin是作为Fizz的前端配置界面,fizz-manager与fizz-admin为Fizz提供图形化的配置界面。所有的Pipe都能够在操作界面进行编写以及上线。
为了能让更多的中大型快速发展的团队能够应用上这个面向管理,解决实际问题的网关,Fizz提供了fizz-gateway-community社区版本的解决方案,而且作为对外技术的交流,其技术的核心实现将会以GNU v3授权方式进行的开放。fizz-gateway-community的所有API将会公布以便二次开发使用。因为fizz-gateway-professional专业版本与团队业务绑定,所以进行商业封闭。而对应的管理平台代码fizz-manger-professional作为商业版本开放二进制包的免费下载,提供给使用了GNU v3开源协议的项目免费使用(如果您的项目是商业性质,请联系我们进行授权)。另外,Fizz已有的丰富插件我们也会选择合适的时机与各位交流。
无论我们的项目交流是否能帮到各位,我们真诚希望能得到各位的反馈。不管项目技术是否牛逼,完善与否,我们始终不忘初心:Fizz,一个面向大中型企业的管理型网关。
“性能超高的API网关之怎么使用Fizz Gateway”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/linwaiwai/blog/4696137



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



