这篇文章将为大家详细讲解有关OLM是如何管理越来越多的operator,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
导读:OLM(Operator Lifecycle Manager) 作为 Operator Framework 的一部分,可以帮助用户进行 Operator 的自动安装,升级及其生命周期的管理。同时 OLM 自身也是以 Operator 的形式进行安装部署,可以说它的工作方式是以 Operators 来管理 Operators,而它面向 Operator 提供了声明式 (declarative) 的自动化管理能力也完全符合 Kubernetes 交互的设计理念。下面我们将来了解一下 OLM 的基本架构和安装使用。
OLM 的出现是为了帮助没有如大数据,云监控等领域知识的用户能够自助式地部署并管理像 etcd、大数据分析或监控服务等复杂的分布式应用。因此从它的设计目标来说,OLM 官方希望实现面向云原生应用提供以下几个方向上的通用管理能力,包括:
生命周期管理:管理 operator 自身以及监控资源模型的升级和生命周期;
服务发现:发现在集群中存在哪些 operator,这些 operators 管理了哪些资源模型以及又有哪些 operators 是可以被安装在集群中的;
打包能力:提供一种标准模式用于 operator 以及依赖组件的分发,安装和升级;
交互能力:在完成了上述能力的标准化后,还需要提供一种规范化的方式(如 CLI)与集群中用户定义的其他云服务进行交互。
上述在设计上的目标可以归结为下面几个方向上的需求:
命名空间部署:operator 和其管理资源模型必须被命名空间限制部署,这也是在多租环境下实现逻辑隔离和使用 RBAC 增强访问控制的必要手段;
使用自定义资源(CR)定义:使用 CR 模型是定义用户和 operator 读写交互的首选方式;同时在一个 operator 中也是通过 CRDs 声明其自身或被其他 operator 管理的资源模型;operator 自身的行为模式配置也应当由 CRD 中的 fields 定义;
依赖解析:operator 在实现上只需要关心自身和其管理资源的打包,而不需关注与运行集群的连接;同时在依赖上使用动态库定义,这里以 vault-operator 为例,其部署的同时需要创建一个 etcd 集群作为其后端存储;这时我们在 vault-operator 中不应该直接包含 etcd operator 对应容器,而是应该通过依赖声明的方法让 OLM 解析对应依赖。为此在 operators 中需要有一套依赖相关的定义规范;
部署的幂等性:依赖解析和资源安装可以重复执行,同时在应用安装过程中的问题是可恢复的;
垃圾收集:原则上尽可能依赖 Kubernetes 原生的垃圾收集能力,在删除 OLM 自身的扩展模型 ClusterService 时需要同时清理其运行中的关联资源;同时需要保证其他 ClusterService 管理的资源不被删除;
支持标签和资源发现。
基于上述设计目标,OLM 在实现中面向 Operator 定义了如下模型和组件。
首先,OLM 自身包含两个 Operator:OLM Operator 和 Catalog Operator。它们分别管理了如下几个 OLM 架构中扩展出的基础 CRD 模型:
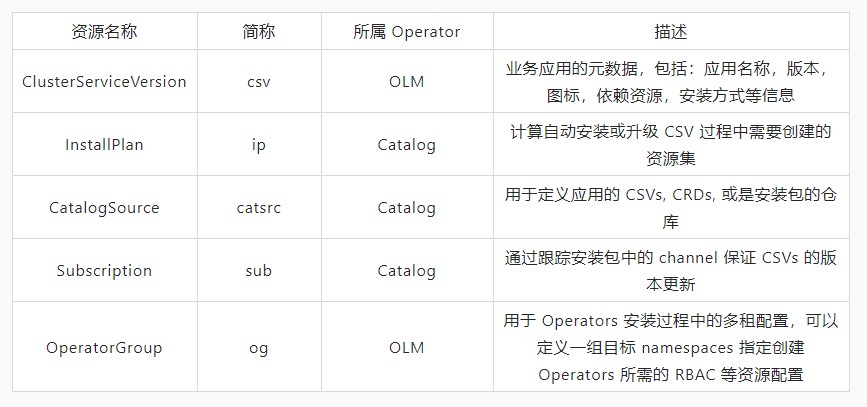
在 Operator 安装管理的生命周期中 Deployment,Serviceaccount,RBAC 相关的角色和角色绑定是通过 OLM operator 创建的;Catalog Operator 负责 CRDs 和 CSVs 等资源的创建。
在介绍 OLM 的两个 Operator 之前,我们先来看下 ClusterServiceVersion 的定义,作为 OLM 工作流程中的基本元素,它定义了在 OLM 管理下用户业务应用的元数据和运行时刻信息的集合,包括了:
应用元数据(名称,描述,版本定义,链接,图标,标签等),在下一章的实战示例中我们会看到具体的定义;
安装策略,包括 Operator 安装过程中所需的部署集合和 service accounts,RBAC 角色和绑定等权限集合;
CRDs:包括 CRD 的类型,所属服务,Operator 交互的其他 K8s 原生资源和 spec,status 这些包含了模型语义信息的 fields 字段描述符等。
在对 ClusterServiceVersion 的概念有了基本了解后,我们来看下 OLM Operator。
首先 OLM Operator 的工作会基于 ClusterServiceVersion,一旦 CSV 中声明的依赖资源都已经在目标集群中注册成功,OLM Operator 就会负责去安装这些资源对应的应用实例。注意这里 OLM Operator 并不会去关注 CSV 中声明的依赖资源对应的 CRD 模型的创建注册等工作,这些动作可以由用户的手工 kubectl 操作或是由 Catalog Opetator 来完成。这样的设计也给了用户一个逐步适应 OLM 架构并最终应用起来的熟悉过程。另外,OLM Operator 对依赖资源对应自定义模型的监听可以是全局 all namespaces 的,也可以只限定在指定的 namespace 下。
接着我们来认识一下 Catalog Operator,它主要负责解析 CSV 中声明的依赖资源定义,同时它通过监听 catalog 中安装包对应 channels 的版本定义完成 CSV 对应的版本更新。
用户可以通过创建 Subscription 模型来设置 channel 中所需安装包和更新的拉取源,当一个可用更新被发现时,一个用户对应的 InstallPlan 模型会在相应的 namespace 被创建出来。当然用户也可以手动创建 InstallPlan,InstallPlan 实例中会包含目标 CSV 的定义和相关的 approval 审批策略,Catalog Operator 会创建相应的执行计划去创建 CSV 所需的依赖资源模型。一旦用户完成审批,Catalog Operator 就会创建 InstallPlan 中的相关资源,此时刚才提及的 OLM Operator 关注的依赖资源条件得到满足,CSV 中定义的 Operator 实例会由 OLM Operator 完成创建。
在上一小节中我们了解了 OLM 的基本组件模型和相关定义,本小节我们就来介绍一下它的基本架构,如下图所示:
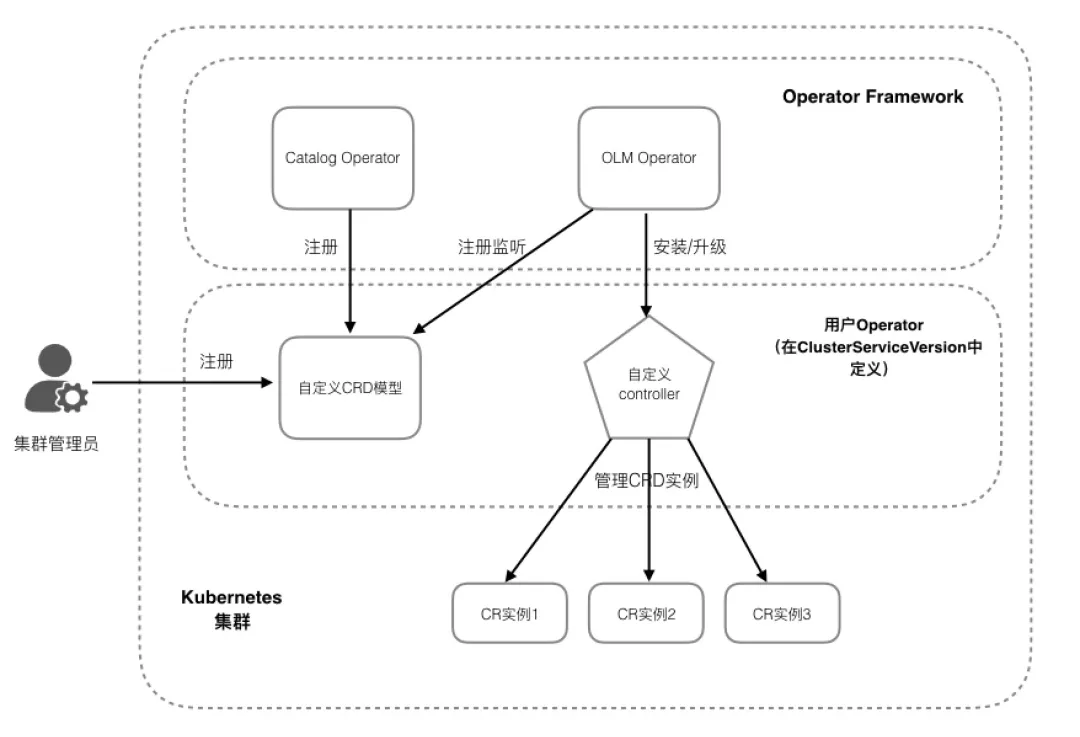
首先在 Operator Framework 中提供了两个重要的元 Operator 和相应的扩展资源(如上节中介绍的 ClusterServiceVersion,InstallPlan 等),用于进行用户应用 Operator 的生命周期管理。在自定义的 CSV 模型中定义了用户部署 Operator 的各类资源组合,包括 Operator 是如何部署的,Operator 对应管理的自定义资源类型是什么以及使用了哪些 K8s 原生资源等。
在上节的定义中我们也了解到 OLM Operator 在安装对应的 Operator 实例前要求其管理的自定义资源模型已经被注册在目标安装集群中,而这个动作可以来自于集群管理员手动 kubectl 方式的创建,也可以利用 Catalog Operator 完成,Catalog Operator 除了可以完成目标CRD模型的注册,还负责资源模型版本的自动升级工作。其工作流程包括:
保证 CRDs 和 CSVs 模型的 cache 和 index 机制,用于对应模型的版本控制和注册等动作;
监听用户创建的未解析 InstallPlans:
寻找满足依赖条件的 CSV 模型并将其加入到已解析资源中;
将所有被目标 Operator 管理或依赖的 CRD 模型加入到解析资源中;
寻找并管理每种依赖 CRD 对应 CSV 模型;
监听所有被解析的 InstallPlan,在用户审批或自动审批完成后创建所有对应的依赖资源;
监听 CataologSources 和 Subscriptions 模型并基于其变更创建对应的 InstallPlans。
一旦 OLM Operator 监听到 CSV 模板中安装所需依赖资源已经注册或是变更,就会启动应用 Operator 的安装和升级工作,并最终启动 Operator 自身的工作流程,在 Kubernetes 集群中创建和管理对应的自定义资源实例模型。
在了解了 OLM 的基础架构后,我们首先来看下 OLM 的安装。在社区代码中我们找到 OLM 各项部署资源对应的模板,用户可以方便的通过修改相应部署参数完成定制化的 OLM 安装。
在官方的发布公告中我们可以找到最新的发布版本和各版本对应的安装说明。
这里以 0.13.0 版本为例,通过以下命令执行自动化安装脚本:
curl -L https://github.com/operator-framework/operator-lifecycle-manager/releases/download/0.13.0/install.sh -o install.sh
chmod +x install.sh
./install.sh 0.13.0手动安装 OLM 所需部署模板命令:
kubectl apply -f https://github.com/operator-framework/operator-lifecycle-manager/releases/download/0.13.0/crds.yaml kubectl apply -f https://github.com/operator-framework/operator-lifecycle-manager/releases/download/0.13.0/olm.yaml
在通过 clone OLM 代码仓库到本地后,用户可以执行 make run-local 命令启动 minikube,并通过 minikube 自带 docker daemon 在本地 build OLM 镜像,同时该命令会基于仓库 deploy 目录下的 local-values.yaml 作为配置文件构建运行本地 OLM,通过 kubectl -n local get deployments 可以验证 OLM 各组件是否已经成功安装运行。
另外针对用户的定制化安装需求,OLM 支持通过配置如下模板指定参数来生成定制化的部署模板并安装。下面是其支持配置的模板参数:
# sets the apiversion to use for rbac-resources. Change to `authorization.openshift.io` for openshift
rbacApiVersion: rbac.authorization.k8s.io
# namespace is the namespace the operators will _run_
namespace: olm
# watchedNamespaces is a comma-separated list of namespaces the operators will _watch_ for OLM resources.
# Omit to enable OLM in all namespaces
watchedNamespaces: olm
# catalog_namespace is the namespace where the catalog operator will look for global catalogs.
# entries in global catalogs can be resolved in any watched namespace
catalog_namespace: olm
# operator_namespace is the namespace where the operator runs
operator_namespace: operators
# OLM operator run configuration
olm:
# OLM operator doesn't do any leader election (yet), set to 1
replicaCount: 1
# The image to run. If not building a local image, use sha256 image references
image:
ref: quay.io/operator-framework/olm:local
pullPolicy: IfNotPresent
service:
# port for readiness/liveness probes
internalPort: 8080
# catalog operator run configuration
catalog:
# Catalog operator doesn't do any leader election (yet), set to 1
replicaCount: 1
# The image to run. If not building a local image, use sha256 image references
image:
ref: quay.io/operator-framework/olm:local
pullPolicy: IfNotPresent
service:
# port for readiness/liveness probes
internalPort: 8080用户可以通过以下方式进行模板的定制化开发和在指定集群中的安装:
创建名称如 my-values.yaml 的配置模板,用户可以参考上述模板配置所需参数;
基于上述配置好的 my-values.yaml 模板,使用 package_release.sh 生成指定部署模板;
# 第一个参数为系统兼容的helm chart目标版本
# 第二个参数为模板指定的输出目录
# 第三个参数为指定的配置文件路径
./scripts/package_release.sh 1.0.0-myolm ./my-olm-deployment my-values.yaml部署指定目录下的模板文件,执行 kubectl apply -f ./my-olm-deployment/templates/;
最后,用户可以通过环境变量 GLOBAL_CATALOG_NAMESPACE 定义 catalog operator 监听全局 catalogs 的指定 namespace,默认情况下安装过程会创建 olm 命名空间并部署 catalog operator。
如同 apt/dkpg 和 yum/rpm 对于系统组件包的管理一样,OLM 在管理 Operator 版本时也会遇到依赖解析和正在运行的 operator 实例的升级管理等问题。为了保证所有 operators 在运行时刻的可用性,OLM 在依赖解析和升级管理流程中需要保证:
不去安装未注册依赖 APIs 的 Operator 实例;
如果对于某个 Operator 的升级操作会破坏其关联组件的依赖条件时,不去进行该升级操作。
下面我们通过一些示例来了解下当前 OLM 是如何处理版本迭代下的依赖解析:
首先介绍一下 CRD 的升级,当一个待升级的 CRD 只属于单个 CSV 时,OLM 会立即对 CRD 进行升级;当 CRD 属于多个 CSV 时,CRD 的升级需要满足下列条件:
所有当前 CRD 使用的服务版本需要包含在新的 CRD 中;
所有关联了 CRD 已有服务版本的 CR(Custom Resource)实例可以通过新 CRD schema 的校验。
当你需要添加一个新版本的 CRD 时,官方推荐的步骤是:
假如当前我们有一个正在使用的 CRD,它的版本是 v1alpha1,此时你希望添加一个新版本 v1beta1 并且将其置为新的 storage 版本,如下:
versions:
- name: v1alpha1
served: true
storage: false
- name: v1beta1
served: true
storage: true如果你的 CSV 中需要使用新版本的 CRD,我们需要保证 CSV 中的 owned 字段所引用的 CRD 版本是新的,如下所示:
customresourcedefinitions:
owned:
- name: cluster.example.com
version: v1beta1
kind: cluster
displayName: Cluster推送更新后的 CRD 和 CSV 到指定的仓库目录中。
当我们需要弃用或是删除一个 CRD 版本时,OLM 不允许立即删除一个正在使用中的 CRD 版本,而是需要首先通过将 CRD 中的 serverd 字段置为 false 来弃用该版本,然后这个不被使用的版本才会在接下来的 CRD 升级过程中被删除。官方推荐的删除或弃用一个 CRD 指定版本的步骤如下:
将过期的弃用 CRD 版本对应的 serverd 字段标记为 false, 表示不再使用该版本同时会在下次升级时删除此版本,如:
versions:
- name: v1alpha1
served: false
storage: true如果当前即将过期的 CRD 版本中 storage 字段为 true,需要将其置为 false 同时将新版本的 storage 对应字段置为 true,比如:
versions:
- name: v1alpha1
served: false
storage: false
- name: v1beta1
served: true
storage: true基于上述修改更新 CRD 模型;
在随后的升级过程中,不在服务的过期版本将会从 CRD 中完成删除,CRD 的版本终态为:
versions:
- name: v1beta1
served: true
storage: true注意在删除指定版本的 CRD 过程中,我们需要保证该版本同时在 CRD status 中的 storedVersion 字段队列中被删除。当 OLM 发现某 storedversion 在新版本 CRD 中不会再使用时会帮助我们完成相应的删除动作。另外我们需要保证 CSV 中关联引用的 CRD 版本在老版本被删除时及时更新。
下面我们来看一下两个会引发升级失败的示例以及 OLM 的依赖解析逻辑:
示例 1:假如我们有 A 和 B 两个不同类型的 CRD。
使用 A 的 Operator 依赖 B
使用 B 的 Operator 有一个订阅(Subscription)
使用 B 的 Operator 升级到了新版本 C 同时弃用了老版本 B
这样的升级得到的结果是 B 对应的 CRD 版本没有了对应使用它的 Operator 或 APIService,同时依赖它的 A 也将无法工作。
示例 2:假如我们有 A 和 B 两个自定义 API。
使用 A 的 Operator 依赖 B
使用 B 的 Operator 依赖 A
使用 A 的 Operator 希望升级到 A2 版本同时弃用老版本 A,新的 A2 版本依赖 B2
使用 B 的 Operator 希望升级到 B2 版本同时弃用老版本 B,新的 B2 版本依赖 A2
此时如果我们只尝试升级 A 而没有同步地升级 B,即使系统可以找到适用的升级版本,也无法完成对应 Operator 的版本升级。
为了避免上述版本迭代中可能遇到的问题,OLM 所采用的依赖解析逻辑如下。
假设我们有运行在某一个 namespace 下的一组 operator:
对于该 namespace 下的每一个 subscription 订阅,如果该 subscription 之前没有被检查过,OLM 会寻找订阅对应 source/package/channel 下的最新版本 CSV,并临时性地创建一个匹配新版本的 operator;如果是已知订阅,OLM 会查询对应 source/package/channel 的更新;
对于 CSV 中所依赖的每一个 API 版本,OLM 都会按照 sources 的优先级挑选一个对应的 operator,如果找到同样会临时性地添加该依赖版本的新 operator,如果没有找到对应的 operator 的话也会添加该依赖 API;
此时如果有不满足 source 依赖条件的 API,系统会对被依赖的 operator 进行降级(回退到上一个版本);为了满足最终的依赖条件,这个降级过程会持续进行,最坏的情况下该 namespace 下的所有 operator 仍旧保持原先版本;
如果有新的 operator 完成解析并满足了依赖条件,它会在集群中最终创建出来;同时会有一个相关的 subscription 去订阅发现它的 channel/package 或是 source 以继续查看是否有新版本的更新。
在了解了 OLM 的依赖解析和升级管理的基本原理后,我们来看下 OLM 升级相关的工作流程。首先从上文中我们已经有所了解,ClusterServiceVersion(CSV),CatalogSource 和 Subscription 是 OLM 框架中和升级紧密相关的三种扩展模型。在 OLM 的生态系统中,我们通过 CatalogSource 来存储如 CVS 这样的 operator 元数据;OLM 会基于 CatalogSources,使用下 Operator 仓库相关 API 去查询可用或可升级的 operators;而在 CatalogSource 中,operators 通过 channels 来标识封装好的不同版本安装包。
当用户希望升级某个 operator 时,可以通过 Subscription 来订阅具体需要安装哪个 channel 中指定版本的软件包。如果订阅中指定的包还没有被安装在目标集群中时,OLM 会安装在 catalog/package/channel 等下载源的最新版本 operator。
在一个 CSV 定义中,我们可以通过 replaces 字段声明需要替换的 operator,OLM 在收到请求后会从不同的 channels 中寻找能够被安装的 CSV 定义并最终将它们构建出一个 DAG(有向无环图),在这个过程中 channels 可以被认为是更新 DAG 的入口。在升级过程中,如果 OLM 发现在可升级的最新版本和当前版本之间还有未安装的中间版本,系统会自动构建出一条升级路径并保证路径上中间版本的安装。比如当前我们有一个正在运行的 operator,它的运行版本是 0.1.1,此时 OLM 在收到更新请求后通过订阅的 channel 找到了 0.1.3 的最新可升级版本,同时还找到了 0.1.2 这个中间版本,此时 OLM 会首先安装 0.1.2 版本 CSV 中对应的 operator 替换当前版本,并最终安装 0.1.3 替换安装成功后的 0.1.2 版本。
当然在某些状况下,比如我们遇到了一个存在严重安全漏洞的中间版本时,这样迭代升级每个版本的方式并不是一种合理和安全的方式。此时我们可以通过 skips 字段定制化安装路径以跳过指定的中间版本,如下所示:
apiVersion: operators.coreos.com/v1alpha1
kind: ClusterServiceVersion
metadata:
name: etcdoperator.v0.9.2
namespace: placeholder
annotations:
spec:
displayName: etcd
description: Etcd Operator
replaces: etcdoperator.v0.9.0
skips:
- etcdoperator.v0.9.1如果需要忽略多个版本的安装,我们可以在 CSV 中使用如下定义:
olm.skipRange: <semver range>其中版本范围的定义可参考 semver,一个 skipRange 的 CSV 示例如下:
apiVersion: operators.coreos.com/v1alpha1
kind: ClusterServiceVersion
metadata:
name: elasticsearch-operator.v4.1.2
namespace: placeholder
annotations:
olm.skipRange: '>=4.1.0 <4.1.2'在 OLM 中,我们可以通过对 CatalogSource 模型来定义 InstallPlan 从哪里完成安装包的自动下载和依赖解析,同时 Subscription 通过对 channel 的订阅也可以从 CatalogSource 来拉取最新版本的安装包。本小节中我们以官方社区的 operator-registry 为例介绍一下 CatalogSource 的安装和基本使用方法。
operator-registry 主要由下列三部分组成:
initializer:负责接收用户上传的以目录为结构的 operator manifests,同时将数据导入到数据库中;
registry-server:包含存取 operator manifests 相关的 sqlite 数据库服务,同时对外暴露 gRPC 协议接口的服务;
configmap-server:负责向 registry-server 提供解析好的 operator manifest 相关 configmap(包含 operator bundle 相关的标签或 CRD 和 CSV 等配置元数据),并存入 sqlite 数据库中。
关于 operator manifes 的格式定义,在 operator-registry 中把在上传目录中包含的每一个 CSV 定义单元称为一个“bundle”,每个典型的 bundle 由单个 CSV(ClusterServiceVersion)和包含其相关接口定义的单个或多个 CRD 组成,如下所示:
# bundle示例
0.6.1
├── etcdcluster.crd.yaml
└── etcdoperator.clusterserviceversion.yaml当导入 manifests 到数据库时会包含如下的格式校验:
每个 package 安装包都需要至少定义一个 channel;
每一个 CSV 需要关联一个安装包中存在的 channel;
每一个 bundle 目录中有且仅有一个对应的 CSV 定义;
如果 CSV 中包含相关 CRD 定义,该 CRD 必须也存在于 bundle 所在目录中;
如果一个 CSV 在 replaces 定义中被其他 CSV 取代,则对应的新旧 CSV 均需要存在于 package 中。
对于 manifests 中不同软件包对应的 bundle 目录格式,原则上最好要保持一个清晰的目录结构,这里我们来看官方的一个 manifest 示例,其他 manifest 示例请见:
manifests
├── etcd
│ ├── 0.6.1
│ │ ├── etcdcluster.crd.yaml
│ │ └── etcdoperator.clusterserviceversion.yaml
│ ├── 0.9.0
│ │ ├── etcdbackup.crd.yaml
│ │ ├── etcdcluster.crd.yaml
│ │ ├── etcdoperator.v0.9.0.clusterserviceversion.yaml
│ │ └── etcdrestore.crd.yaml
│ ├── 0.9.2
│ │ ├── etcdbackup.crd.yaml
│ │ ├── etcdcluster.crd.yaml
│ │ ├── etcdoperator.v0.9.2.clusterserviceversion.yaml
│ │ └── etcdrestore.crd.yaml
│ └── etcd.package.yaml
└── prometheus
├── 0.14.0
│ ├── alertmanager.crd.yaml
│ ├── prometheus.crd.yaml
│ ├── prometheusoperator.0.14.0.clusterserviceversion.yaml
│ ├── prometheusrule.crd.yaml
│ └── servicemonitor.crd.yaml
├── 0.15.0
│ ├── alertmanager.crd.yaml
│ ├── prometheus.crd.yaml
│ ├── prometheusoperator.0.15.0.clusterserviceversion.yaml
│ ├── prometheusrule.crd.yaml
│ └── servicemonitor.crd.yaml
├── 0.22.2
│ ├── alertmanager.crd.yaml
│ ├── prometheus.crd.yaml
│ ├── prometheusoperator.0.22.2.clusterserviceversion.yaml
│ ├── prometheusrule.crd.yaml
│ └── servicemonitor.crd.yaml
└── prometheus.package.yaml通过官方提供的 Dockerfile 我们可以构建出一个包含了 initializer 和 registry-server 的最小集 operator-registry 镜像。
下面我们来看下 operator-registry 与 OLM 的集成,这里我们需要创建一个 CatalogSource 对象并指定使用我们 operator-registry 对应镜像,如下所示:
apiVersion: operators.coreos.com/v1alpha1
kind: CatalogSource
metadata:
name: example-manifests
namespace: default
spec:
sourceType: grpc
image: example-registry:latest当上面的 example-manifest 完成启动后,我们可以通过 pod 日志查看相应的 gRPC 后端服务是否已建立:
$ kubectl logs example-manifests-wfh6h -n default
time="2019-03-18T10:20:14Z" level=info msg="serving registry" database=bundles.db port=50051同时一旦 catalog 完成加载,OLM 中 package-server 组件就会开始读取目录中定义好的 Operators 软件包,通过下面的命令我们可以 Watch 当前可用的 Operator package:
$ watch kubectl get packagemanifests
[...]
NAME AGE
prometheus 13m
etcd 27m同时我们可以使用下面的命令查看一个指定 Operator package 使用的默认 channel:
$ kubectl get packagemanifests etcd -o jsonpath='{.status.defaultChannel}'
alpha通过上面获取到的 Operator 软件包名称,channel 和运行 catalog 的命名空间等信息,我们可以通过创建上文介绍过的 OLM 订阅对象(Subscription)启动从指定 catalog 源中安装或升级 Operator,一个 Subscription 示例如下所示:
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: etcd-subscription
namespace: default
spec:
channel: alpha
name: etcd
source: example-manifests
sourceNamespace: default另外通过支持 gRPC 协议的命令行通讯工具 gRPCurl,我们可以在本地向指定的 catalog 服务端发送请求,从而方便地进行软件包目录信息的查看。
关于OLM是如何管理越来越多的operator就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/3874284/blog/4554300



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



