好程序员大数据学习路线之hive表的查询
1.join 查询
1、永远是小结果集驱动大结果集(小表驱动大表,小表放在左表)。 2、尽量不要使用join,但是join是难以避免的。
left join 、 left outer join 、 left semi join(左半开连接,只显示左表信息)
hive在0.8版本以后开始支持left join
left join 和 left outer join 效果差不多
hive的join中的on只能跟等值连接 "=",不能跟< >= <= !=
join:不加where过滤,叫笛卡尔积
inner join : 内连接
outer join :外链接
full outer join : 全外连接,寻找表中所有满足连接(包括where过滤)。
##创建学生测试表
CREATE TABLE student (
id INT,
name string,
sex string,
birth string,
department string,
address string
)
row format delimited fields terminated by ','
;
##从本地加载数据
load data local inpath '/root/Desktop/student.txt' into table student;
##创建学生成绩测试表
CREATE TABLE score (
stu_id INT,
c_name string,
grade string
)
row format delimited fields terminated by ','
;
##从hdfs加载数据
load data inpath '/hive.data/score.txt' into table score;
##创建学生基本信息测试表
create table stuinfo(
id int,
height double,
weight double
)
row format delimited fields terminated by ','
;
##从本地加载数据
load data local inpath '/root/Desktop/stuinfo.txt' into table stuinfo;
1.1 左连接
如果左边有数据,右边没有数据,则左边有数据的记录的对应列返回为空。
##使用左连接查询:student表为驱动表,通过id连接
select
student.name,
score.c_name,
score.grade
from student
left join score
on student.id = score.stu_id
;
1.2 左外连接
如果左边有数据,右边没有数据,则左边有数据的记录的对应列返回为空。
##使用左外连接查询:student表为驱动表,通过id连接
select
student.name,
score.c_name,
score.grade
from student
left outer join score
on student.id = score.stu_id
;
1.3 左半连接
left semi join是left join 的一种优化,并且通常用于解决exists in,写left semi join 查询时必须遵循一个限制:右表(sales) 只能在 on子句中出现,且不能在select 表达式中引用右表。
##左半连接
select
student.
from student
left semi join score on
student.id=score.id
;
##查询结果等价于
select from student where student.id not in (select stu_id from score);
1.4 右外连接
right outer join和right join差不多,不常用
如果左边没有数据,右边有数据,则右边有数据的记录对应列返回为空。
##使用右外连接查询:score表为驱动表,通过id连接
select
student.name,
score.c_name,
score.grade
from student
right outer join score
on student.id = score.stu_id
;
1.5 全外连接
##全外连接
select
student.name,
score.c_name,
score.grade
from student
full outer join score
on student.id = score.stu_id
;
##不使用join,from 后面跟多个表名使用","分割 、 inner join 、join :三种效果一样
select
student.name,
score.c_name,
score.grade
from student,score
where
student.id = score.stu_id
;
1.6 内连接
##使用内连接查询所有有考试成绩的学生的学生姓名,学科名,学科成绩,及身高
select
student.name,
score.c_name,
score.grade,
stuinfo.height
from student
inner join score
on student.id = score.stu_id
join stuinfo
on student.id = stuinfo.id
;
1.7 hive提供一个小表标识,是hive提供的一种优化机制
##小表标识:/+STREAMTABLE(表名)/
select
/+STREAMTABLE(score)/
student.name,
score.c_name,
score.grade,
stuinfo.height
from student
inner join score
on student.id = score.stu_id
join stuinfo
on student.id = stuinfo.id
;
1.8 map-side join:
如果有一个连接表小到足以放入内存, Hive就可以把较小的表放入每个mapper的内存来执行连接操作。这就叫做map连接。当有一大一小表的时候,适合用map-join。会将小表文件缓存,放到内存中,在map端和内存中的数据一一进行匹配,连接查找关系。hive-1.2.1 默认已经开启map-side join:hive.auto.convert.join=true
select
student.name,
score.c_name,
score.grade,
stuinfo.height
from student
inner join score
on student.id = score.stu_id
join stuinfo
on student.id = stuinfo.id
;
hive 0.7版本以前,需要hive提供的mapjoin()标识。来标识该join为map-side join。标识已经过时,但是写上仍然识别
select
/+MAPJOIN(student)/
student.name,
score.c_name,
score.grade,
stuinfo.height
from student
inner join score
on student.id = score.stu_id
join stuinfo
on student.id = stuinfo.id
;
hive怎么知道将多大文件缓存,配置文件中配置,下面为默认配置
<property>
<name>hive.mapjoin.smalltable.filesize</name>
<value>25000000</value>
</property>
2.group by:
GROUP BY 语句通常会和聚合函数一起使用,按照一个或者多个列对结果进行分组,然后对每个组执行聚合操作。使用group by后,查询的字段要么出现在聚合函数中,要么出现在group by 后面。
##查询学生的考试门数,及平均成绩
select
count(),
avg(grade)
from student join score
on student.id=score.stu_id
group by student.id;
3.where
SELECT语句用于选取字段,WHERE语句用于过滤条件,两者结合使用可以查找到符合过滤条件的记录。后面不能跟聚合函数或者聚合函数的结果,能跟普通的查询值或者是方法
##查询学生的考试平均成绩大于90分
select
count(),
avg(grade) avg_score
from student join score
on student.id=score.stu_id
where student.id<106
group by student.id
having avg_score>90;
4.having:
对查询出来的结果进行过滤,通常和group by搭配使用。
##查询学生的考试平均成绩大于90分的学生id及平均成绩
select
count(*),
avg(grade) avg_score
from student join score
on student.id=score.stu_id
group by student.id
having avg_score>90;
5.排序
sort by :排序,局部排序,只能保证单个reducer的结果排序。 order by: 排序,全局排序。保证整个job的结果排序。 当reducer只有1个的时候,sort by 和 order by 效果一样。建议使用sort by 通常和: desc asc .(默认升序)
##查询学生平均成绩按照降序排序
select
avg(grade) avg_score
from
student join score
on student.id=score.stu_id
group by student.id
order by avg_score desc;
设置reducer个数(等于1 或者 2):
set mapreduce.job.reduces=2
##使用order by
select
avg(grade) avg_score
from
student join score
on student.id=score.stu_id
group by student.id
order by avg_score desc;
##使用sort by
select
avg(grade) avg_score
from
student join score
on student.id=score.stu_id
group by student.id
sort by avg_score desc;
6.distribute by:
控制map中如何输出到reduce。整个hive语句转换成job默认都有该过程,如果不写,默认使用第一列的hash值来分。当只有一个reducer的时候不能体现出来。如果distribute by和sort by 一起出现的时候注意顺序问题??distribute by在前面
clusterd by : 它等价于distribute by和sort by(升序)。后面跟的字段名需要一样 clusterd by它既兼有distribute by,还兼有sort by (只能是升序)
select
id
from
student
distribute by id
sort by id;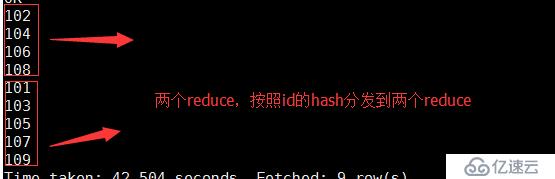
select
id
from
student
clusterd by id;
7.limit : 限制结果集的。
select
id,name
from student
limit 3;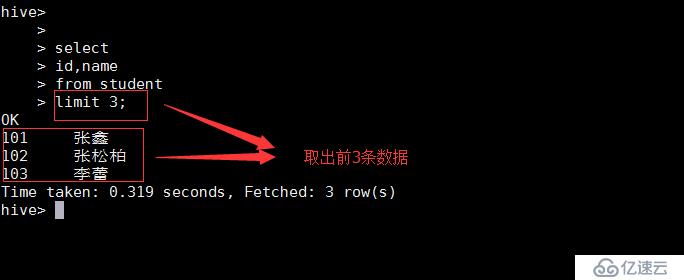
8.union all:
将两个或者多个查询的结果集合并到一起,不去重每一个结果集排序。字段数必须一致,字段类型尽量相同
##将id<108的和id>103的使用union all合并
select
id sid,
name snames
from student
where id<108
union all
select
id sid,
name sname
from student
where id>103;
9.union:
将两个或者多个查询结果集合并到一起,去重,合并后的数据排序
##将id<108的和id>103的使用union合并
select
id sid,
name sname
from student
where id<108
union
select
id sid,
name sname
from student
where id>103
order by sname;
10.子查询
子查询是内嵌在另一个SQL 语句中的SELECT 语句。Hive 对子查询的支持很有限。它只允许子查询出现在SELECT 语句的FROM 子句中。Hive支持非相关子查询,这个子查询通过IN或EXISTS语法在WHERE子句中进行查询。Hive目前暂不支持相关子查询,相关子查询的执行依赖于外部查询的数据。
##非相关子查询
select
id,name
from
student
where id
in
(select stu_id
from
score);
##相关子查询的执行依赖于外部查询的数据
select sid,uname
from
(select
id sid,
name uname
from student
) s
order by sid
##外层查询像访问表那样访问子查询的结果,这是为什么必须为子查询赋予一个别名(s)的原因。子查询中的列必须有唯一的名称,以便外层查询可以引用这些列。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





