本篇内容介绍了“RGW Bucket Shard设计与优化方法是什么”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
当bucket index所在的OSD omap过大的时候,一旦出现异常导致OSD进程崩溃,这个时候就需要进行现场"救火",用最快的速度恢复OSD服务,于是有了下面这篇文章。
先确定对应OSD的OMAP大小,这个过大会导致OSD启动的时候消耗大量时间和资源去加载levelDB数据,导致OSD无法启动(超时自杀)。特别是这一类OSD启动需要占用非常大的内存消耗,一定要注意预留好内存。(物理内存40G左右,不行用swap顶上)
root@demo:/# du -sh /var/lib/osd/ceph-214/current/omap/
22G /var/lib/osd/ceph-214/current/omap/ 2017-08-11 11:52:46.601938 7f298ae2e700 1 heartbeat_map is_healthy 'FileStore::op_tp thread 0x7f2980894700' had suicide timed out after 180
0> 2017-08-11 11:52:46.605728 7f298ae2e700 -1 common/HeartbeatMap.cc: In function 'bool ceph::HeartbeatMap::_check(ceph::heartbeat_handle_d*, const char*, time_t)' thread 7f298ae2e700 time 2017-08-11 11:52:46.601952
common/HeartbeatMap.cc: 79: FAILED assert(0 == "hit suicide timeout") #超时自杀在故障节点ceph.conf配置中加上
[osd]
debug osd = 20 #调整debug级别
[osd.214]
...
filestore_op_thread_suicide_timeout = 7000 #设置对应的osd超时,防止osd自杀观察日志
tailf /home/ceph/log/ceph-osd.214.log启动服务
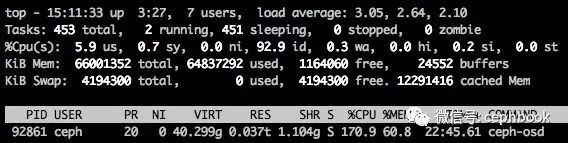
/etc/init.d/ceph start osd.214后台多启动一个top观察进程的资源消耗,目前OMAP在16G左右的OSD,需要大概37G的内存。恢复过程中OSD进程会占用非常高的内存和CPU,如下图
当观察到日志中有下面的记录就可以启动内存的释放操作(也可以放到最后去做)
2017-08-11 15:08:14.551305 7f2b3fcab900 0 osd.214 29425 load_pgs opened 181 pgs释放内存命令如下
ceph tell osd.214 heap release经过上面的操作以后osd会持续进行Omap数据的恢复,整个过程比较漫长,可以同时开 watch ceph -s 进行观察,一般恢复速率为每秒14MB,恢复时长估算公式
恢复时长(单位:秒) = OMAP总容量 / 14
注意:其中OMAP总容量是前面du命令得到的恢复过程中的日志如下
2017-08-11 15:11:25.049357 7f2a3b327700 10 osd.214 pg_epoch: 29450 pg[76.2b6( v 29425'5676261 lc 29425'5676260 (29296'5672800,29425'5676261] local-les=29449 n=4 ec=20531 les/c 29449/29447 29448/29448/28171) [70,23,214] r=2 lpr=29448 pi=20532-29447/35 luod=0'0 crt=29425'5676261 lcod 0'0 active m=1] handle_message: 0x651131200
2017-08-11 15:11:25.049380 7f2a3b327700 10 osd.214 pg_epoch: 29450 pg[76.2b6( v 29425'5676261 lc 29425'5676260 (29296'5672800,29425'5676261] local-les=29449 n=4 ec=20531 les/c 29449/29447 29448/29448/28171) [70,23,214] r=2 lpr=29448 pi=20532-29447/35 luod=0'0 crt=29425'5676261 lcod 0'0 active m=1] handle_push ObjectRecoveryInfo(6f648ab6/.dir.hxs1.55076.1.6/head//76@29425'5676261, copy_subset: [], clone_subset: {})ObjectRecoveryProgress(!first, data_recovered_to:0, data_complete:false, omap_recovered_to:0_00001948372.1948372.3, omap_complete:false)
2017-08-11 15:11:25.049400 7f2a3b327700 10 osd.214 pg_epoch: 29450 pg[76.2b6( v 29425'5676261 lc 29425'5676260 (29296'5672800,29425'5676261] local-les=29449 n=4 ec=20531 les/c 29449/29447 29448/29448/28171) [70,23,214] r=2 lpr=29448 pi=20532-29447/35 luod=0'0 crt=29425'5676261 lcod 0'0 active m=1] submit_push_data: Creating oid 6f648ab6/.dir.hxs1.55076.1.6/head//76 in the temp collection
2017-08-11 15:11:25.123153 7f2a3b327700 10 osd.214 29450 dequeue_op 0x651131200 finish
2017-08-11 15:11:25.138155 7f2b357a1700 5 osd.214 29450 tick
2017-08-11 15:11:25.138186 7f2b357a1700 20 osd.214 29450 scrub_should_schedule should run between 0 - 24 now 15 = yes
2017-08-11 15:11:25.138210 7f2b357a1700 20 osd.214 29450 scrub_should_schedule loadavg 3.34 >= max 0.5 = no, load too high
2017-08-11 15:11:25.138221 7f2b357a1700 20 osd.214 29450 sched_scrub load_is_low=0
2017-08-11 15:11:25.138223 7f2b357a1700 10 osd.214 29450 sched_scrub 76.2a9 high load at 2017-08-10 11:39:35.359828: 99109.8 < max (604800 seconds)
2017-08-11 15:11:25.138235 7f2b357a1700 20 osd.214 29450 sched_scrub done
2017-08-11 15:11:25.138237 7f2b357a1700 10 osd.214 29450 do_waiters -- start
2017-08-11 15:11:25.138239 7f2b357a1700 10 osd.214 29450 do_waiters -- finish
2017-08-11 15:11:25.163988 7f2aaef77700 20 osd.214 29450 share_map_peer 0x66b4e0260 already has epoch 29450
2017-08-11 15:11:25.164042 7f2ab077a700 20 osd.214 29450 share_map_peer 0x66b4e0260 already has epoch 29450
2017-08-11 15:11:25.268001 7f2aaef77700 20 osd.214 29450 share_map_peer 0x66b657a20 already has epoch 29450
2017-08-11 15:11:25.268075 7f2ab077a700 20 osd.214 29450 share_map_peer 0x66b657a20 already has epoch 29450当OSD对应的PG状态都恢复正常就可以进行下面的收尾操作了。
清理内存
OSD完成数据恢复以后,CPU会下降,但是内存不会释放,必须使用前面的命令去释放内存。
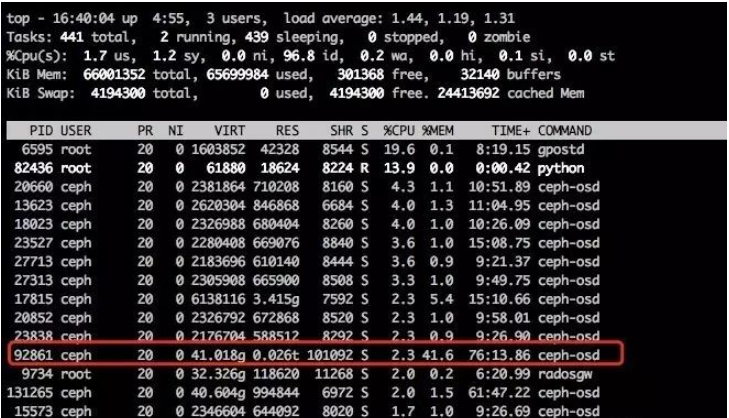
调整日志级别
ceph tell osd.214 injectargs "--debug_osd=0/5"删除ceph.conf里面之前临时新加的内容
至此bucket shard部分三篇内容就分享完了。
“RGW Bucket Shard设计与优化方法是什么”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/diluga/blog/4392188



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



