导读:数据总线DBus的总体架构中主要包括六大模块,分别是:日志抓取模块、增量转换模块、全量抽取程序、日志算子处理模块、心跳监控模块、Web管理模块。六大模块各自的功能相互连接,构成DBus的工作原理:通过读取RDBMS增量日志的方式来实时获取增量数据日志(支持全量拉取);基于Logstash,flume,filebeat等抓取工具来实时获得数据,以可视化的方式对数据进行结构化输出。本文主要介绍的是DBus中基于可视化配置的日志结构化转换实现的部分。
DBus可以对接多种log数据源,例如:Logstash、Flume、Filebeat等。上述组件都是业界比较流行的日志抓取工具,一方面便于用户和业界统一标准,方便用户技术方案的整合;另一方面也避免了无谓的重复造轮子。抓取的数据我们称为原始数据日志(raw data log),由抓取组件将其写入Kafka中,等待DBus后续处理。
用户可自定义配置日志源和目标端。同一个日志源的数据可以输出到多个目标端。每一条“日志源-目标端”线,用户可以根据自己的需要来配置相应的过滤规则。经过规则算子处理后的日志是结构化的,即:有schema约束,类似于数据库中的表。
DBus设计了丰富易用的算子,用于对数据进行定制化操作。用户对数据的处理可分为多个步骤进行,每个步骤的数据处理结果可即时查看、验证;并且可重复使用不同算子,直到转换、裁剪出自己需要的数据。
将配置好的规则算子组应用到执行引擎中,对目标日志数据进行预处理,形成结构化数据,输出到Kafka,供下游数据使用方使用。系统流程图如下所示:
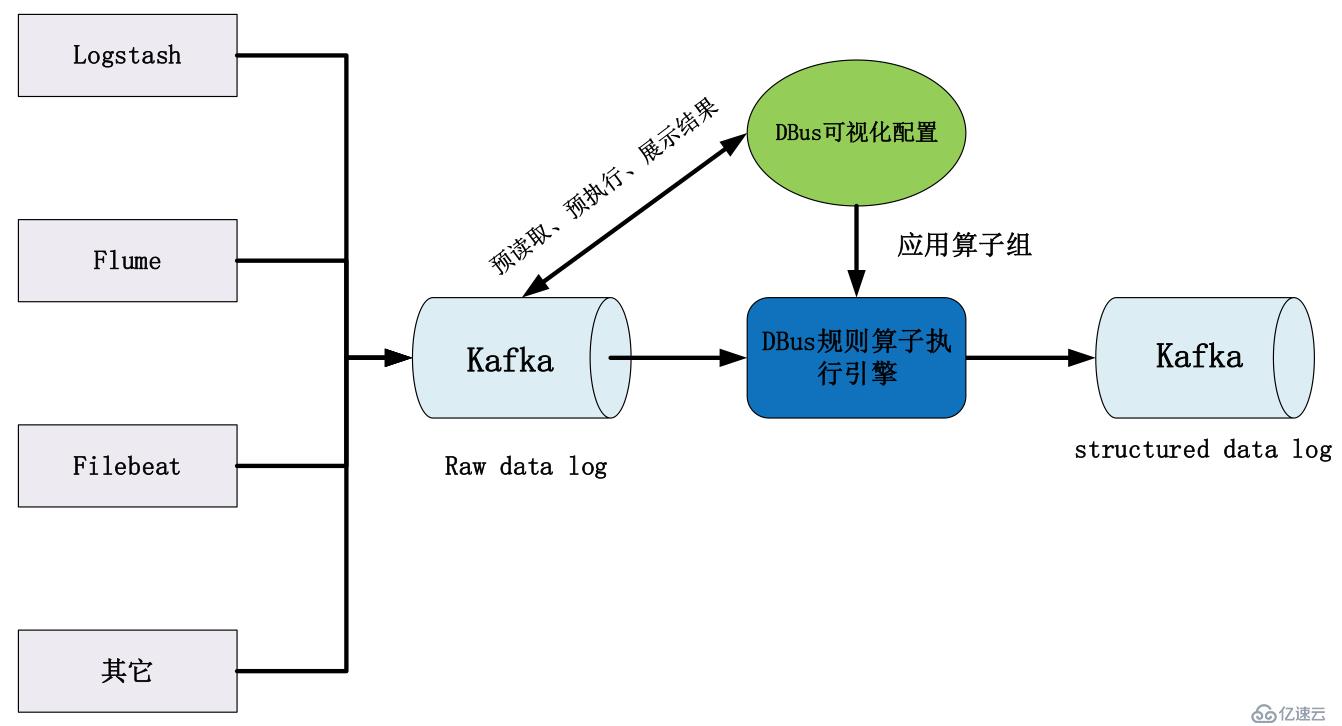
根据DBus log设计原则,同一条原始日志,可以被提取到一个或多个表中。每个表是结构化的,满足相同的schema约束。
对于任意一条原始数据日志(raw data log),它应该属于哪张表呢?
假如用户定义了若干张逻辑表(T1,T2…),用于抽取不同类型的日志,那么,每条日志需要与规则算子组进行匹配:
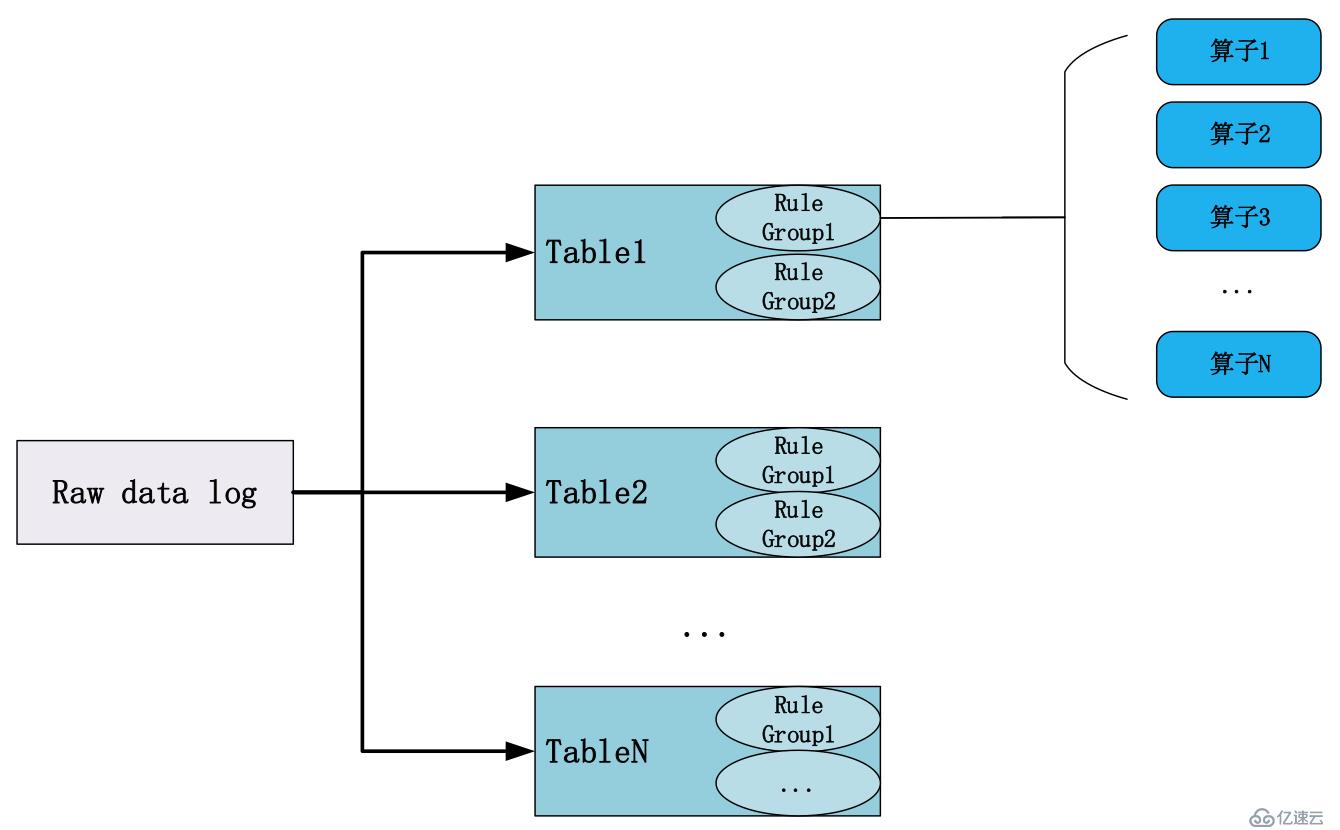
例如,对于同一条应用日志,其可能属于不止一个规则组或Table,而在我们定义的规则组或Table中,只要其满足过滤条件,该应用日志就可以被规则组提取,即保证了同一条应用日志可以同属于不同的规则组或Table。

规则算子是对数据进行过滤、加工、转换的基本单元。常见的规则算子如上图所示。
算子之间具有独立性,算子之间可以任意组合使用,从而可以实现许多复杂的、高级的功能,通过对算子进行迭代使用,最终可以实现对任意数据进行加工的目的。用户可以开发自定义算子,算子的开发非常容易,用户只要遵循基本接口原则,就可以开发任意的算子。
以DBus集群环境为例,DBus集群中有两台机器(即master-slave)部署了心跳程序,用于监控、统计、预警等,心跳程序会产生一些应用日志,这些应用日志中包含各类事件信息,假如我们想要对这些日志进行分类处理并结构化到数据库中,我们就可以采用DBus log程序对日志进行处理。
DBus可以接入多种数据源(Logstash、Flume、Filebeat等),此处以Logstash为例来说明如何接入DBus的监控和报警日志数据。
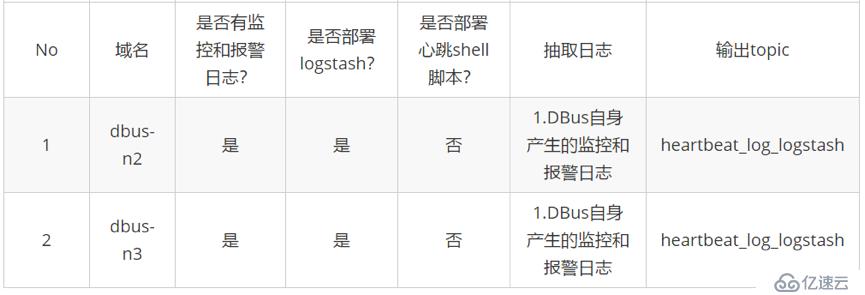
由于在dbus-n2和dbus-n3两台机器上分别存在监控和预警日志,为此我们分别在两台机器上部署了Logstash程序。心跳数据由Logstash自带的心跳插件产生,其作用是便于DBus对数据进行统计和输出,以及对源端日志抽取端(此处为Logstash)进行预警(对于Flume和Filebeat来说,因为它们没有心跳插件,所以需要额外为其定时产生心跳数据)。Logstash程序写入到Kafka中的数据中既有普通格式的数据,同时也有心跳数据。
这里不只是局限于2台部署有Logstash程序的机器,DBus对Logstash数量不做限制,比如应用日志分布在几十上百台机器上,只需要在每台机器上部署Logstash程序,并将数据统一抽取到同一个Kafka Topic中,DBus就能够对所有主机的数据进行数据处理、监控、预警、统计等。
在启动Logstash程序后,我们就可以从topic : heartbeat_log_logstash中读取数据,数据样例如下:
1)心跳数据
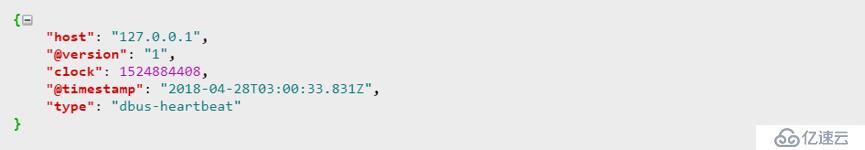
2)普通日志数据

接下来,我们只需要在DBus Web中配置相应的规则就可以对数据进行处理了。
首先新建一个逻辑表sink_info_table,该表用来抽取sink事件的日志信息,然后配置该表的规则组(一个或多个,但所有的规则组过滤后的数据需要满足相同schema特性),heartbeat_log_logstash作为原始数据topic,我们可以实时的对数据进行可视化操作配置(所见即所得,即席验证)。

1)读取原始数据日志
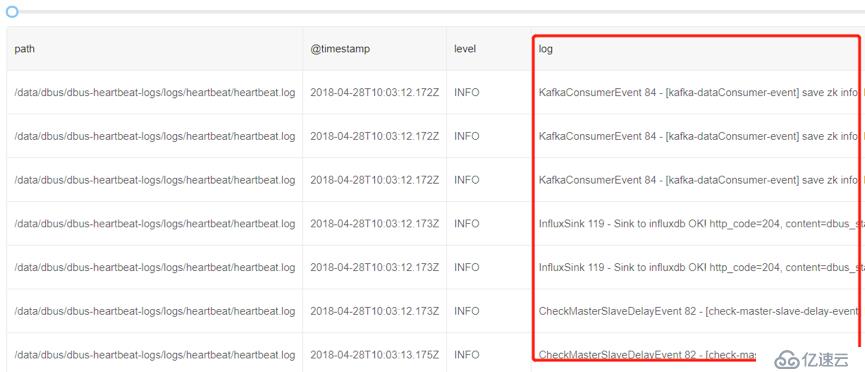
可以看到由Logstash预先提取已经包含了log4j的基本信息,例如path、@timestamp、level等。但是数据日志的详细信息在字段log中。由于不同的数据日志输出是不一样的,因此可以看到log列数据是不同的。
2)提取感兴趣的列
假如我们对timestamp、log 等原始信息感兴趣,那么可以添加一个toIndex算子,来提取这些字段:
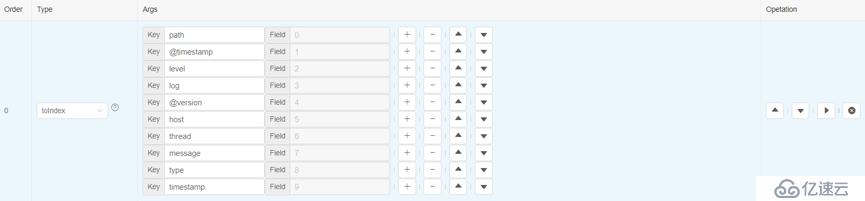
这里需要指出,我们考虑使用数组下标方式,是有原因的:
执行规则,就可以看到被提取后的字段情况:
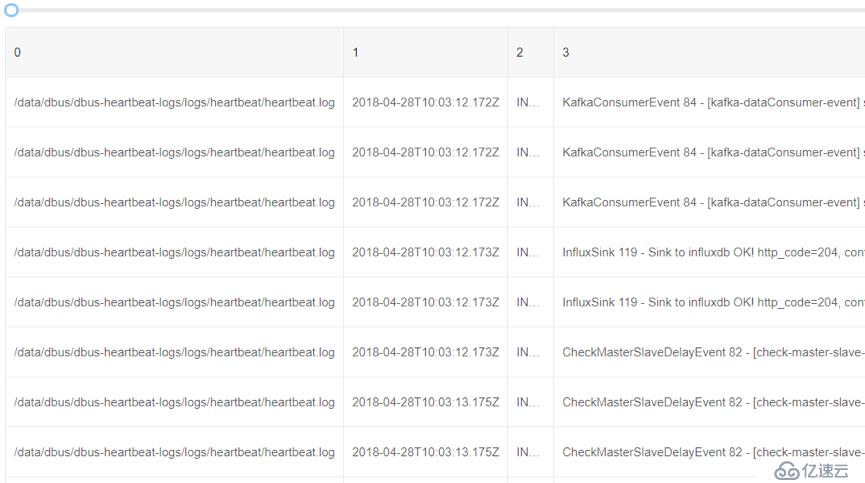
3)过滤需要的数据
在这个例子中,我们只对含有“Sink to influxdb OK!”的数据感兴趣。因此添加一个filter算子,提取第7列中包含”Sink to influxdb OK!”内容的行数据:
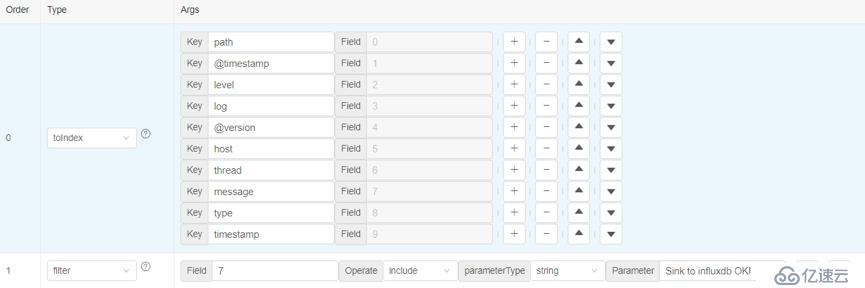
执行后,只有符合条件的日志行数据才会存在。

4)对特定列进行提取
添加一个select算子,我们对第1和3列的内容感兴趣,所以对这两列进行提取。
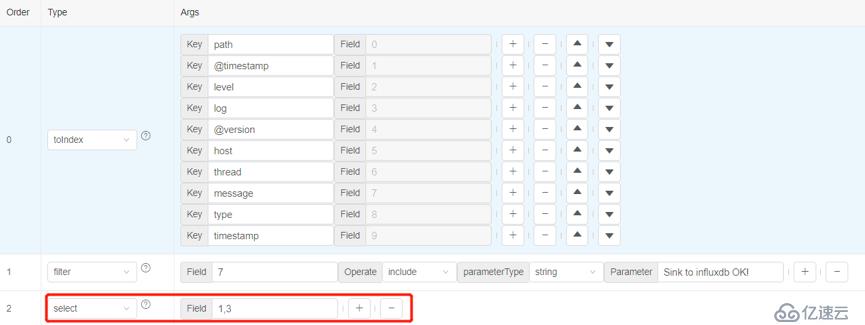
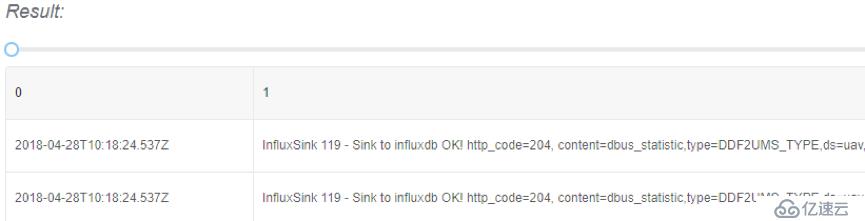
执行select算子,数据中就会只含有第1和3列了。
5)以正则表达式的方式处理数据
我们想从第1列的数据中提取符合特定正则表达式的值,使用regexExtract算子对数据进行过滤。正则表达式如下:http_code=(\d*).*type=(.*),ds=(.*),schema=(.*),table=(.*)\s.*errorCount=(\d*),用户可以写自定义的正则表达式。
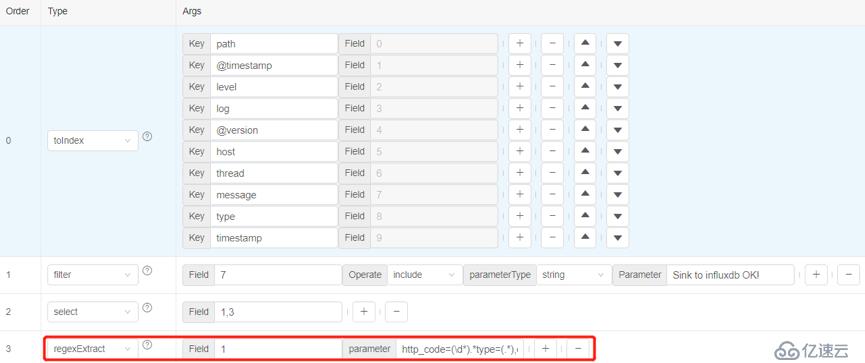
执行后,就会获取正则表达式执行后的数据。

6)选择输出列
最后我们把感兴趣的列进行输出,使用saveAs算子, 指定列名和类型,方便于保存在关系型数据库中。
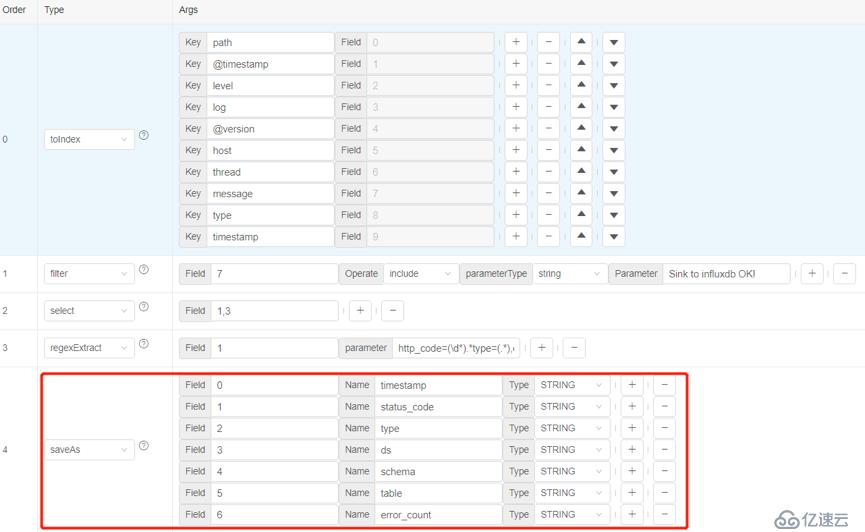
执行saveAs算子后,这就是处理好的最终输出数据样本。
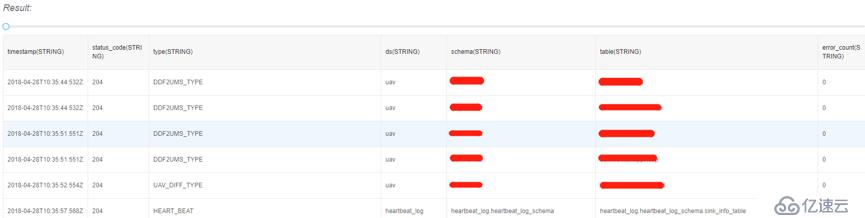
保存上一步配置好的规则组,日志数据经过DBus执行算子引擎,就可以生成相应的结构化数据了。目前根据项目实际,DBus输出的数据是UMS格式,如果不想使用UMS,可以经过简单的开发,实现定制化。
注:UMS是DBus定义并使用的、通用的数据交换格式,是标准的JSON。其中同时包含了schema和数据信息。更多UMS介绍请参考DBus开源项目主页的介绍。开源地址:https://github.com/bridata/dbus
以下是测试案例,输出的结构化UMS数据的样例:

为了便于掌握数据抽取、规则匹配、监控预警等情况,我们提供了日志数据抽取的可视化实时监控界面,如下图所示,可随时了解以下信息:
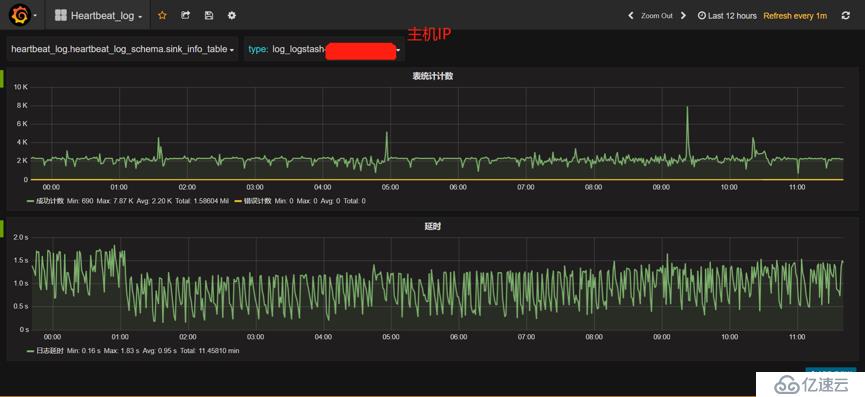
监控信息中包含了来自集群内各台主机的监控信息,以主机IP(或域名)对数据分别进行监控、统计和预警等。
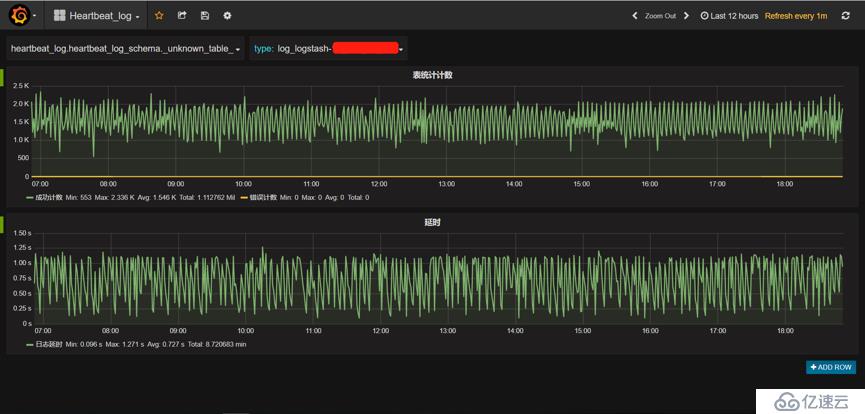
监控中还有一张表叫做_unkown_table_ 表明所有没有被匹配上的数据条数。例如:Logstash抓取的日志中有5种不同事件的日志数据,我们只捕获了其中3种事件,其它没有被匹配上的数据,全部在_unkown_table_计数中。
DBus同样可以接入Flume、Filebeat、UMS等数据源,只需要稍作配置,就可以实现类似于对Logstash数据源同样的处理效果,更多关于DBus对log的处理说明,请参考:
https://bridata.github.io/DBus/install-logstash-source.html
https://bridata.github.io/DBus/install-flume-source.html
应用日志经过DBus处理后,将原始数据日志转换为了结构化数据,输出到Kafka中提供给下游数据使用方进行使用,比如通过Wormhole将数据落入数据库等。具体如何将DBus与Wormhole结合起来使用,请参考:如何设计实时数据平台(技术篇)。
作者:仲振林
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



