这篇文章给大家分享的是有关windows安装spark及PyCharm IDEA调试TopN的示例分析的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
安装spark第一步就是安装jdk(无论windows还是linux),spark执行依赖jdk。在oracle官网上下载jdk,这里我选择的是8u74 windows x64版本,你也可以根据自己的需求下载,jdk的安装在此不表,无非就是下一步,选安装路径什么的。
在Apache Spark™官方网站下载spark,选择spark-1.6.0-bin-hadoop2.6.tgz。
添加spark环境变量,在PATH后面追加:
%SPARK_HOME%\bin
%SPARK_HOME%\sbin
windows 环境下的spark搭建完毕!!!
注意此处有坑:
Failed to locate the winutils binary in the hadoop binary path java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
spark虽然支持standalone模式,并且不依赖hadoop。但是在windows环境下还是需要hadoop的这个winutils.exe。因此需要下载2.6版本匹配的winutils.exe. 可以google "hadoop.dll 2.6" 或在此下载(hadoop dll winutils.exe,GitHub各种版本都有), 将下载后的文件覆盖至hadoop的bin目录(没有的话需要建个目录,并设置相应hadoop环境HADOOP_HOME及PATH环境变量)。
spark支持scala、python和java,由于对python的好感多于scala,因此开发环境是Python。
下面开始搭建python环境:
2.7或3.5均可,安装过程在此不表,安装完成后在环境变量里添加PYTHONPATH,这一步很重要:
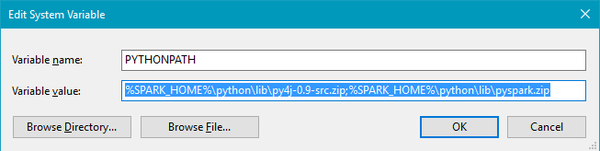
如果配置正确,打开python自带的IDE,输入以下代码,然后等待连接成功的消息即可:
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("MY First App")
sc = SparkContext(conf = conf)也可以手动启动测试下:
spark-class.cmd org.apache.spark.deploy.master.Master spark-class.cmd org.apache.spark.deploy.worker.Worker spark://localhost:7077
# coding=utf-8
# 测试utf-8编码
from __future__ import division
import decimal
from pyspark import SparkConf, SparkContext, StorageLevel
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
conf = SparkConf().setMaster("local").setAppName("CSDN_PASSWD_Top10")
sc = SparkContext(conf=conf)
file_rdd = sc.textFile("H:\mysql\csdn_database\www.csdn.net.sql")
passwds = file_rdd.map(lambda line: line.split("#")[1].strip()).map(lambda passwd: (passwd, 1)).persist(
storageLevel=StorageLevel.MEMORY_AND_DISK_SER)
passwd_nums = passwds.count()
top10_passwd = passwds.reduceByKey(lambda a, b: a + b).sortBy(lambda item: item[1], ascending=False).take(10)
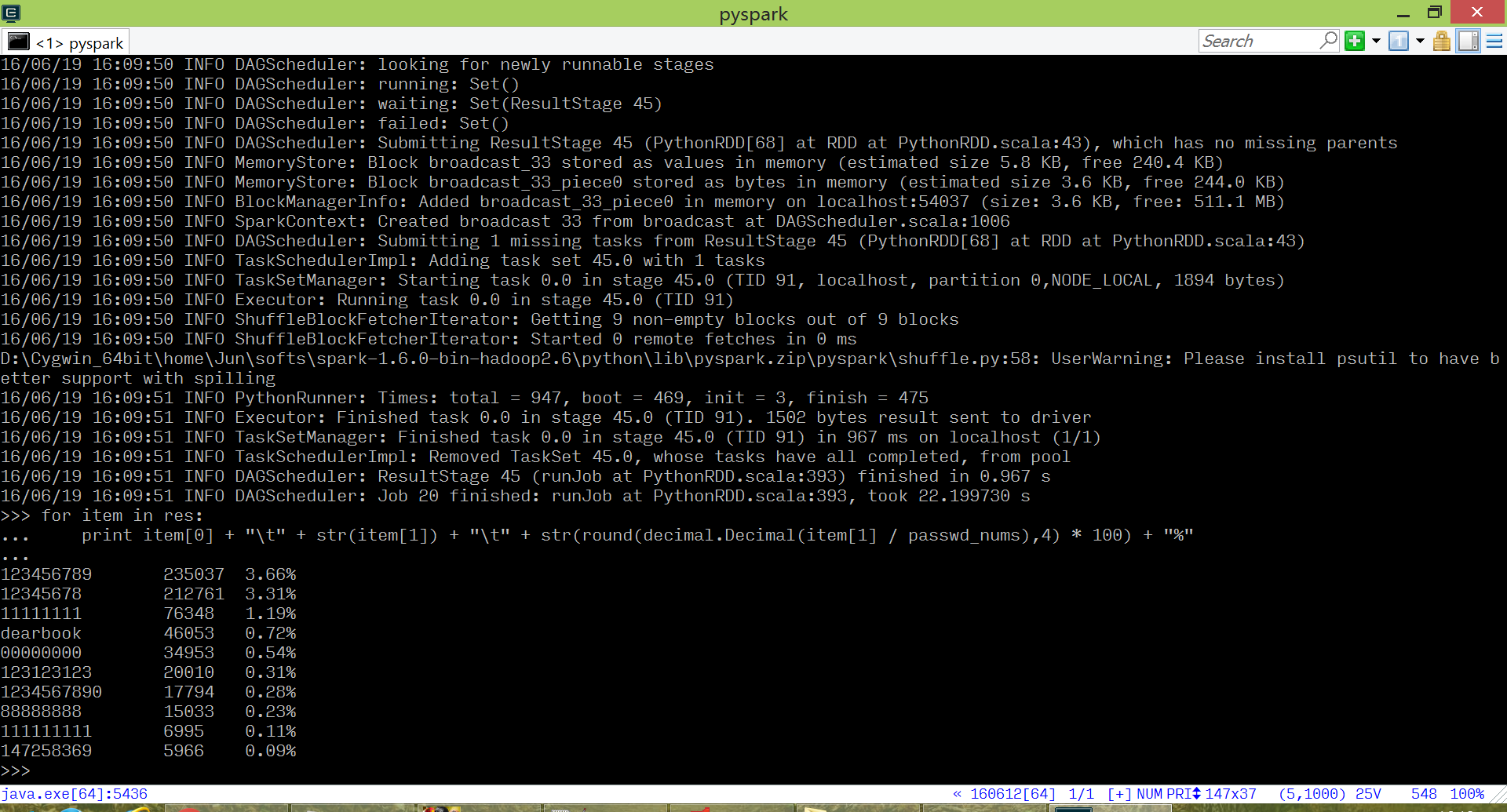
for item in top10_passwd:
print item[0] + "\t">
代码如下:
C:\Users\username>spark-shell
scala> val textFile = spark.read.textFile("C:\\Users\\username\\Desktop\\parse_slow_log.py")
textFile: org.apache.spark.sql.Dataset[String] = [value: string]
scala> textFile.count()
res0: Long = 156
scala> textFile.first()
res1: String = # encoding: utf-8
scala> val linesWithSpark = textFile.filter(line => line.contains("Spark"))
linesWithSpark: org.apache.spark.sql.Dataset[String] = [value: string]
scala> textFile.filter(line => line.contains("Spark")).count()
res2: Long = 0
scala> textFile.map(line => line.split(" ").size).reduce((a, b) => if (a > b) a else b)
res3: Int = 27
scala> val wordCounts = textFile.flatMap(line => line.split(" ")).groupByKey(identity).count()
wordCounts: org.apache.spark.sql.Dataset[(String, Long)] = [value: string, count(1): bigint]
scala> wordCounts.collect()
res4: Array[(String, Long)] = Array((self.slowlog,1), (import,3), (False,,1), (file_name,,1), (flag_word,3), (MySQL,1), (else,1), (*,2), (slowlog,1), (default=script_path),1), (0,4), ("",2), (-d,1), (__auther,1), (for,5...
scala感谢各位的阅读!关于“windows安装spark及PyCharm IDEA调试TopN的示例分析”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





