这篇文章主要讲解了“如何用Storm来写一个Crawler的工具”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“如何用Storm来写一个Crawler的工具”吧!
阅读背景:
1: 您可能需要了解基本的爬虫知识。
2:您可能需要对HTTP协议有初步了解。
3:您可能需要对Storm计算的逻辑有初步的了解。
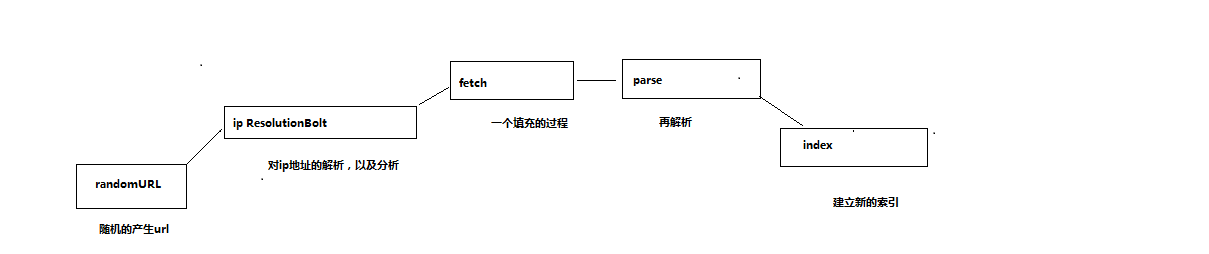
package com.digitalpebble.storm.crawler;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
import com.digitalpebble.storm.crawler.bolt.IPResolutionBolt;
import com.digitalpebble.storm.crawler.bolt.indexing.IndexerBolt;
import com.digitalpebble.storm.crawler.bolt.parser.ParserBolt;
import com.digitalpebble.storm.crawler.fetcher.Fetcher;
import com.digitalpebble.storm.crawler.spout.RandomURLSpout;
/**
* 整体爬虫引擎的topology
*/
public class CrawlTopology {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new RandomURLSpout());
builder.setBolt("ip", new IPResolutionBolt()).shuffleGrouping("spout");
builder.setBolt("fetch", new Fetcher()).fieldsGrouping("ip",
new Fields("ip"));
builder.setBolt("parse", new ParserBolt()).shuffleGrouping("fetch");
builder.setBolt("index", new IndexerBolt()).shuffleGrouping("parse");
Config conf = new Config();
conf.setDebug(true);
conf.registerMetricsConsumer(DebugMetricConsumer.class);
if (args != null && args.length > 0) {
conf.setNumWorkers(3);
StormSubmitter.submitTopology(args[0], conf,
builder.createTopology());
} else {
conf.setMaxTaskParallelism(3);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("crawl", conf, builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}
}
感谢各位的阅读,以上就是“如何用Storm来写一个Crawler的工具”的内容了,经过本文的学习后,相信大家对如何用Storm来写一个Crawler的工具这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/infiniteSpace/blog/299689



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



